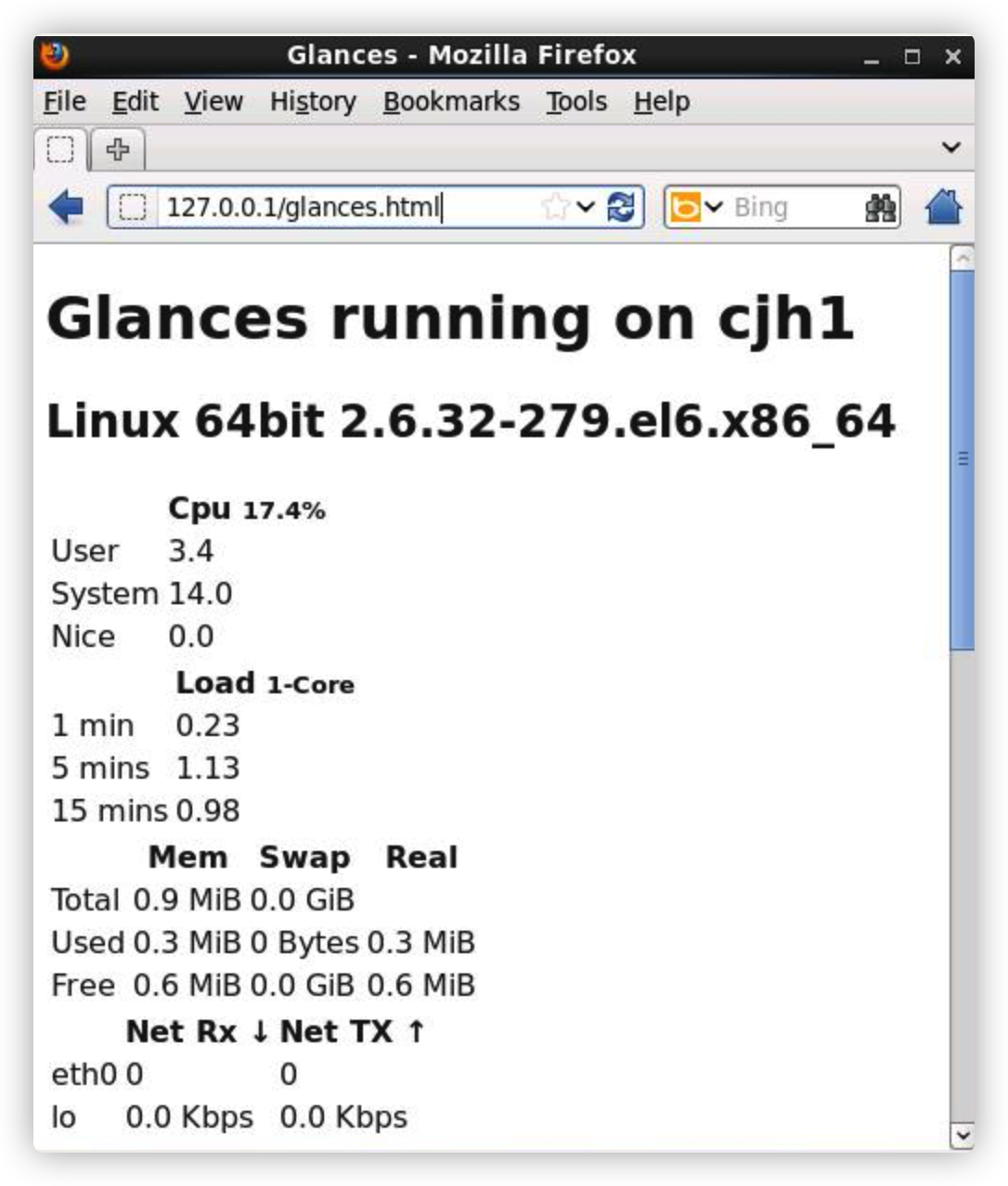
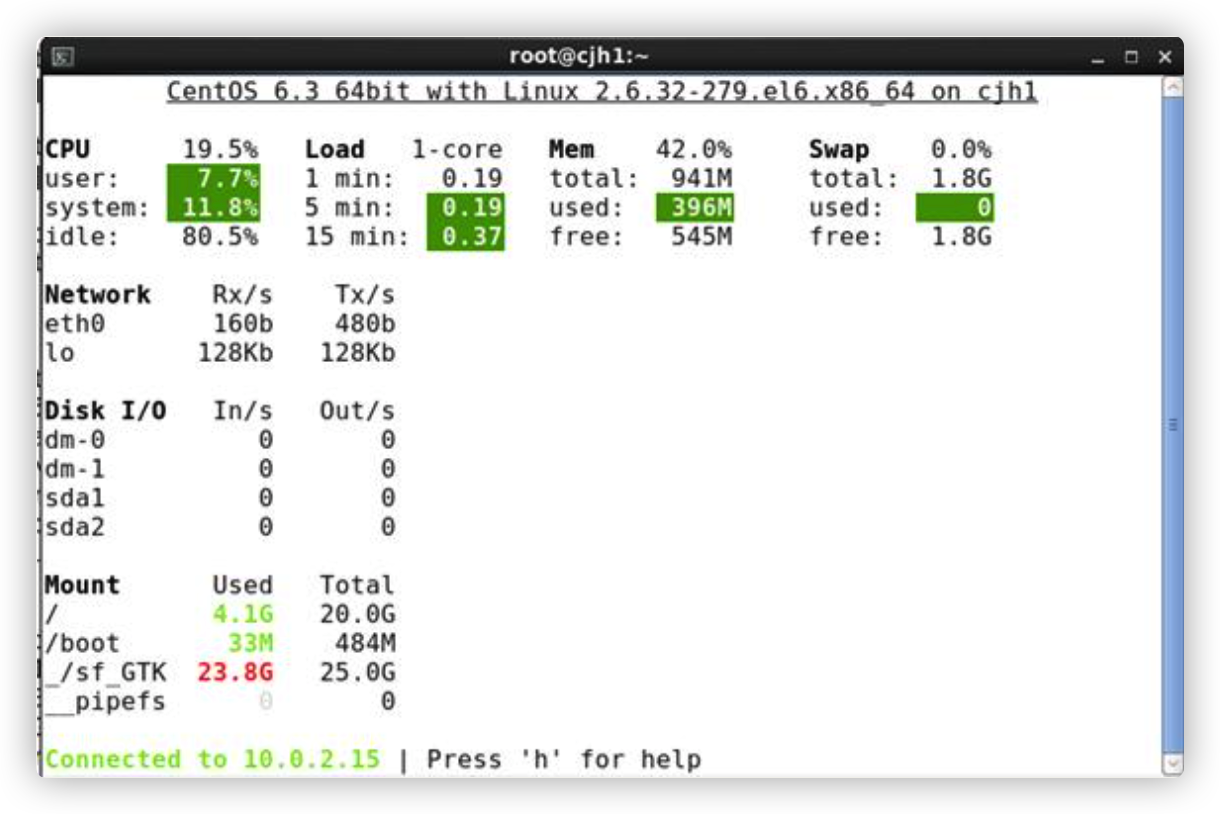
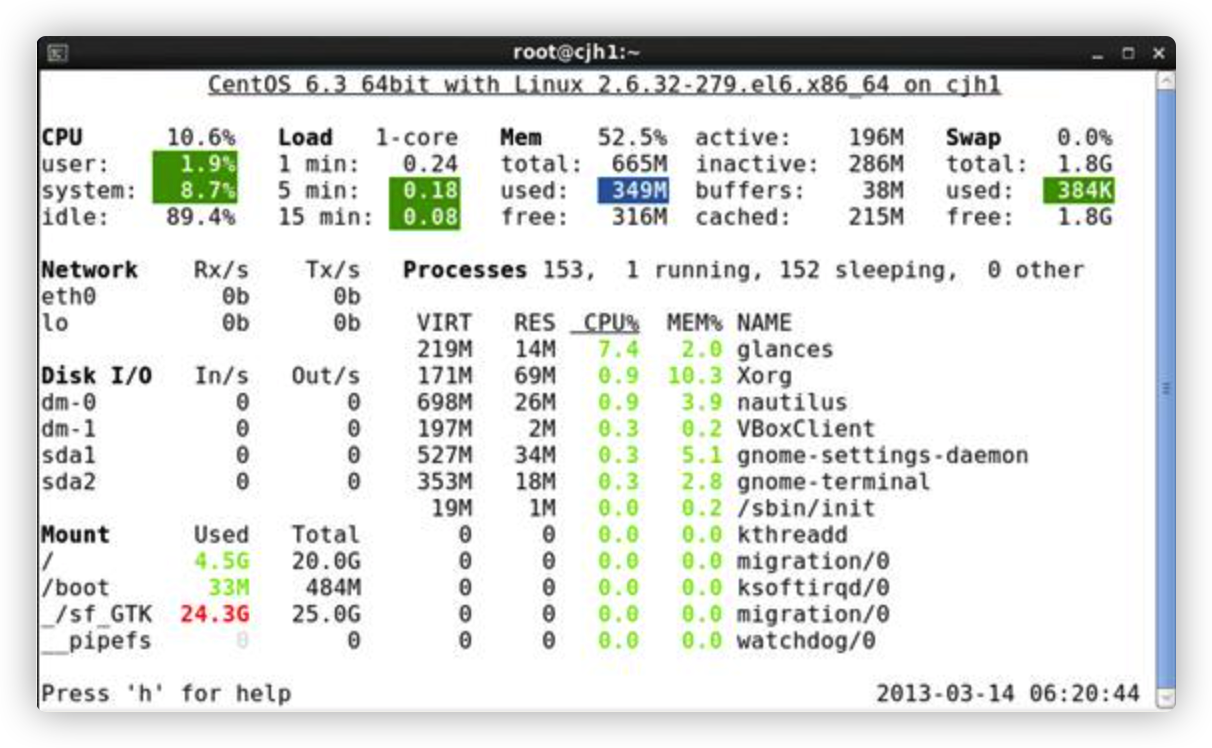
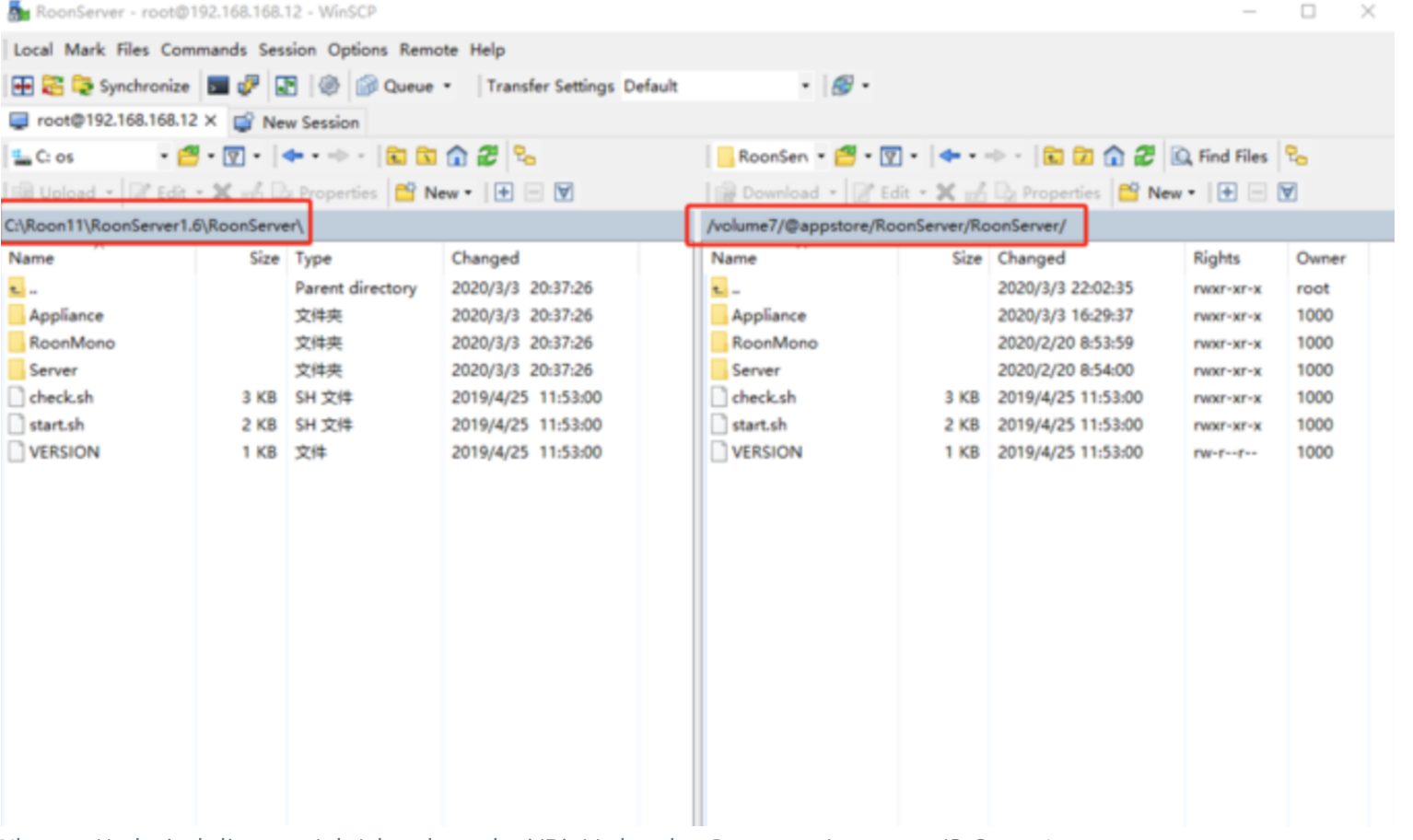
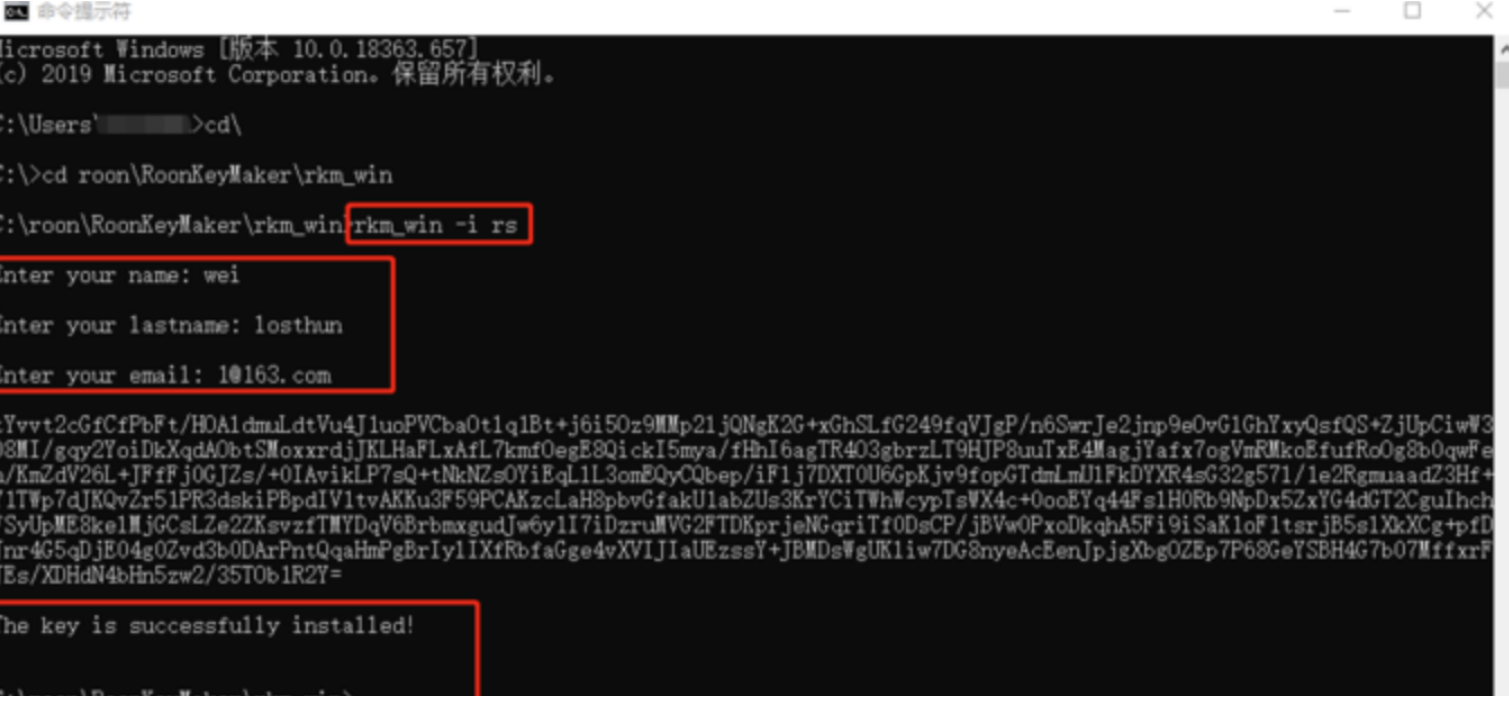
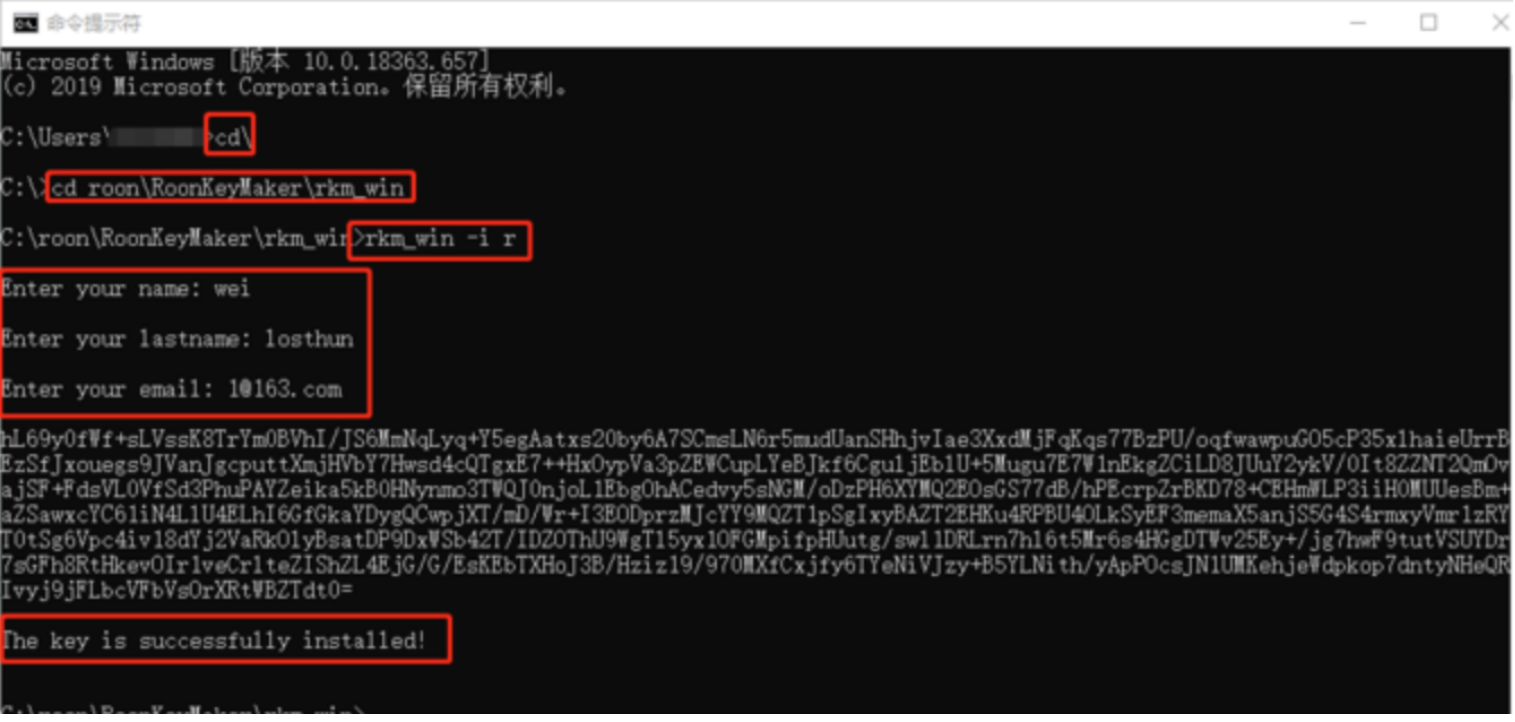
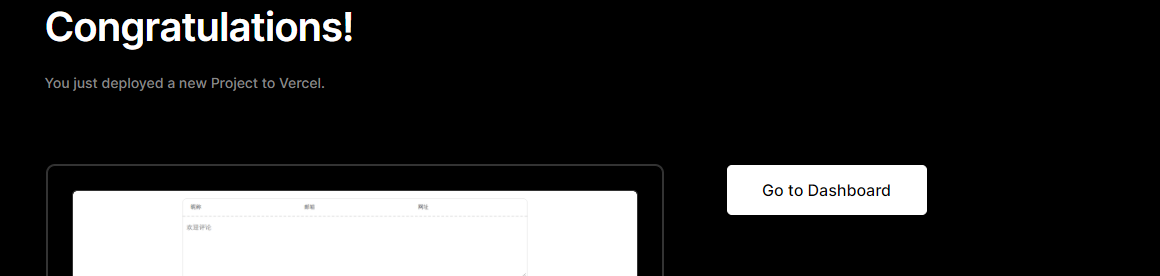
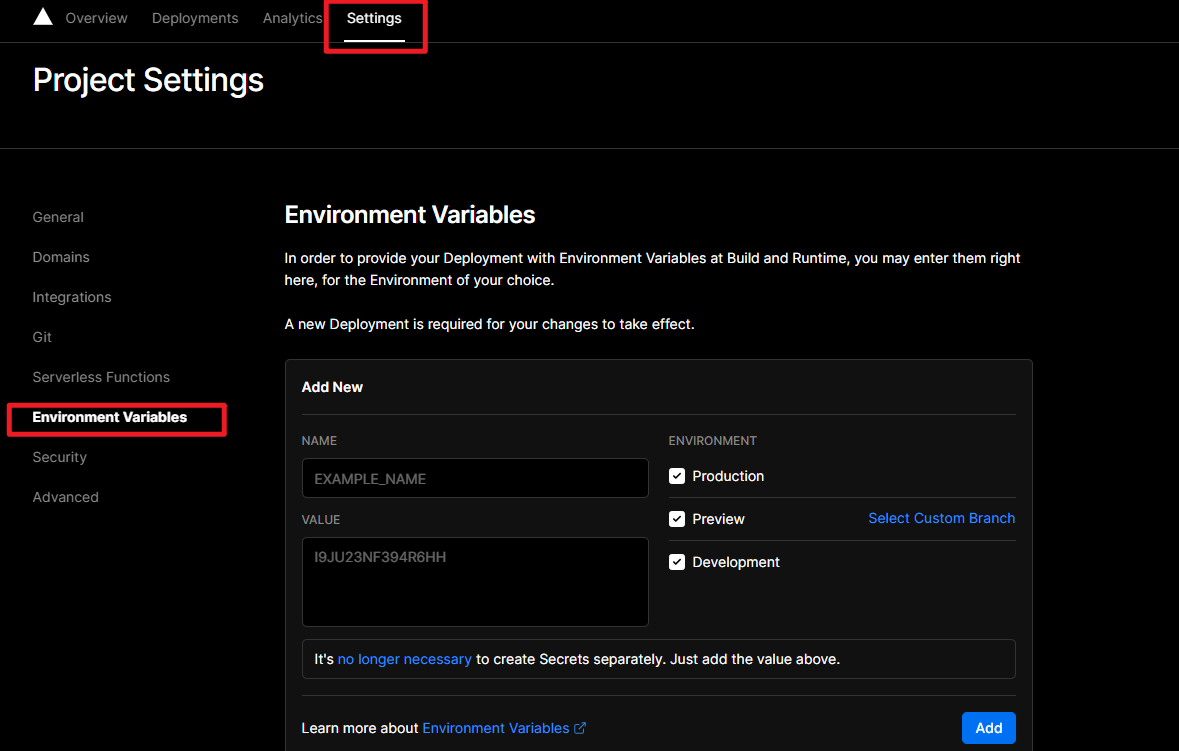
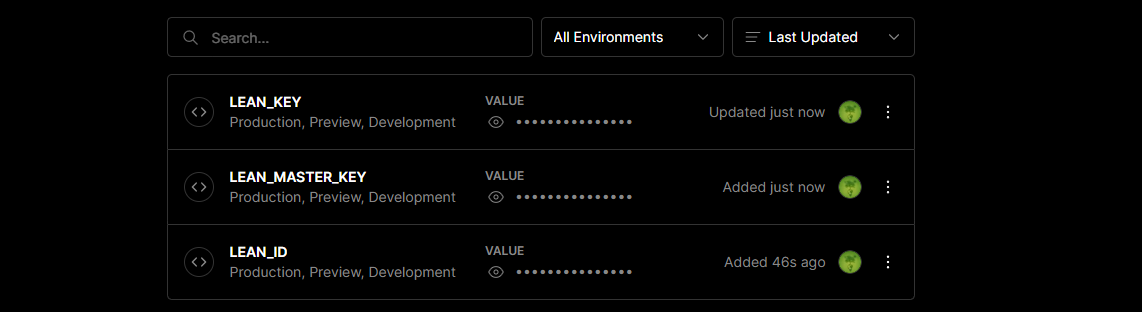
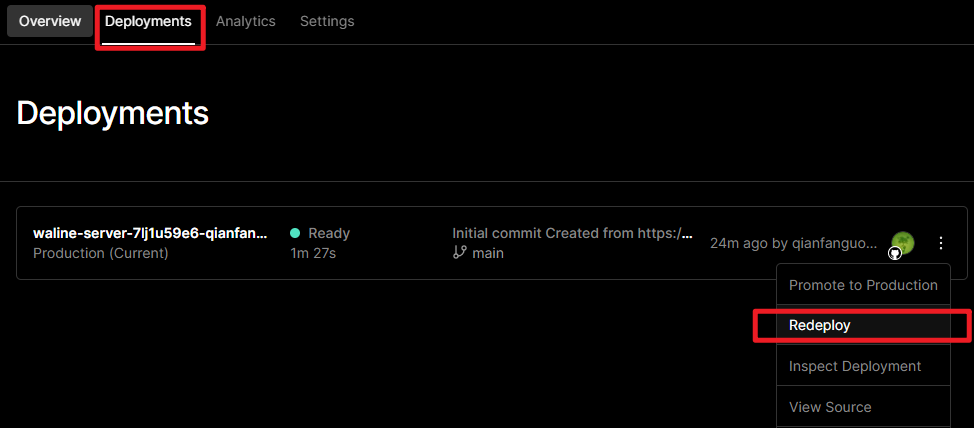
glances 工具可以在用户的终端上实时显示重要的系统信息,并动态地对其进行更新。这个高效的工具可以工作于任何终端屏幕。另外它并不会消耗大量的 CPU 资源,通常低于百分之二。glances 在屏幕上对数据进行显示,并且每隔两秒钟对其进行更新。您也可以自己将这个时间间隔更改为更长或更短的数值。glances 工具还可以将相同的数据捕获到一个文件,便于以后对报告进行分析和绘制图形。输出文件可以是电子表格的格式 (.csv) 或者 html 格式。
如 果既想获得 RHEL 的高质量、高性能、高可靠性,又需要方便易用(关键是免费)的软件包更新功能,那么 Fedora Project 推出的 EPEL(Extra Packages for Enterprise Linux ,http://fedoraproject.org/wiki/EPEL)正好适合你。它是由 Fedora 社区打造,为 RHEL 及衍生发行版如 CentOS、Scientific Linux 等提供高质量软件包的项目。装上了 EPEL,就像在 Fedora 上一样,可以通过 yum install package-name,随意安装软件。安装使用 EPEL 非常简单:
1 2 3 4 5 6 7 8 9 10
#wget http://ftp.riken.jp/Linux/fedora/epel/RPM-GPG-KEY-EPEL-6 #rpm --import RPM-GPG-KEY-EPEL-6 #rm -f RPM-GPG-KEY-EPEL-6 #vi /etc/yum.repos.d/epel.repo # create new [epel] name=EPEL RPM Repository for Red Hat Enterprise Linux baseurl=http://ftp.riken.jp/Linux/fedora/epel/6/$basearch/ gpgcheck=1 enabled=0
h : 显示帮助信息 q : 离开程序退出 c :按照 CPU 实时负载对系统进程进行排序 m :按照内存使用状况对系统进程排序 i:按照 I/O 使用状况对系统进程排序 p: 按照进程名称排序 d : 显示磁盘读写状况 w : 删除日志文件 l :显示日志 s: 显示传感器信息 f : 显示系统信息 1 :轮流显示每个 CPU 内核的使用情况(次选项仅仅使用在多核 CPU 系统)
glances 的高级应用
glances 的结果输出方法
让 glances 输出 HTML 格式文件,首先安装相关软件包
1 2
# pip-Python install Jinja2 # glances -o HTML -f /var/www/html
熟练使用命令行是一种常常被忽视,或被认为难以掌握的技能,但实际上,它会提高你作为工程师的灵活性以及生产力。本文是一份我在 Linux 上工作时,发现的一些命令行使用技巧的摘要。有些技巧非常基础,而另一些则相当复杂,甚至晦涩难懂。这篇文章并不长,但当你能够熟练掌握这里列出的所有技巧时,你就学会了很多关于命令行的东西了。
当变量和文件名中包含空格的时候要格外小心。Bash 变量要用引号括起来,比如 "$FOO"。尽量使用 -0 或 -print0 选项以便用 NULL 来分隔文件名,例如 locate -0 pattern | xargs -0 ls -al 或 find / -print0 -type d | xargs -0 ls -al。如果 for 循环中循环访问的文件名含有空字符(空格、tab 等字符),只需用 IFS=$'\n' 把内部字段分隔符设为换行符。
在 Bash 脚本中,使用 set -x 去调试输出(或者使用它的变体 set -v,它会记录原始输入,包括多余的参数和注释)。尽可能地使用严格模式:使用 set -e 令脚本在发生错误时退出而不是继续运行;使用 set -u 来检查是否使用了未赋值的变量;试试 set -o pipefail,它可以监测管道中的错误。当牵扯到很多脚本时,使用 trap 来检测 ERR 和 EXIT。一个好的习惯是在脚本文件开头这样写,这会使它能够检测一些错误,并在错误发生时中断程序并输出信息:
1 2
set -euo pipefail trap"echo 'error: Script failed: see failed command above'" ERR
注意到语言设置(中文或英文等)对许多命令行工具有一些微妙的影响,比如排序的顺序和性能。大多数 Linux 的安装过程会将 LANG 或其他有关的变量设置为符合本地的设置。要意识到当你改变语言设置时,排序的结果可能会改变。明白国际化可能会使 sort 或其他命令运行效率下降许多倍。某些情况下(例如集合运算)你可以放心的使用 export LC_ALL=C 来忽略掉国际化并按照字节来判断顺序。
你可以单独指定某一条命令的环境,只需在调用时把环境变量设定放在命令的前面,例如 TZ=Pacific/Fiji date 可以获取斐济的时间。
注意 OS X 系统是基于 BSD UNIX 的,许多命令(例如 ps,ls,tail,awk,sed)都和 Linux 中有微妙的不同( Linux 很大程度上受到了 System V-style Unix 和 GNU 工具影响)。你可以通过标题为 “BSD General Commands Manual” 的 man 页面发现这些不同。在有些情况下 GNU 版本的命令也可能被安装(例如 gawk 和 gsed 对应 GNU 中的 awk 和 sed )。如果要写跨平台的 Bash 脚本,避免使用这些命令(例如,考虑 Python 或者 perl )或者经过仔细的测试。
用 sw_vers 获取 OS X 的版本信息。
仅限 Windows 系统
以下是仅限于 Windows 系统的技巧。
在 Winodws 下获取 Unix 工具
可以安装 Cygwin 允许你在 Microsoft Windows 中体验 Unix shell 的威力。这样的话,本文中介绍的大多数内容都将适用。
在 Windows 10 上,你可以使用 Bash on Ubuntu on Windows,它提供了一个熟悉的 Bash 环境,包含了不少 Unix 命令行工具。好处是它允许 Linux 上编写的程序在 Windows 上运行,而另一方面,Windows 上编写的程序却无法在 Bash 命令行中运行。
如果你在 Windows 上主要想用 GNU 开发者工具(例如 GCC),可以考虑 MinGW 以及它的 MSYS 包,这个包提供了例如 bash,gawk,make 和 grep 的工具。MSYS 并不包含所有可以与 Cygwin 媲美的特性。当制作 Unix 工具的原生 Windows 端口时 MinGW 将特别地有用。
另一个在 Windows 下实现接近 Unix 环境外观效果的选项是 Cash。注意在此环境下只有很少的 Unix 命令和命令行可用。
实用 Windows 命令行工具
可以使用 wmic 在命令行环境下给大部分 Windows 系统管理任务编写脚本以及执行这些任务。
Windows 实用的原生命令行网络工具包括 ping,ipconfig,tracert,和 netstat。
#!/bin/bash PRE_IFS=$IFS IFS=$'\n' currentdir=`pwd` echo$currentdir distdir=$1 echo$distdir filename=$(ls$distdir) for file in$filename do echo$file if [ -f $distdir/$file ] then ln$distdir/$file$currentdir/$file fi if [ -d $distdir/$file ] then cd$currentdir mkdir$currentdir/$file cd$currentdir/$file bash /usr/local/bin/${0##*/}$distdir/$file fi done # 任务执行完毕,把IFS还原回默认值 IFS=$PRE_IFS