hexo-start
摘要内容……
摘要内容……
经常刷 LeetCode 的读者肯定知道鼎鼎有名的 twoSum 问题,我们的旧文 Two Sum 问题的核心思想 对 twoSum 的几个变种做了解析。
但是除了 twoSum 问题,LeetCode 上面还有 3Sum,4Sum 问题,我估计以后出个 5Sum,6Sum 也不是不可能。
那么,对于这种问题有没有什么好办法用套路解决呢?本文就由浅入深,层层推进,用一个函数来解决所有 nSum 类型的问题。
[leetcode1](1. 两数之和 - 力扣(LeetCode) (leetcode-cn.com))
力扣上的 twoSum 问题,题目要求返回的是索引,这里我来编一道 twoSum 题目,不要返回索引,返回元素的值:
如果假设输入一个数组 nums 和一个目标和 target,请你返回 nums 中能够凑出 target 的两个元素的值,比如输入 nums = [5,3,1,6], target = 9,那么算法返回两个元素 [3,6]。可以假设只有且仅有一对儿元素可以凑出 target。
我们可以先对 nums 排序,然后利用前文「双指针技巧汇总」写过的左右双指针技巧,从两端相向而行就行了:
1 | vector<int> twoSum(vector<int>& nums, int target) { |
这样就可以解决这个问题,不过我们要继续魔改题目,把这个题目变得更泛化,更困难一点:
nums 中可能有多对儿元素之和都等于 target,请你的算法返回所有和为 target 的元素对儿,其中不能出现重复。
函数签名如下:
1 | vector<vector<int>> twoSumTarget(vector<int>& nums, int target); |
比如说输入为 nums = [1,3,1,2,2,3], target = 4,那么算法返回的结果就是:[[1,3],[2,2]]。
对于修改后的问题,关键难点是现在可能有多个和为 target 的数对儿,还不能重复,比如上述例子中 [1,3] 和 [3,1] 就算重复,只能算一次。
首先,基本思路肯定还是排序加双指针:
1 | vector<vector<int>> twoSumTarget(vector<int>& nums, int target { |
但是,这样实现会造成重复的结果,比如说 nums = [1,1,1,2,2,3,3], target = 4,得到的结果中 [1,3] 肯定会重复。
出问题的地方在于 sum == target 条件的 if 分支,当给 res 加入一次结果后,lo 和 hi 不应该改变 1 的同时,还应该跳过所有重复的元素:
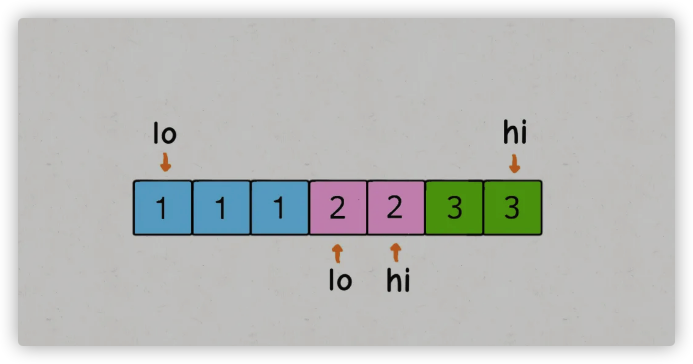
1 | while (lo < hi) { |
这样就可以保证一个答案只被添加一次,重复的结果都会被跳过,可以得到正确的答案。不过,受这个思路的启发,其实前两个 if 分支也是可以做一点效率优化,跳过相同的元素:
1 | vector<vector<int>> twoSumTarget(vector<int>& nums, int target) { |
这样,一个通用化的 twoSum 函数就写出来了,请确保你理解了该算法的逻辑,我们后面解决 3Sum 和 4Sum 的时候会复用这个函数。
这个函数的时间复杂度非常容易看出来,双指针操作的部分虽然有那么多 while 循环,但是时间复杂度还是 O(N),而排序的时间复杂度是 O(NlogN),所以这个函数的时间复杂度是 O(NlogN)。
这是力扣第 15 题「三数之和」:
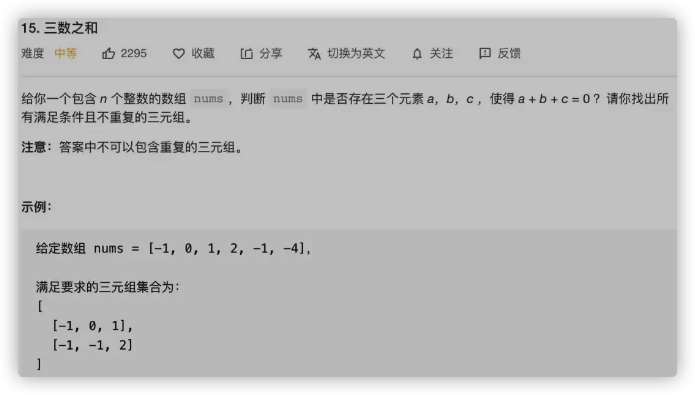
题目就是让我们找 nums 中和为 0 的三个元素,返回所有可能的三元组(triple),函数签名如下:
1 | vector<vector<int>> threeSum(vector<int>& nums); |
这样,我们再泛化一下题目,不要光和为 0 的三元组了,计算和为 target 的三元组吧,同上面的 twoSum 一样,也不允许重复的结果:
1 | vector<vector<int>> threeSum(vector<int>& nums) { |
这个问题怎么解决呢?很简单,穷举呗。现在我们想找和为 target 的三个数字,那么对于第一个数字,可能是什么?nums 中的每一个元素 nums[i] 都有可能!
那么,确定了第一个数字之后,剩下的两个数字可以是什么呢?其实就是和为 target - nums[i] 的两个数字呗,那不就是 twoSum 函数解决的问题么🤔
可以直接写代码了,需要把 twoSum 函数稍作修改即可复用:
1 | /* 从 nums[start] 开始,计算有序数组 |
需要注意的是,类似 twoSum,3Sum 的结果也可能重复,比如输入是 nums = [1,1,1,2,3], target = 6,结果就会重复。
关键点在于,不能让第一个数重复,至于后面的两个数,我们复用的 twoSum 函数会保证它们不重复。所以代码中必须用一个 while 循环来保证 3Sum 中第一个元素不重复。
至此,3Sum 问题就解决了,时间复杂度不难算,排序的复杂度为 O(NlogN),twoSumTarget 函数中的双指针操作为 O(N),threeSumTarget 函数在 for 循环中调用 twoSumTarget 所以总的时间复杂度就是 O(NlogN + N^2) = O(N^2)。
这是力扣第 18 题「四数之和」:

函数签名如下:
1 | vector<vector<int>> fourSum(vector<int>& nums, int target); |
都到这份上了,4Sum 完全就可以用相同的思路:穷举第一个数字,然后调用 3Sum 函数计算剩下三个数,最后组合出和为 target 的四元组。
1 | vector<vector<int>> fourSum(vector<int>& nums, int target) { |
这样,按照相同的套路,4Sum 问题就解决了,时间复杂度的分析和之前类似,for 循环中调用了 threeSumTarget 函数,所以总的时间复杂度就是 O(N^3)。
在 LeetCode 上,4Sum 就到头了,但是回想刚才写 3Sum 和 4Sum 的过程,实际上是遵循相同的模式的。我相信你只要稍微修改一下 4Sum 的函数就可以复用并解决 5Sum 问题,然后解决 6Sum 问题……
那么,如果我让你求 100Sum 问题,怎么办呢?其实我们可以观察上面这些解法,统一出一个 nSum 函数:
1 | /* 注意:调用这个函数之前一定要先给 nums 排序 */ |
嗯,看起来很长,实际上就是把之前的题目解法合并起来了,n == 2 时是 twoSum 的双指针解法,n > 2 时就是穷举第一个数字,然后递归调用计算 (n-1)Sum,组装答案。
需要注意的是,调用这个 nSum 函数之前一定要先给 nums 数组排序,因为 nSum 是一个递归函数,如果在 nSum 函数里调用排序函数,那么每次递归都会进行没有必要的排序,效率会非常低。
比如说现在我们写 LeetCode 上的 4Sum 问题:
1 | vector<vector<int>> fourSum(vector<int>& nums, int target) { |
再比如 LeetCode 的 3Sum 问题,找 target == 0 的三元组:
1 | vector<vector<int>> threeSum(vector<int>& nums) { |
那么,如果让你计算 100Sum 问题,直接调用这个函数就完事儿了。
在使用梯子时,Clash Verge 的自定义规则可能时常不好用,经常导致 Steam 连接到国外服务器,导致国内下载很慢 / 耗流量。
本文使用 Clash Verge 2.0.3 来编写 Steam 规则。
我们可以通过 Clash 的 全局扩展脚本(通常在配置文件中名为 rule-providers 和 rules 部分)来精细控制 Steam 的走代理行为,避免它连接到国外服务器下载游戏。
在主界面找到【全局扩展脚本】,右键,编辑文件,复制下面内容覆盖原文件
1 | const prependRules = [ |
你可以将 Steam 社区和商店页面指定走代理,但下载相关域名设为直连。
这里的 DIRECT,可以替换为你所需要的,如果你想用代理下载,可以替换为你的策略组名字。
在 Clash Verge 中打开「连接」界面,观察访问 store.steampowered.com 时是否走代理,而 content.steampowered.com 是否走直连即可。
你也可以查看 Clash 的日志输出,确认每个域名是否命中预期规则。
steamcontent.com 和 steamusercontent.com,这部分建议走直连。steamcommunity.com 等社区功能如果不走代理可能无法加载头像或聊天功能。1 |
|
#Hadoop基础
Hadoop 的核心组件包括 HDFS、MapReduce、YARN 以及 Hadoop Common。
| 方面 | Hadoop 1.x | Hadoop 2.x |
|---|---|---|
| 资源管理 | JobTracker 同时负责资源管理和作业调度,存在单点故障和扩展性瓶颈 | YARN 将资源管理与作业监控分离:ResourceManager + NodeManager + ApplicationMaster |
| 作业跟踪 | MapReduce 作业由 JobTracker 统一跟踪,任务过多时压力巨大 | ApplicationMaster 负责单个作业的生命周期,ResourceManager 只负责分配资源 |
| 支持框架 | 仅支持 MapReduce | 支持 MapReduce、Spark、Flink、Tez 等多种框架 |
| 扩展性 | 集群规模受限(JobTracker 内存压力),通常不超过 4000 节点 | 可扩展至上万节点,ResourceManager 可水平扩展(HA) |
| 容错 | JobTracker 故障导致所有作业失败 | ResourceManager 和 ApplicationMaster 均有 HA 方案,单点故障影响小 |
简单记忆:
1.x = HDFS + MapReduce(紧耦合,资源管理在 MapReduce 内)。
2.x = HDFS + YARN + MapReduce(YARN 独立管理资源,MapReduce 降为运行在 YARN 上的应用)。
Hadoop 主要用于解决海量数据(TB/PB 级)的存储与处理问题,适合以下场景:
不适合:低延迟随机读写(改用 HBase 或 Kudu)、实时流处理(改用 Spark Streaming/Flink)、事务性要求高的场景。
伪分布模式:所有守护进程(NameNode、DataNode、ResourceManager、NodeManager)运行在同一台机器上,但每个进程独立 JVM,模拟分布式行为。
安装 JDK(1.8 或 11)
bash
1 | sudo apt install openjdk-8-jdk # Ubuntu |
设置 SSH 免密登录(本机)
bash
1 | ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa |
下载并解压 Hadoop
bash
1 | wget https://archive.apache.org/dist/hadoop/common/hadoop-3.3.6/hadoop-3.3.6.tar.gz |
修改环境变量(~/.bashrc 或 /etc/profile)
bash
1 | export HADOOP_HOME=/usr/local/hadoop-3.3.6 |
修改 Hadoop 配置文件(位于 $HADOOP_HOME/etc/hadoop)
core-site.xml
xml
1 | <configuration> |
hdfs-site.xml
xml
1 | <configuration> |
mapred-site.xml
xml
1 | <configuration> |
yarn-site.xml
xml
1 | <configuration> |
设置 Hadoop 环境变量文件(可选 hadoop-env.sh 中指定 JAVA_HOME)
格式化 NameNode(仅首次执行)
bash
1 | hdfs namenode -format |
启动 Hadoop 服务
bash
1 | start-dfs.sh # 启动 HDFS (NameNode + DataNode) |
或一键启动 start-all.sh(已弃用,建议分开)。
验证进程
bash
1 | jps |
应看到:NameNode、DataNode、SecondaryNameNode、ResourceManager、NodeManager。
访问 Web 界面
http://localhost:9870(Hadoop 3.x)http://localhost:8088测试运行(例如执行自带 wordcount)
bash
1 | hdfs dfs -mkdir /input |
在一台或多台机器的集群安装中,通常需要修改以下 4 个核心 XML 文件(位于 $HADOOP_HOME/etc/hadoop/):
| 文件 | 作用 | 关键配置示例 |
|---|---|---|
core-site.xml |
Hadoop 核心通用配置 | fs.defaultFS(HDFS 访问地址) |
hdfs-site.xml |
HDFS 专属配置 | dfs.replication(副本数)、dfs.namenode.name.dir、dfs.datanode.data.dir |
mapred-site.xml |
MapReduce 配置 | mapreduce.framework.name(设为 yarn) |
yarn-site.xml |
YARN 资源管理配置 | yarn.resourcemanager.hostname、yarn.nodemanager.aux-services |
此外,有时还需要修改:
workers**(旧名 slaves):列出所有 DataNode 和 NodeManager 的主机名(每行一个)。hadoop-env.sh**:设置 JAVA_HOME 环境变量。yarn-env.sh**:可选的 YARN 环境变量。对于伪分布模式,
workers文件里只写localhost即可。
如果你需要更详细的安装教程(比如完全分布式集群的配置)或对每个配置项的解释,我可以进一步展开说明。
Command-line client for Quark Drive based on libquarkpan
Readme4 VersionsDependenciesDependentsSecurity
quarkpan 是基于 libquarkpan 的夸克网盘命令行工具。
它是面向直接使用终端的场景,负责把底层库能力包装成可恢复、可观察、可取消的命令行体验。
当前命令行支持:
auth 管理持久化 Cookielist 列出目录内容folder create 创建目录delete 删除一个或多个文件或目录项rename 重命名文件或目录项download 下载文件download-dir 下载整个目录upload 上传文件upload-dir 上传整个目录同时支持:
--color auto|always|never.quark.task 任务文件-c, --continue 恢复传输quarkpan 会把底层 libquarkpan 的 TLS backend feature 透传出来,命名与 reqwest 0.13 对齐,默认使用 default-tls。
示例:
1 | cargo install quarkpan |
1 | cargo install quarkpan |
1 | cargo run --bin quarkpan -- --help |
CLI 需要夸克登录后的 Cookie,支持三种方式:
--cookie 'k1=v1; k2=v2'--cookie-file ./cookie.txtQUARK_COOKIEauth set-cookie 持久化到系统配置目录Cookie 内容应为完整的 key=value; key2=value2 格式。 auth set-cookie 需要显式指定来源:
--cookie--from-stdin--from-nano--from-vi1 | quarkpan --cookie 'k1=v1; k2=v2' list |
1 | quarkpan auth set-cookie --from-stdin |
也可以显式传入:
1 | quarkpan auth set-cookie --cookie 'k1=v1; k2=v2' |
也支持通过标准输入:
1 | printf 'k1=v1; k2=v2\n' | quarkpan auth set-cookie --from-stdin |
如果直接在终端运行:
1 | quarkpan auth set-cookie --from-stdin |
CLI 会先提示:
1 | paste cookie, then press Enter: |
也支持通过编辑器:
1 | quarkpan auth set-cookie --from-nano |
1 | quarkpan --cookie 'k1=v1; k2=v2' list --pdir-fid 0 --more |
1 | quarkpan --cookie 'k1=v1; k2=v2' folder create --pdir-fid 0 --file-name 我的文档 |
1 | quarkpan --cookie 'k1=v1; k2=v2' rename --fid <fid> --file-name 新名字 |
1 | quarkpan --cookie 'k1=v1; k2=v2' delete --fid <fid1> --fid <fid2> |
1 | quarkpan --cookie 'k1=v1; k2=v2' download --fid <fid> --output ./file.bin |
1 | quarkpan --cookie 'k1=v1; k2=v2' download --fid <fid> --output ./file.bin -c |
1 | quarkpan download-dir --pdir-fid <pdir_fid> --output ./backup |
1 | quarkpan download-dir --pdir-fid <pdir_fid> --output ./backup -c |
1 | quarkpan --cookie 'k1=v1; k2=v2' upload --file ./file.bin --pdir-fid 0 |
1 | quarkpan --cookie 'k1=v1; k2=v2' upload --file ./file.bin --pdir-fid 0 -c |
1 | quarkpan upload-dir --dir ./photos --pdir-fid 0 |
1 | quarkpan upload-dir --dir ./photos --pdir-fid 0 -c |
下载和上传在中断、报错或收到 Ctrl+C 后,会保留:
1 | ${filename}.quark.task |
目录任务使用与目录同级同名的任务文件,例如:
1 | photos.quark.task |
用途:
成功完成后,任务文件会自动删除。
Ctrl+C 时:
-c 恢复进度条显示规则:
size/md5/sha1--json 输出模式1 | GPL-3.0-only |
平时开发过程中遇到的一些问题,我都会整理到文档中。有些感觉不错的,会二次整理成文章发布到我的博客中。但是有些文章如果存在隐私内容,或者不打算公开的话,就不能放在博客中了。
我的博客是使用 Hexo 来搭建的,并不能设置某些文章不可见。但如果不在电脑旁或者出门没有带电脑又想要查看一下之前记录的内容,就很不方便了。
我也尝试在 github 上去找一些可以设置账户的开源的博客框架,但测试过一些后发现并没有符合自己需求的,而自己开发却没有时间。
思来想去,就想看看有没有插件能够实现 Hexo 博客的加密操作。最终让我找到了一款名为 Hexo-Blog-Encrypt 的插件。
为了防止以下的修改可能出现版本差异,这里我先声明我使用的 Hexo 版本信息:
1 | hexo: 4.2.1 |
1 | npm install --save hexo-blog-encrypt |
该插件的使用也很方便,这里我仅作简单介绍,详细的可以查看官方文档。 D0n9X1n/hexo-blog-encrypt: Yet, just another hexo plugin for security.
要为一篇文章添加密码查看功能,只需要在文章信息头部添加 password 字段即可:
1 |
|
分别为每篇文章设置密码,虽然很灵活,但是配置或者修改起来非常麻烦。为此,可以通过设置统一配置来实现全局加密。
通过添加指定 tag 的方式,可以为所有需要加密的文章添加统一加密操作。只需要在需要加密的文章中,添加设置的 tag值 即可。
在Hexo主配置文件 _config.yml 中添加如下配置:
1 | # Security |
之后,需要清除缓存后重新生成 hexo clean && hexo s -g。
其中的 tag 部分:
1 | tags: |
表示当在文章中指定了 private 这个 tag 后,该文章就会自动加密并使用对应的值 hello 作为密码,输入密码后才可查看。
相应的文章头部设置:
1 |
|
可能有这样的情况,属于 private 标签下的某篇文章在一段时间内想要开放访问。如果在描述中加上密码提示: 当前文章密码为xxx,请输入密码后查看 ,来让用户每次查看时都要先输入密码后再查看,这样的操作又会给访客带来不便。
这时可以单独设置允许某篇文章不设置密码。
只需要在使用 加密tag 的前提下,结合 password 来实现即可。在博客文章的头部添加 password 并设置为 "" 就能取消当前文章的 Tag 加密。
相应的设置示例如下:
1 |
|
在全局加密配置下,我们可以通过设置多个 加密tag 来为多篇不同类型的文章设置相同的查看密码:
1 | tags: |
那么可能有这样的场景:
属于 private 标签下的某篇文章想要设置成不一样的密码,防止用户恶意通过一个密码来查看同标签下的所有文章。此时,仍可以通过 password 参数来实现:
1 |
|
说明:
该文章通过tag值 private 做了加密,按说密码应该为 hello ,但是又在信息头中设置了 password ,因为配置的优先级是 文章信息头 > 按标签加密,所以最后的密码为 buyiyang 。
在为某些文章设置了 加密后查看 之后,不经意间发现这些文章的目录在解密后却不显示了。
从插件的 github issues 中我找到了相关的讨论:
原因:
加密的时候,
post.content会变成加密后的串,所以原来的TOC生成逻辑就会针对加密后的内容。
所以这边我只能把原来的内容存进post.origin字段。
找到文件 themes/next/layout/_macro/sidebar.swig ,编辑如下部分:

插件 hexo-blog-encrypt 对文章内容进行加密后,会将原始文章内容保存到字段 origin 中,当生成 TOC 时,我们可以通过 page.origin 来得到原始内容,生成文章目录。
相应的代码为:
1 | <aside class="sidebar"> |
修改完成后,执行 hexo clean && hexo s -g 并重新预览。
效果如下:

不过,这样的效果貌似不是我想要的。我理想中的效果应该是:
站点概览 部分,不需要看到 文章目录 部分。站点概览 和 文章目录 两部分。而现在加密后的文章未解密之前也可以看到 文章目录 ,虽然该目录不可点击。
当然,如果你不是很介意,那么到这里就可以结束了。如果你和我一样有一些 追求完美的强迫症 的话,我们继续。
查看了 hexo-blog-encrypt 相关的 issues ,我找到了一种 折中 的解决方法。
从 issue Archer主题解密后TOC依旧不显示(已按手册修改) 中我们可以知道:
我们可以在文章加密的前提下,通过将目录部分加入到一个 不可见的div 中来实现 隐藏目录 的效果。在源码中的 hexo-blog-encrypt/lib/hbe.js 部分我们也可以看到,解密后通过设置 id 值为 toc-div 的元素为 display:inline 来控制显示隐藏。
1 | {%- if (page.encrypt) %} |
对文件 themes/next/layout/_macro/sidebar.swig 修改后的代码如下:
1 | <!--noindex--> |
但这种方法并不是完全的加密,而是采用 障眼法 的方式,通过查看html源文件还是可以看到目录内容的,只是不显示罢了。
对于这个问题,hexo-blog-encrypt 插件的作者也作了说明:next 主题内没有 article.ejs 文件【TOC 相关】 · Issue #162 · D0n9X1n/hexo-blog-encrypt
因为该插件中目前只有一个参数 page.encrypt 可以用来判断当前的文章是否进行了 加密处理 ,而不能获知该文章当前是处于 加密后的锁定 状态,还是处于 加密后的解锁 状态。如果再有一个参数结合起来一起处理就好了。
所以,目前只能在解锁前隐藏目录,解锁后再显示目录。但在解锁前目录区域还是会展开,只是没有内容显示罢了。
类似于我的博客文章列表中的 文章置顶 的提示效果,考虑在文章列表中对加密的文章增加类似的 加密 提示信息。
上面对于文章的加密处理,一方面是在 配置文件 中添加的 tag 全局配置,另一方面是在单个 md源文件 中添加的 password 参数。所以我们需要对这两种情况分别做处理。
针对于 password 字段,参考获取其他字段的方法,比如获取标题用 post.title ,获取置顶用 post.top ,那么获取 password 就是 post.password 了。
可以参考我之前添加置顶提示信息的操作,对文件 themes/next/layout/_macro/post.swig 的修改如下:
1 | {# 加密文章添加提示信息-for password #} |
针对于 tag 标签的获取,可以从文件 themes/next/layout/_macro/post.swig 中找到类似的处理方法:
即可以用最简单的 遍历法 来处理:
我们获取到配置文件中设置的所有 加密tag值 ,再找到文章中的 tag标签 。二者一对比,有匹配的项则说明该文章设置了 tag值 加密。
要在 .swig 文件中实现相应的对比逻辑,就需要了解其使用的语法格式。而对于 swig 文件,使用的是 Swig 语法。
Swig是一个非常棒的、类似Django/jinja的node.js模板引擎。
不过看到这个代码库 paularmstrong/swig: Take a swig of the best template engine for JavaScript. 已经 归档 了。
但因为 Swig 是类似于 jinja 的模板引擎,那么我们直接去参考 jinja 的语法就可以了。
获取全局配置中 encrypt.tags 的值:
1 | {%- if (config.encrypt) and (config.encrypt.tags) %} |
在文章列表中获取当前文章包含的 tags 列表:
1 | {%- if post.tags %} |
对于其中展示的文本格式,可以参考已有的 发表于 更新于 这些副标题的格式来实现。
例如:
1 | <span class="post-meta-item"> |
对其进行优化,我们只需要显示提示文字,不需要后面的带下划线部分,最终得到的就是:
1 | <span class="post-meta-item"> |
整合上面的代码,对于文章中包含 password 的文档,通过如下方式来显示:

相应代码:
1 | {# 加密文章添加提示信息-for password #} |
对于文章中包含指定加密 tags 的文档,通过如下方式来显示:

相应代码:
1 | {# 加密文章添加提示信息-for config tags #} |
对于两种都有的文档,我们只需要通过一个 判断 来处理就好了:优先判断文档中的 password 字段。当文档中包含 password 时,就说明是加密文章;否则就去判断配置文件看是否为加密文章。

最后的代码为:
1 | {# 加密文章添加提示信息-for password #} |
稍微不好的一点就是,上面的操作是通过 两个for循环 来处理的,会导致一些性能问题。不过这个操作是在编译过程 hexo g 的时候来处理的,不影响博客浏览,也就可以忽略了。
对于需要显示的图标,可以从网站 Icons | Font Awesome 中获取。
例如,我这里选择的是 锁 的icon图标,得到的代码如下:
1 | <i class="fas fa-lock"></i> |
链接: https://cloud.189.cn/t/NjArIbzuUF7z (访问码:cm0f)
拖入Intellij 中,然后重启
重启完成后,输入激活码
1 | BISACXYELK-eyJsaWNlbnNlSWQiOiJCSVNBQ1hZRUxLIiwibGljZW5zZWVOYW1lIjoiQ2hpbmFOQiIsImFzc2lnbmVlTmFtZSI6IiIsImFzc2lnbmVlRW1haWwiOiIiLCJsaWNlbnNlUmVzdHJpY3Rpb24iOiIiLCJjaGVja0NvbmN1cnJlbnRVc2UiOmZhbHNlLCJwcm9kdWN0cyI6W3siY29kZSI6IklJIiwicGFpZFVwVG8iOiIyMDk5LTEyLTMxIiwiZXh0ZW5kZWQiOmZhbHNlfSx7ImNvZGUiOiJBQyIsInBhaWRVcFRvIjoiMjA5OS0xMi0zMSIsImV4dGVuZGVkIjpmYWxzZX0seyJjb2RlIjoiRFBOIiwicGFpZFVwVG8iOiIyMDk5LTEyLTMxIiwiZXh0ZW5kZWQiOnRydWV9LHsiY29kZSI6IlJTQyIsInBhaWRVcFRvIjoiMjA5OS0xMi0zMSIsImV4dGVuZGVkIjp0cnVlfSx7ImNvZGUiOiJQUyIsInBhaWRVcFRvIjoiMjA5OS0xMi0zMSIsImV4dGVuZGVkIjpmYWxzZX0seyJjb2RlIjoiUlNGIiwicGFpZFVwVG8iOiIyMDk5LTEyLTMxIiwiZXh0ZW5kZWQiOnRydWV9LHsiY29kZSI6IkdPIiwicGFpZFVwVG8iOiIyMDk5LTEyLTMxIiwiZXh0ZW5kZWQiOmZhbHNlfSx7ImNvZGUiOiJETSIsInBhaWRVcFRvIjoiMjA5OS0xMi0zMSIsImV4dGVuZGVkIjp0cnVlfSx7ImNvZGUiOiJDTCIsInBhaWRVcFRvIjoiMjA5OS0xMi0zMSIsImV4dGVuZGVkIjpmYWxzZX0seyJjb2RlIjoiUlMwIiwicGFpZFVwVG8iOiIyMDk5LTEyLTMxIiwiZXh0ZW5kZWQiOnRydWV9LHsiY29kZSI6IlJDIiwicGFpZFVwVG8iOiIyMDk5LTEyLTMxIiwiZXh0ZW5kZWQiOnRydWV9LHsiY29kZSI6IlJEIiwicGFpZFVwVG8iOiIyMDk5LTEyLTMxIiwiZXh0ZW5kZWQiOmZhbHNlfSx7ImNvZGUiOiJQQyIsInBhaWRVcFRvIjoiMjA5OS0xMi0zMSIsImV4dGVuZGVkIjpmYWxzZX0seyJjb2RlIjoiUlNWIiwicGFpZFVwVG8iOiIyMDk5LTEyLTMxIiwiZXh0ZW5kZWQiOnRydWV9LHsiY29kZSI6IlJTVSIsInBhaWRVcFRvIjoiMjA5OS0xMi0zMSIsImV4dGVuZGVkIjpmYWxzZX0seyJjb2RlIjoiUk0iLCJwYWlkVXBUbyI6IjIwOTktMTItMzEiLCJleHRlbmRlZCI6ZmFsc2V9LHsiY29kZSI6IldTIiwicGFpZFVwVG8iOiIyMDk5LTEyLTMxIiwiZXh0ZW5kZWQiOmZhbHNlfSx7ImNvZGUiOiJEQiIsInBhaWRVcFRvIjoiMjA5OS0xMi0zMSIsImV4dGVuZGVkIjpmYWxzZX0seyJjb2RlIjoiREMiLCJwYWlkVXBUbyI6IjIwOTktMTItMzEiLCJleHRlbmRlZCI6dHJ1ZX0seyJjb2RlIjoiUERCIiwicGFpZFVwVG8iOiIyMDk5LTEyLTMxIiwiZXh0ZW5kZWQiOnRydWV9LHsiY29kZSI6IlBXUyIsInBhaWRVcFRvIjoiMjA5OS0xMi0zMSIsImV4dGVuZGVkIjp0cnVlfSx7ImNvZGUiOiJQR08iLCJwYWlkVXBUbyI6IjIwOTktMTItMzEiLCJleHRlbmRlZCI6dHJ1ZX0seyJjb2RlIjoiUFBTIiwicGFpZFVwVG8iOiIyMDk5LTEyLTMxIiwiZXh0ZW5kZWQiOnRydWV9LHsiY29kZSI6IlBQQyIsInBhaWRVcFRvIjoiMjA5OS0xMi0zMSIsImV4dGVuZGVkIjp0cnVlfSx7ImNvZGUiOiJQUkIiLCJwYWlkVXBUbyI6IjIwOTktMTItMzEiLCJleHRlbmRlZCI6dHJ1ZX0seyJjb2RlIjoiUFNXIiwicGFpZFVwVG8iOiIyMDk5LTEyLTMxIiwiZXh0ZW5kZWQiOnRydWV9LHsiY29kZSI6IkRQIiwicGFpZFVwVG8iOiIyMDk5LTEyLTMxIiwiZXh0ZW5kZWQiOnRydWV9LHsiY29kZSI6IlJTIiwicGFpZFVwVG8iOiIyMDk5LTEyLTMxIiwiZXh0ZW5kZWQiOnRydWV9XSwibWV0YWRhdGEiOiIwMTIwMjAwNzI4RVBKQTAwODAwNiIsImhhc2giOiIxNTAyMTM1NC8wOi0xMjUxMTE0NzE3IiwiZ3JhY2VQZXJpb2REYXlzIjowLCJhdXRvUHJvbG9uZ2F0ZWQiOmZhbHNlLCJpc0F1dG9Qcm9sb25nYXRlZCI6ZmFsc2V9-H7NUmWcLyUNV1ctnlzc4P79j15qL56G0jeIYWPk/HViNdMg1MqPM7BR+aHR28yyuxK7Odb2bFDS8CeHNUtv7nT+4fUs85JJiqc3wc1psRpZq5R77apXLOmvmossWpbAw8T1hOGV9IPUm1f2O1+kLBxrOkdqPpv9+JanbdL7bvchAid2v4/dyQMBYJme/feZ0Dy2l7Jjpwno1TeblEAu0KZmarEo15or5RUNwtaGBL5+396TLhnw1qL904/uPnGftjxWYluLjabO/uRu/+5td8UA/39a1nvGU2nORNLk2IdRGIheiwIiuirAZrII9+OxB+p52i3TIv7ugtkw0E3Jpkw==-MIIDlzCCAn+gAwIBAgIBCTANBgkqhkiG9w0BAQsFADAYMRYwFAYDVQQDEw1KZXRQcm9maWxlIENBMCAXDTE4MTEwMTEyMjk0NloYDzIwOTkwODA5MDIyNjA3WjBoMQswCQYDVQQGEwJDWjEOMAwGA1UECBMFTnVzbGUxDzANBgNVBAcTBlByYWd1ZTEZMBcGA1UEChMQSmV0QnJhaW5zIHMuci5vLjEdMBsGA1UEAxMUcHJvZDN5LWZyb20tMjAxODExMDEwggEiMA0GCSqGSIb3DQEBAQUAA4IBDwAwggEKAoIBAQCdXyaNhhRySH1a8d7c8SlLLFdNcQP8M3gNnq7gudcpHC651qxRrN7Qks8gdXlIkA4u3/lp9ylp95GiIIDo4ydYje8vlTWDq02bkyWW/G7gZ3hkbBhRUK/WnNyr2vwWoOgwx5CfTRMjKkPkfD/+jffkfNfdGmGcg9yfnqPP9/AizKzWTsXSeS+0jZ8Nw5tiYFW+lpceqlzwzKdTHug7Vs0QomUPccRtZB/TBBEuiC7YzrvLg4Amu0I48ETAcch/ztt00nx/oj/fu1DTnz4Iz4ilrNY+WVIEfDz/n3mz+PKI9kM+ZeB0jAuyLsiC7skGpIVGX/2HqmZTtJKBZCoveAiVAgMBAAGjgZkwgZYwSAYDVR0jBEEwP4AUo562SGdCEjZBvW3gubSgUouX8bOhHKQaMBgxFjAUBgNVBAMMDUpldFByb2ZpbGUgQ0GCCQDSbLGDsoN54TAJBgNVHRMEAjAAMBMGA1UdJQQMMAoGCCsGAQUFBwMBMAsGA1UdDwQEAwIFoDAdBgNVHQ4EFgQUYSkb2hkZx8swY0GRjtKAeIwaBNwwDQYJKoZIhvcNAQELBQADggEBAJZOakWgjfY359glviVffBQFxFS6C+4WjYDYzvzjWHUQoGBFKTHG4xUmTVW7y5GnPSvIlkaj49SzbD9KuiTc77GHyFCTwYMz+qITgbDg3/ao/x/be4DD/k/byWqW4Rb8OSYCshX/fNI4Xu+hxazh179taHX4NaH92ReLVyXNYsooq7mE5YhR9Qsiy35ORviQLrgFrMCGCxT9DWlFBuiPWIOqN544sL9OzFMz+bjqjCoAE/xfIJjI7H7SqGFNrx/8/IuF0hvZbO3bLIz+BOR1L2O+qT728wK6womnp2LLANTPbwu7nf39rpP182WW+xw2z9MKYwwMDwGR1iTYnD4/Sjw= |
当你阅读这篇文章时,你正在见证历史。过去五十年间,科技和互联网的功能发生了翻天覆地的变化,如今已成为我们日常生活中便捷的系统。
但正如你可能已经猜到的那样,互联网并非一直都是现在这个样子,也并非一直如此流行。事实上,在2000年,只有52%的美国成年人表示他们使用互联网;但到了2018年,这个数字跃升至82%[1]。
从最初让你来到这里的问题:“互联网是如何运作的?”到网上购物、与家人朋友交流,互联网彻底改变了我们的生活、协作和学习方式。但这一切是如何开始的?互联网又是如何演变成我们今天所熟知的无处不在的系统呢?

要充分了解互联网的运作方式以及我们是如何走到今天的,我们需要从头开始。
1969 年 10 月 29 日,一个名为 ARPANET(高级研究计划署)的组织启动了互联网的第一个版本(也称为 ARPANET),连接了犹他大学、加州大学圣巴巴拉分校、加州大学洛杉矶分校和斯坦福研究所的四台主要计算机 [2]。
当这个计算机网络连接起来后,大学就可以从一个组织到另一个组织以及在内部访问文件和传输信息。
随着研究人员不断完善系统,他们持续连接其他大学的计算机,包括麻省理工学院、哈佛大学和卡内基梅隆大学。最终,ARPANET 更名为“互联网”。
互联网早期只有计算机专家、科学家、工程师和图书管理员使用,他们必须学习复杂的系统才能使用它,但随着技术的进步和消费者的适应,它成为了世界各地人们必不可少的工具。
20世纪70年代是互联网发展的重要转型时期。电子邮件于1972年问世,全国各地的图书馆实现了互联互通,最重要的是,由于传输控制协议和互联网协议(TCP/IP)架构的出现,信息交换变得更加顺畅。
这些协议的发明有助于规范通过网络发送和接收信息的方式,使信息传输更加一致,无论你在哪里或以何种方式访问互联网。
1986年,美国国家科学基金会通过资助NSFNET(一个遍布全国的超级计算机网络),将互联网的发展推向了新的高度。
这些超级计算机为个人计算奠定了基础,弥合了仅用于学术目的的计算机和用于执行日常任务的计算机之间的差距。
1991年,明尼苏达大学开发了第一个用户友好的互联网界面,使用户能够更便捷地访问校园文件和信息。内华达大学里诺分校在此基础上继续完善这一易用界面,并引入了搜索功能和索引功能。
随着互联网的发展不断演变和重点转移,美国国家科学基金会于 1995 年 5 月停止了对互联网骨干网 (NSFNET) 的赞助。
这一变革取消了互联网商业用途的所有限制,并最终促成了互联网的多元化发展和快速增长。此后不久,AOL、CompuServe 和 Prodigy 也加入了 Delphi 的行列,开始向消费者提供商业互联网服务。
上世纪九十年代末, WiFi和 Windows 98的问世标志着科技行业致力于发展互联网的商业化。这一举措使微软等公司得以接触到新的受众群体——消费者(比如您)。
快进到今天。据估计,现在有 30 亿人使用互联网,其中许多人每天都使用互联网来帮助他们从 A 点到达 B 点、与亲人联系、在工作中协作,或者了解更多重要问题,例如互联网是如何运作的?[3]
随着科技的进步和互联网渗透到我们生活的方方面面,预计会有更多人使用互联网。研究人员预测,到 2030 年,互联网用户将达到 75 亿,连接到互联网的设备将达到 5000 亿台 [4]。
现在你已经对互联网的发展历程有了一些了解,让我们来探讨一下当前的问题:“互联网是如何运作的?”
互联网是一个全球性的计算机网络,它通过互连的设备传输各种数据和媒体。它的工作原理是使用数据包路由网络,该网络遵循互联网协议 (IP) 和传输控制协议 (TCP) [5]。
TCP 和 IP 协同工作,确保无论你使用什么设备或在哪里使用,互联网上的数据传输都是一致且可靠的。
数据通过互联网传输时,是以消息和数据包的形式进行的。通过互联网发送的数据称为消息,但在发送消息之前,消息会被分解成更小的部分,称为数据包。
这些消息和数据包使用互联网协议 (IP) 和传输控制协议 (TCP) 从一台计算机传输到另一台计算机。IP 是一套规则系统,用于管理信息如何通过互联网连接从一台计算机发送到另一台计算机。
通过数字地址(IP 地址),IP 系统接收有关如何传输数据的进一步指令。
传输控制协议 (TCP) 与 IP 协同工作,确保数据传输的可靠性和稳定性。这有助于防止数据包丢失,确保数据包按正确顺序重组,并避免因延迟而对数据质量产生负面影响。
想知道从浏览器启动到搜索结果,互联网是如何运作的吗?让我们一步一步地了解这个过程[7][8][9]。
步骤 1:您的电脑或设备通过调制解调器或路由器连接到互联网。这些设备共同使您能够连接到全球其他网络 [6]。
您的路由器使多台计算机能够加入同一网络,而调制解调器则连接到您的 ISP(互联网服务提供商),ISP 为您提供有线或 DSL 互联网服务。
步骤二:输入网址,也称为URL(统一资源定位符)。每个网站都有其唯一的URL,它会告诉你的网络服务提供商(ISP)你想访问哪个网站。
步骤 3:您的查询被推送至您的 ISP,ISP 连接到多个服务器,这些服务器存储和发送数据,例如 NAP 服务器(网络访问保护)和 DNS(域名服务器)。
接下来,你的浏览器会通过 DNS 查找你在搜索引擎中输入的域名对应的 IP 地址。DNS 会将你在浏览器中输入的文本域名转换成数字 IP 地址。
步骤 4:您的浏览器向目标服务器发送超文本传输协议 (HTTP) 请求,以使用 TCP/IP 将网站的副本发送到客户端。
第五步:服务器批准请求后,会向您的计算机发送“200 OK”消息。然后,服务器以数据包的形式将网站文件发送到浏览器。
步骤 6:当浏览器重新组装数据包时,网站加载完毕,您可以学习、购物、浏览和互动。
第七步:尽情享受搜索结果吧!
无论您是在查找有关互联网如何运作的信息、在线观看您最喜欢的电影,还是在网上浏览旅游优惠,不可否认的是,互联网带我们去了很多地方,而且它还将继续这样做!
虽然现在互联网似乎没有发生什么变化,但很有可能,当我们回顾过去,看到我们走了多远,我们使用这项技术的方式发生了多大的变化,最终,我们会发现,我们自己也是互联网历史的一部分。
[1] 皮尤互联网研究中心;互联网/宽带概况介绍
[2] 沃尔特·豪;《互联网简史》
[3] 资金;以下是互联网用户数量
[4] 思科;物联网
[5] Lifewire;TCP(传输控制协议)详解
[6] Mozilla;网络如何运作
[7] 事物是如何运作的;互联网是如何运作的?
[8] 如何成为极客;互联网是如何运作的?
[9] Medium,《互联网是如何运作的》
几个世纪以来,哲学家和作家们一直在构想一个共享的世界知识库。我们今天所知的互联网是如何形成的?
互联网是一个全球性的计算机网络,它通过互联设备传输各种数据和媒体。它的工作原理是利用数据包路由网络,该网络遵循互联网协议(IP)和传输控制协议(TCP)。[5]
步骤 1:您的电脑或设备通过调制解调器或路由器连接到互联网,从而可以连接到全球其他网络。[6]
路由器允许多台计算机加入同一网络,而调制解调器连接到您的互联网服务提供商 (ISP),ISP 提供有线或 DSL 互联网。
你的个人电脑被称为客户端,而不是服务器。
步骤二:输入网址,也称为URL。URL是统一资源定位符的缩写。
步骤 3:您的查询将被处理并推送至您的 ISP。您的 ISP 拥有多个服务器,用于存储和发送数据,例如 NAP 服务器(网络访问保护)和 DNS(域名服务器)。
您的浏览器会通过 DNS 查找您在浏览器中输入的域名对应的 IP 地址。
步骤 4:浏览器向目标服务器发送超文本传输协议 (HTTP) 请求,以使用 TCP/IP 将网站的副本发送给客户端。
步骤五:服务器批准请求并向客户端计算机发送“200 OK”消息。然后,服务器以数据包的形式将网页文件发送到浏览器。
步骤 6:浏览器重新组装数据包,网页加载。
第七步:尽情上网吧![7][8][9]
在本节中,我们将通过一个完整的网络流量示例,逐步演示计算机在通过计算机网络进行通信时将经历哪些步骤。本示例将整合其他章节中的大量信息,是一个全面而完整的示例。
大多数人都会惊讶地发现,计算机发送一个简单的数据包竟然需要这么多步骤,而且其中有很多步骤对于普通用户来说是完全隐藏的,除非你事先知道,否则你永远不会知道。
如果您已经浏览过本网站的大部分内容,那么您可能已经对本教程可能包含的步骤数量有所了解。
下面的示例展示了一个小型家庭网络,其中一台计算机刚刚启动。该计算机已手动配置了 IP 地址,但尚未与网络通信。用户坐在计算机旁,打开 Web 浏览器并尝试访问 www.iis.se。
首先,我们来看一下整体情况。这张图展示了示例中的网络拓扑结构。在接下来的很多步骤中,我们会放大查看网络中最相关的部分,以避免每次都绘制完整的网络拓扑图。
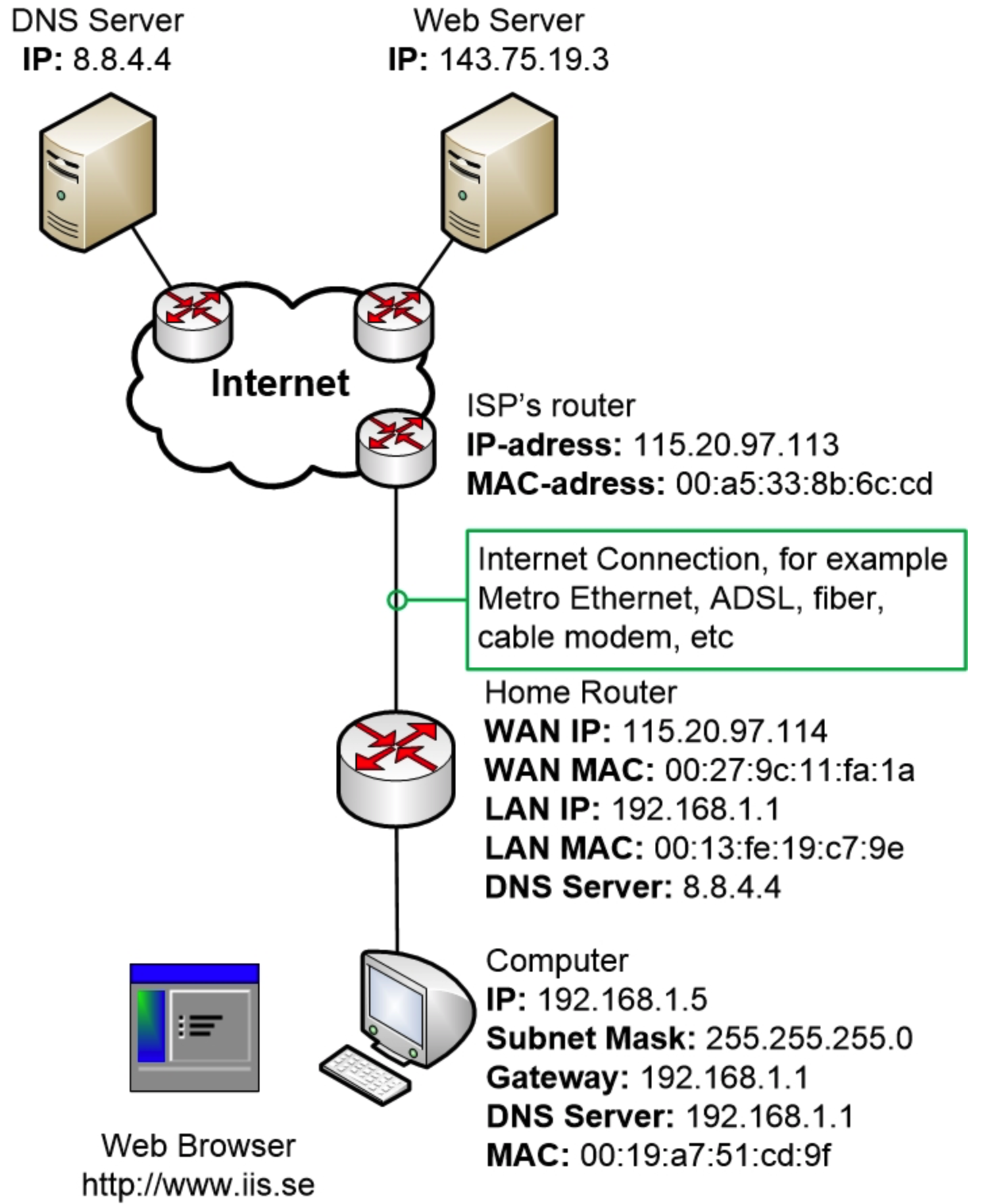
现在让我们从交通示例讲解开始!
一台连接到家庭网络的计算机刚刚启动。该计算机已手动配置了 IP 地址、子网掩码、DNS 服务器和默认网关。DNS 服务器和默认网关地址都指向家庭路由器的局域网 IP 地址。
计算机用户打开网页浏览器并访问www.iis.se
首先,Web浏览器会指示计算机上的操作系统建立计算机与www.iis.se之间的通信。
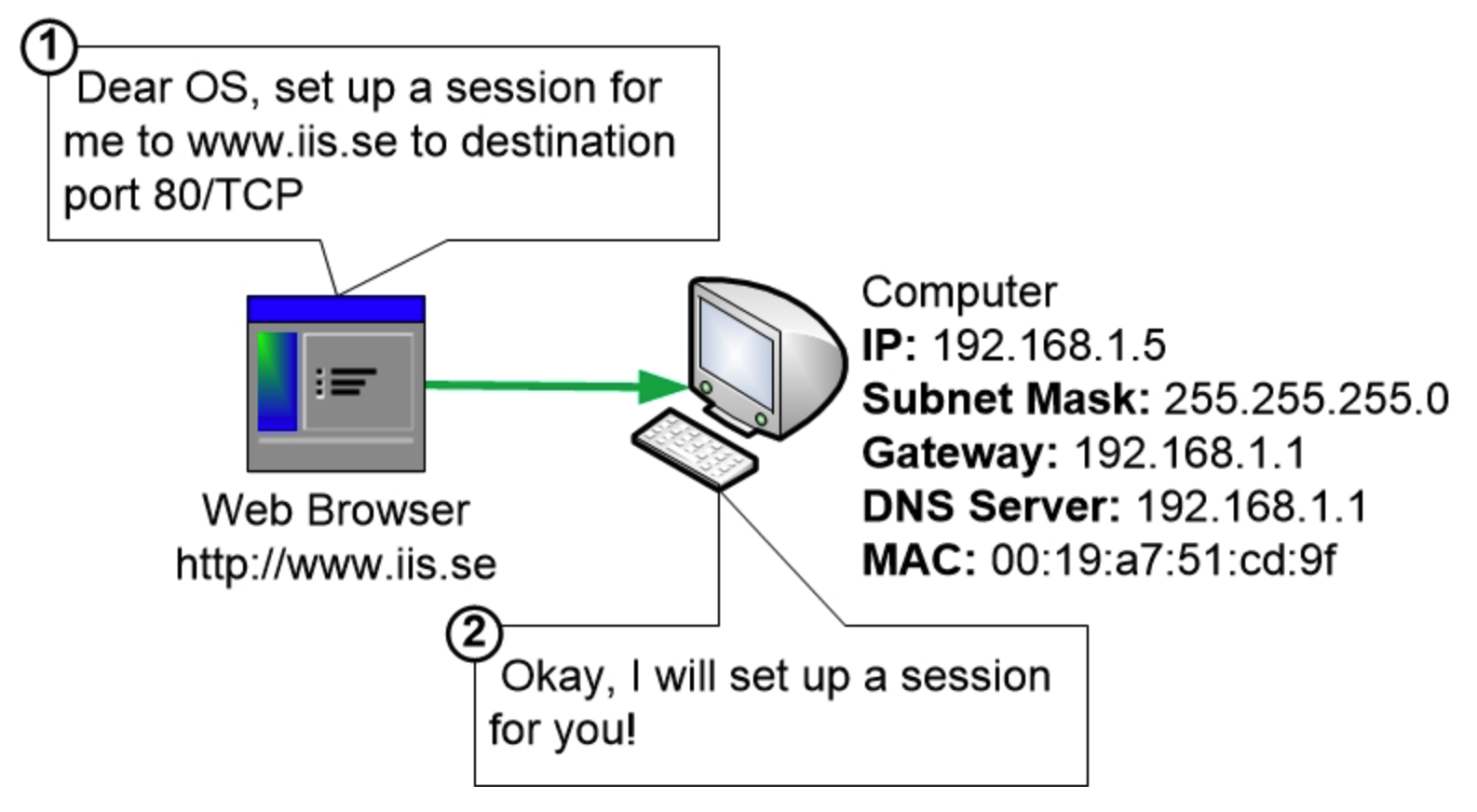
这部分又细分为许多子步骤。
计算机操作系统会检查其 DNS 缓存,以确定是否已知道www.iis.se的 IP 地址。由于计算机刚刚启动,之前从未访问过www.iis.se,因此 DNS 缓存为空。
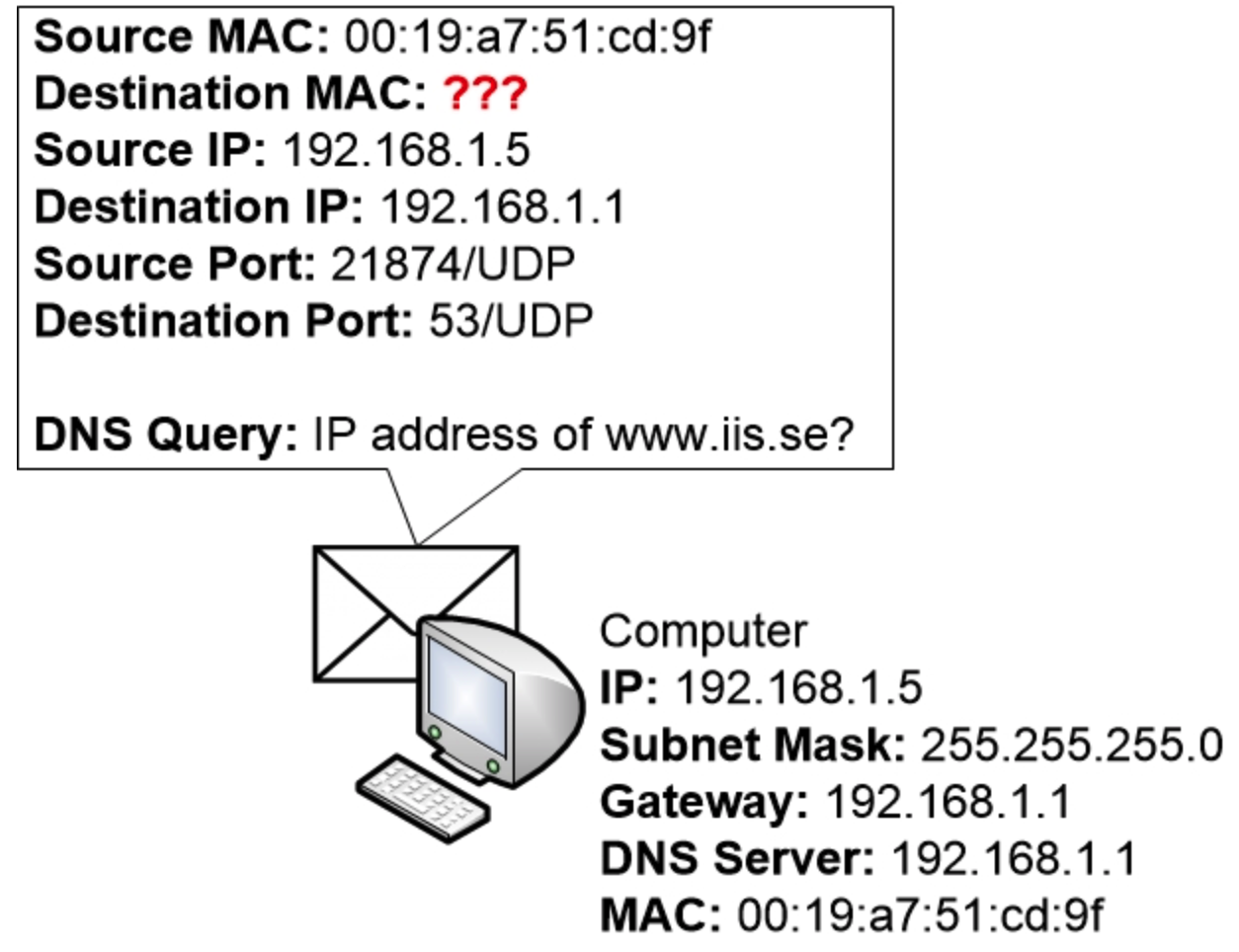
现在计算机必须向其 DNS 服务器查询www.iis.se的 IP 地址。
计算机将构建一个 DNS 查询,并将其发送到它配置使用的 DNS 服务器 192.168.1.1。
DNS 查询的目标地址是 192.168.1.1,源 IP 地址是计算机自身的 IP 地址,即 192.168.1.5。
DNS 使用 UDP 作为传输协议。DNS 查询的目标端口是 53/UDP。当 DNS 查询到达 DNS 服务器时,服务器可以通过查看目标端口 53/UDP 来判断该消息是发往 DNS 服务器程序的,并将消息转发给正在运行的 DNS 程序。
计算机操作系统还必须随机化一个源端口,该端口也会写入消息中。
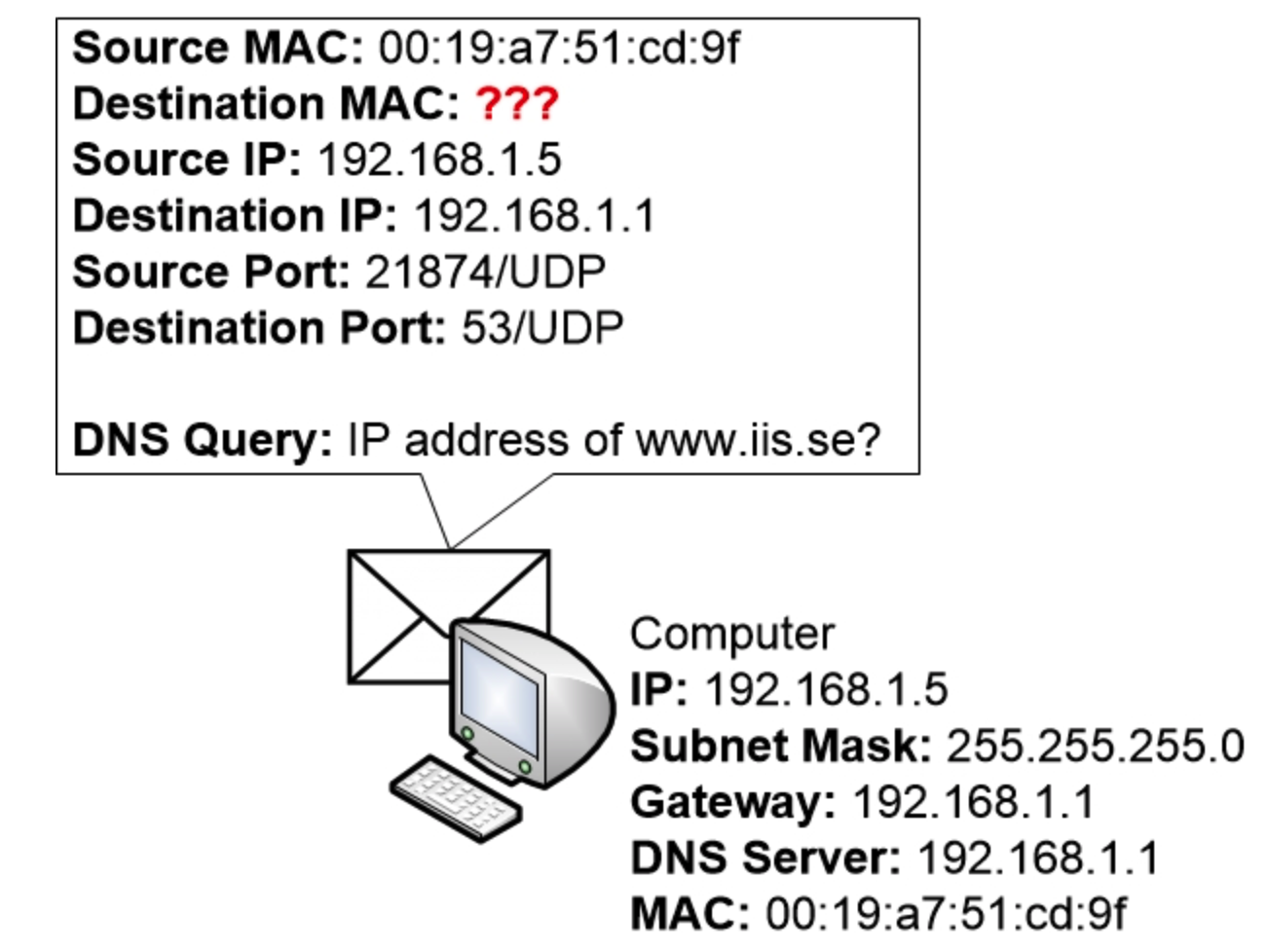
但是,当计算机将 DNS 查询组合起来时,它注意到必须检查应该将数据包发送到哪个目标 MAC 地址。
所以目前,操作系统会将数据包放入内存中的一个队列中,然后开始确定要使用的目标 MAC 地址。
计算机现在将检查其 ARP 表,看看它是否知道与路由器 IP 地址 192.168.1.1 关联的 MAC 地址。
但由于计算机刚刚启动,尚未学习任何 ARP 条目,因此其 ARP 表完全为空。
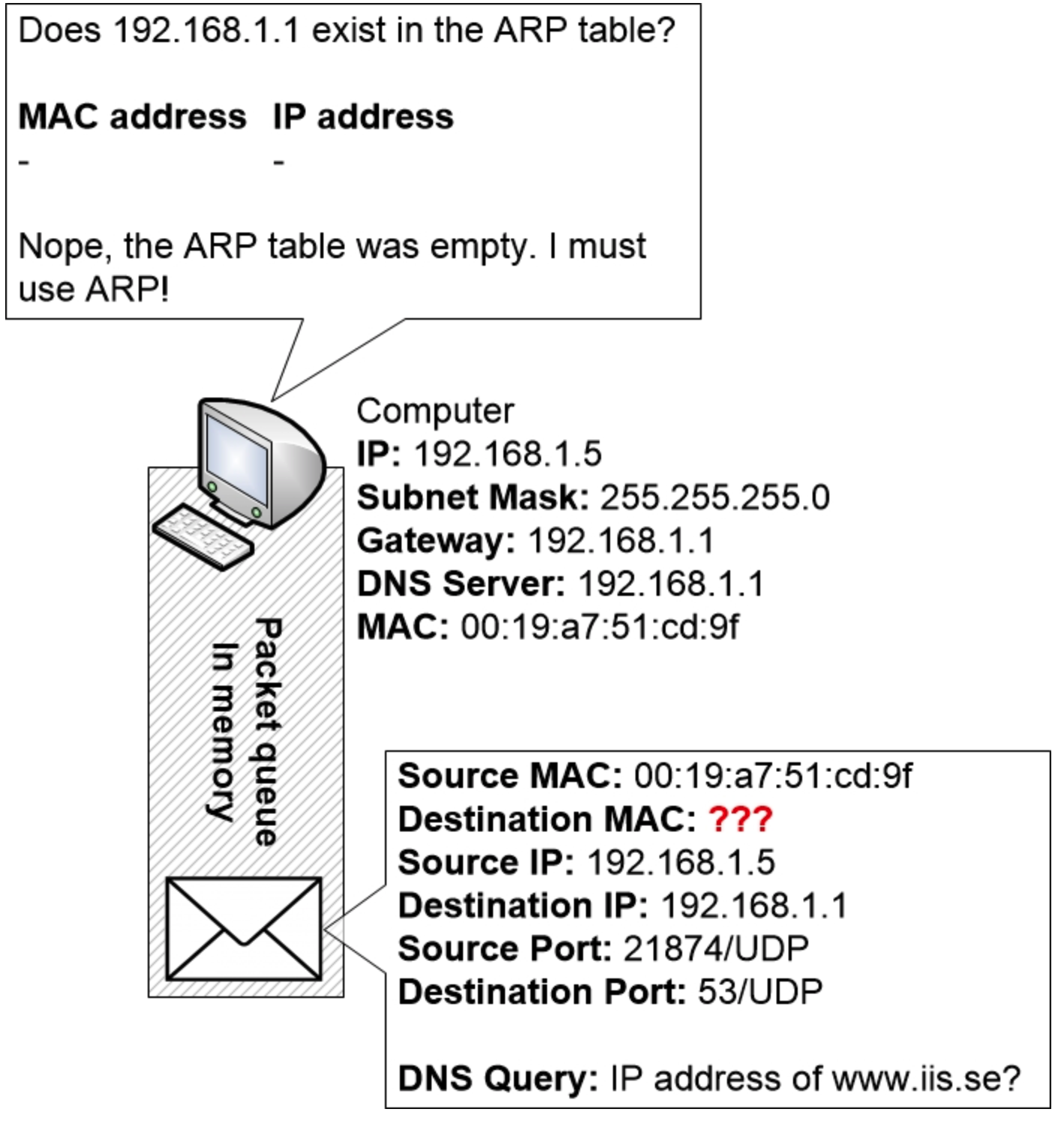
现在,计算机必须向网络中的其他设备构建一个 ARP 请求。该请求将被发送到目标 MAC 地址 FF:FF:FF:FF:FF:FF,即广播地址。结果是,局域网上的所有其他计算机和设备都将收到该请求并读取其内容。
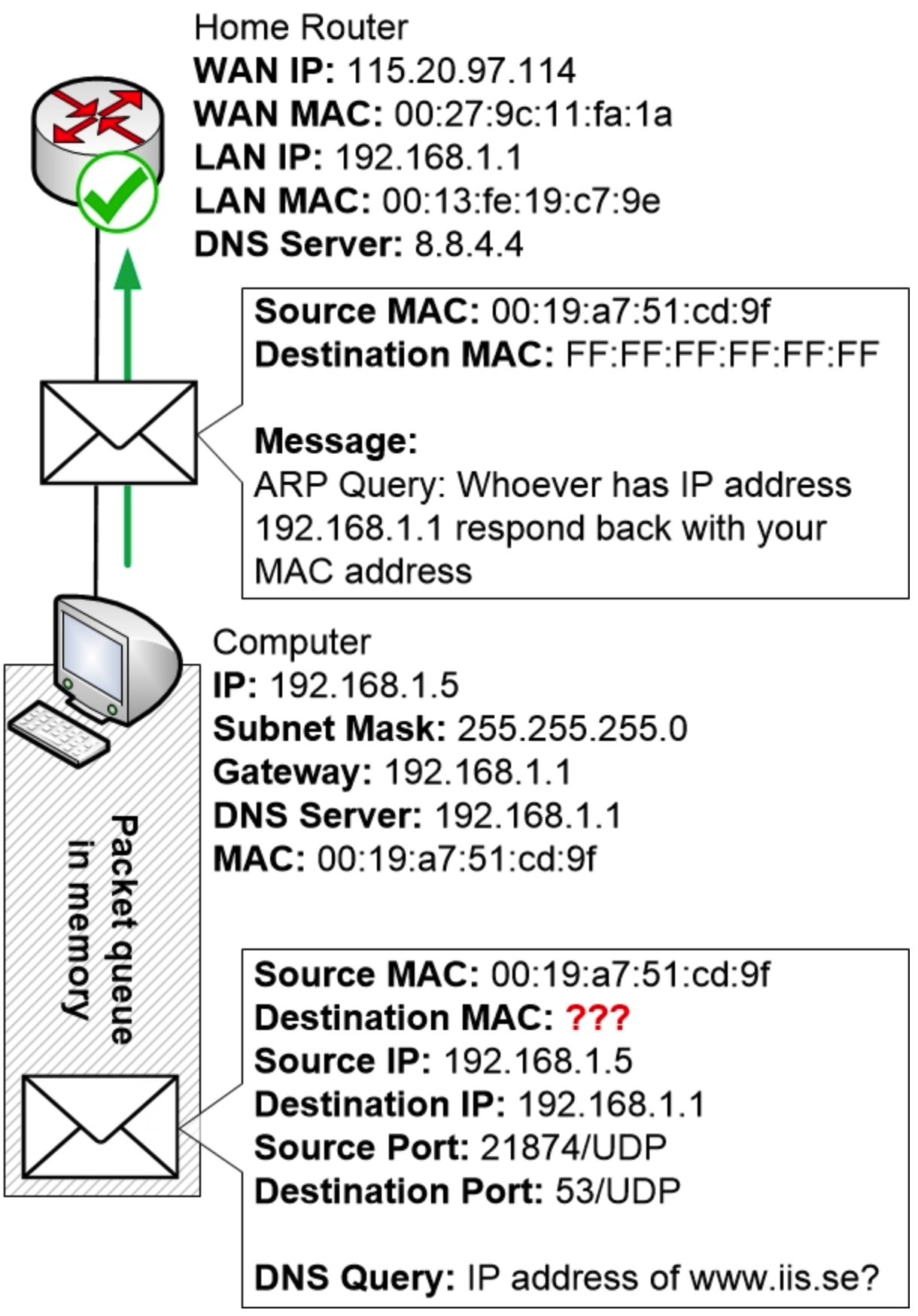
家用路由器收到ARP请求并读取消息,因为该请求发送到了广播MAC地址FF:FF:FF:FF:FF:FF。
家用路由器可以从消息中看到计算机正在请求 IP 地址为 192.168.1.1 的设备。由于路由器配置为使用该 IP 地址,因此家用路由器将通过构建 ARP 应答并将其发送回计算机来响应此消息。
当计算机收到 ARP 回复时,操作系统会读取该回复。它会将回复添加到 ARP 表中,以便在几分钟内记住与 192.168.1.1 关联的 MAC 地址。
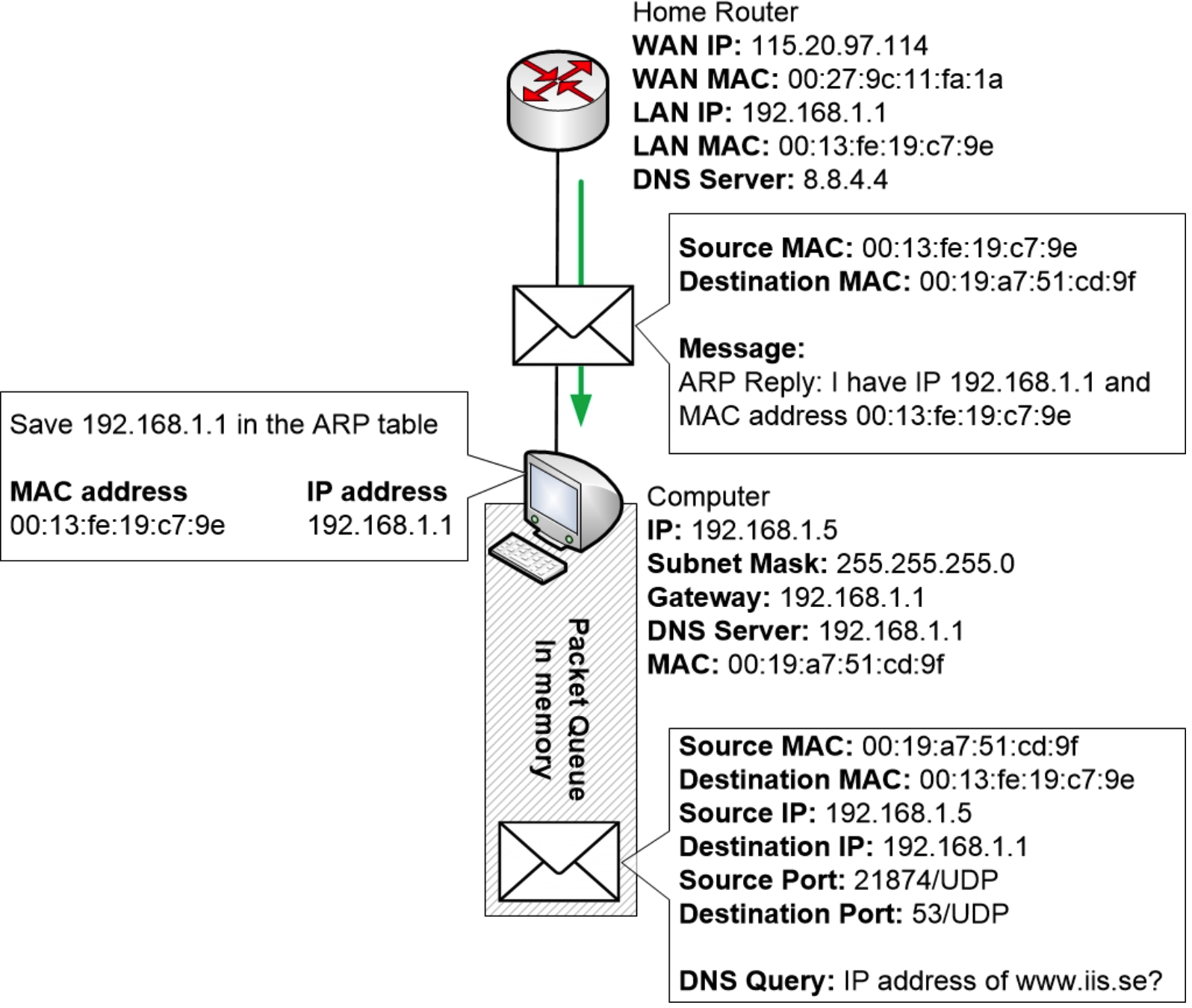
现在计算机终于收集到了发送 DNS 消息所需的所有信息。
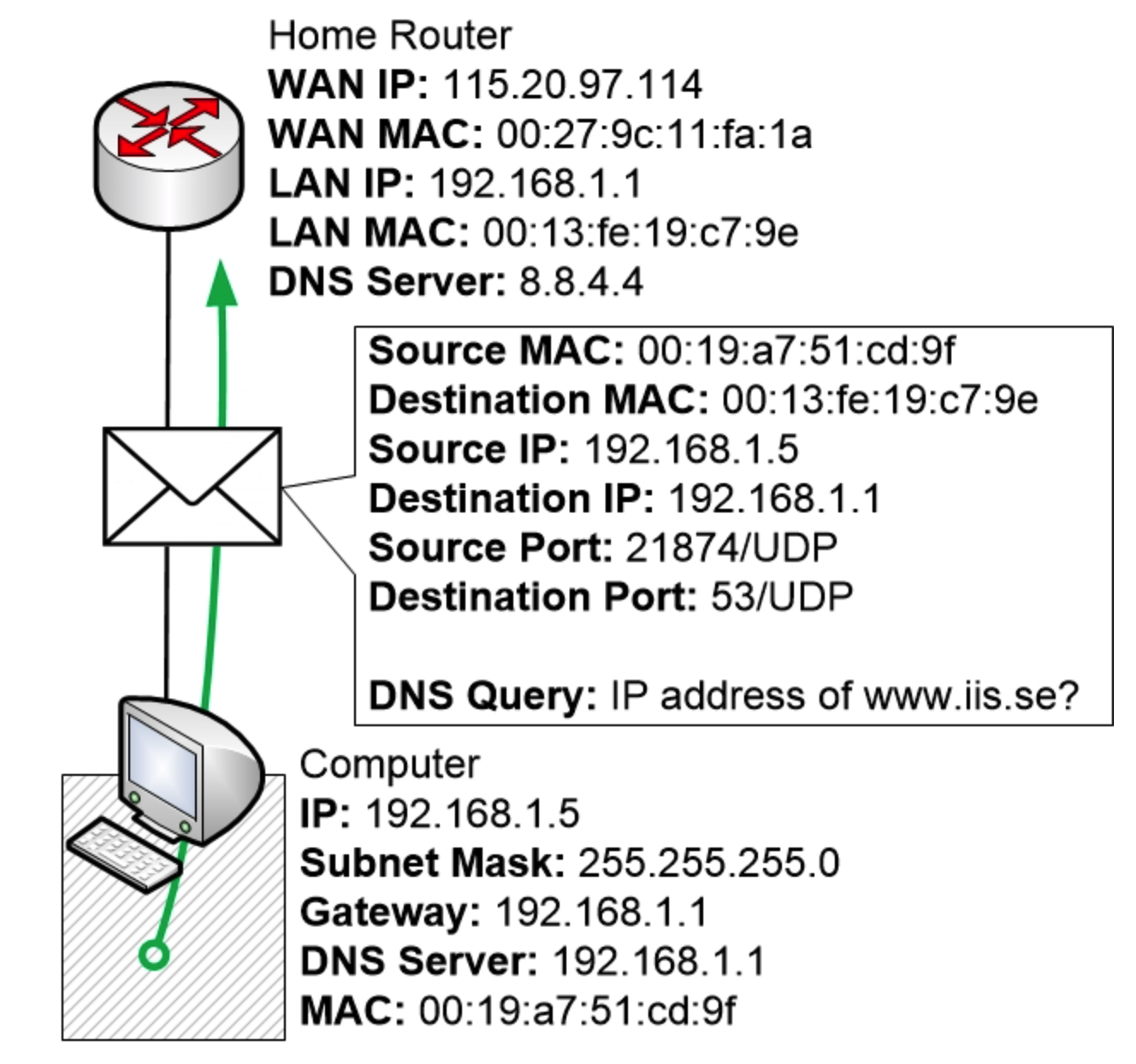
现在,计算机将向 DNS 服务器发送 DNS 查询,该服务器作为一项服务运行在家庭路由器 192.168.1.1 上。
家用路由器收到查询后,发现这是一个针对路由器自身 IP 地址和 MAC 地址的 DNS 查询,并意识到它必须处理这个 DNS 查询并发送一个答案。
家用路由器本身就是一个DNS服务器,但它也依赖于互联网上的其他DNS服务器。家用路由器不可能知道互联网上每一个DNS地址。因此,它会根据需要向负责不同域名(例如example.com)的DNS服务器发出请求。
家用路由器也像电脑一样配备了DNS缓存。每次家用路由器处理来自电脑的DNS查询时,它都会将DNS回复保存在自身的DNS缓存中一段时间。这样做是为了避免重复处理相同的DNS查询,从而加快响应速度。
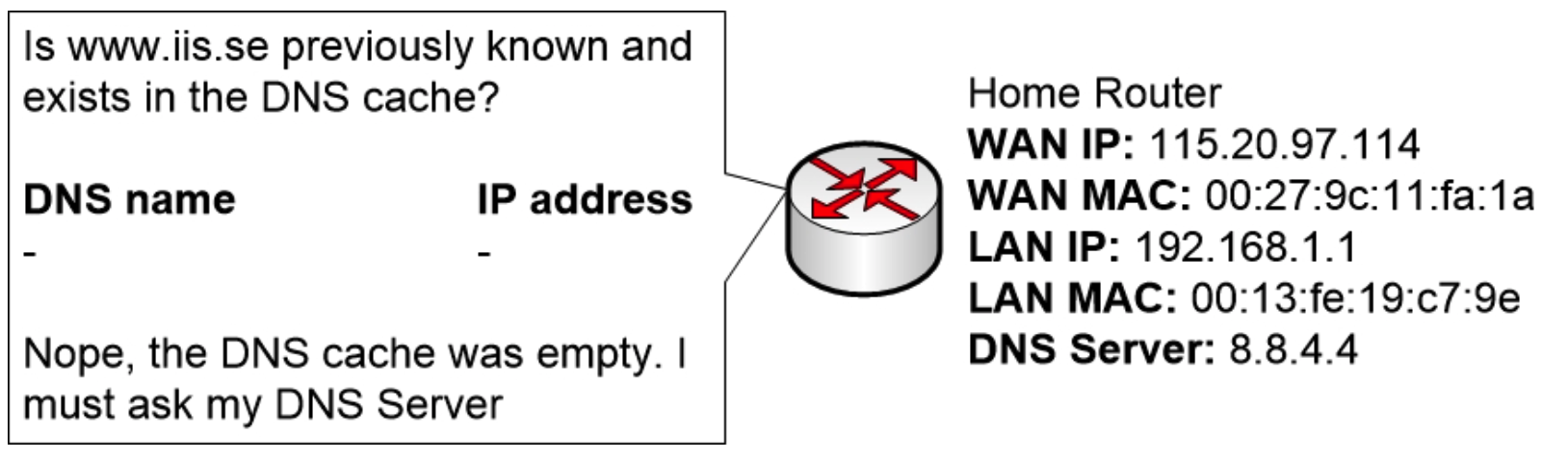
在这种情况下,家用路由器很久没有收到关于www.iis.se 的查询,因此路由器的 DNS 缓存中不存在该域名。所以,路由器必须向其配置的互联网 DNS 服务器请求解析此 DNS 查询。
现在,路由器准备向其 DNS 服务器发送 DNS 查询。路由器在首次启动并从互联网服务提供商 (ISP) 获取公网 IP 地址时,通过 DHCP 从 ISP 获知了可用的 DNS 服务器。
因此,家用路由器会准备一个DNS查询,方法是将查询信息封装在一个UDP消息中,目标端口为53/UDP,源端口为随机UDP端口。然后,它会将该消息封装到一个IP数据包中。该IP数据包会从家用路由器的公网IP地址发送到DNS服务器地址。
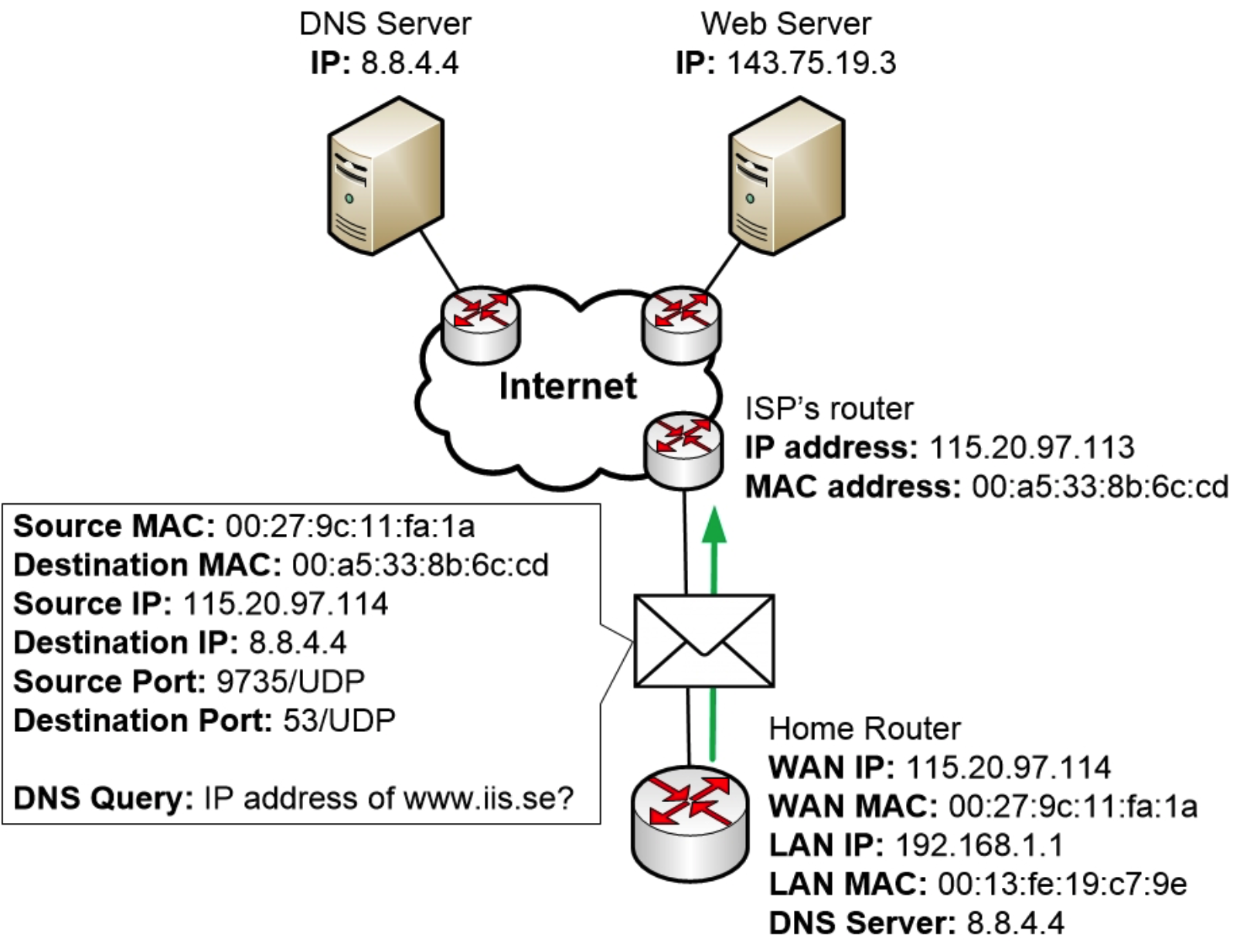
当家用路由器准备好数据包并准备发送时,它会查看路由表以确定发送路径。路由表显示,到达内部局域网 192.168.1.0 的最佳路径是通过 LAN 端口,但此数据包需要发送到互联网上的另一个 IP 网络。因此,家用路由器选择 WAN 端口作为最佳目标地址。
在此阶段,家用路由器可能需要执行 ARP 请求来查找下一跳路由器 115.20.97.113 的 MAC 地址,但我们假设家用路由器已经在其 ARP 缓存中获得了此信息。
这里的一些步骤已经过简化和缩短。
互联网上每个接收到 DNS 请求的路由器都会执行以下操作:
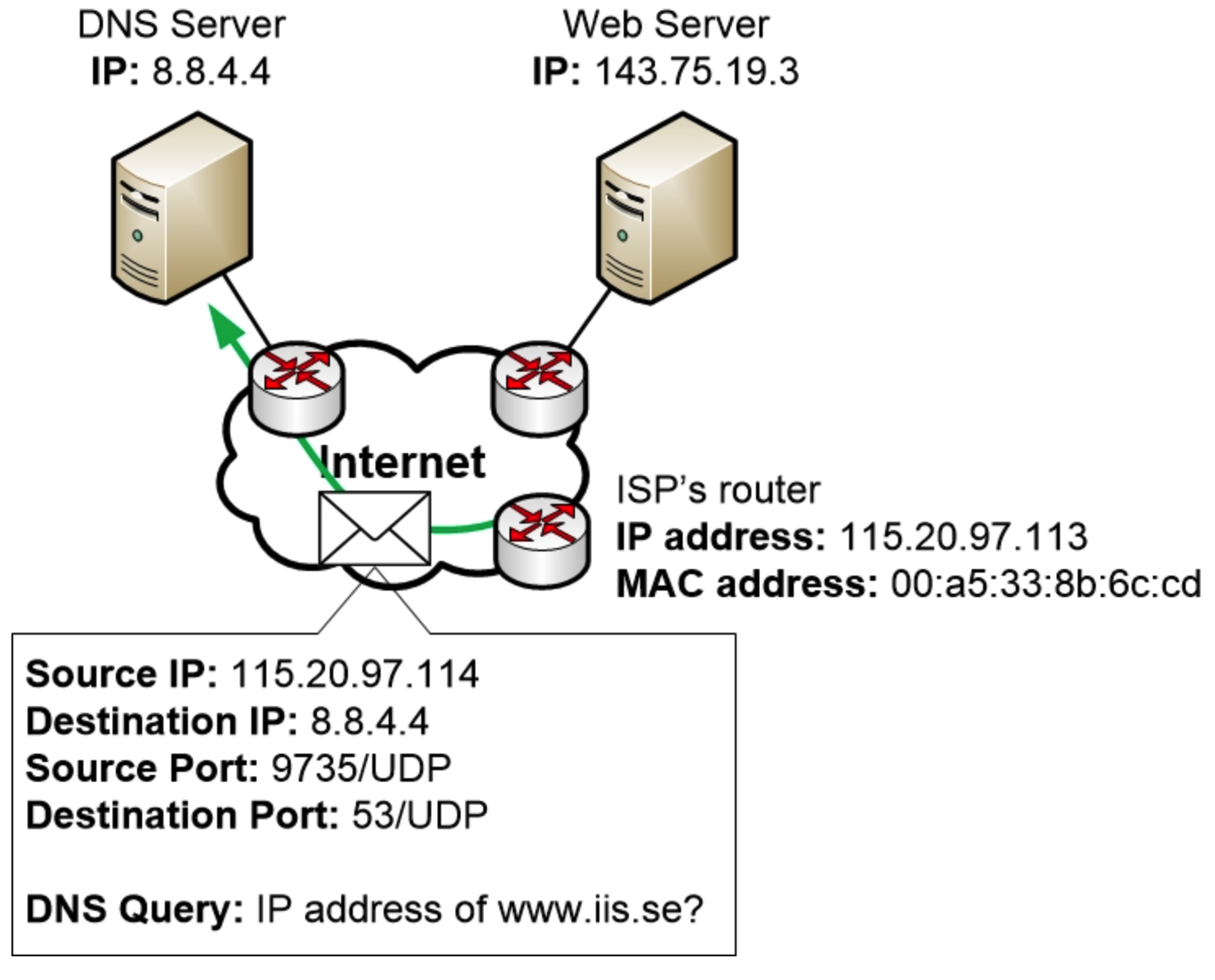
最终,数据包到达 DNS 服务器,DNS 服务器将处理该数据包并准备响应。
就像普通电脑一样,服务器也有IP地址、子网掩码和默认网关。因此,它的工作方式与普通电脑非常相似。
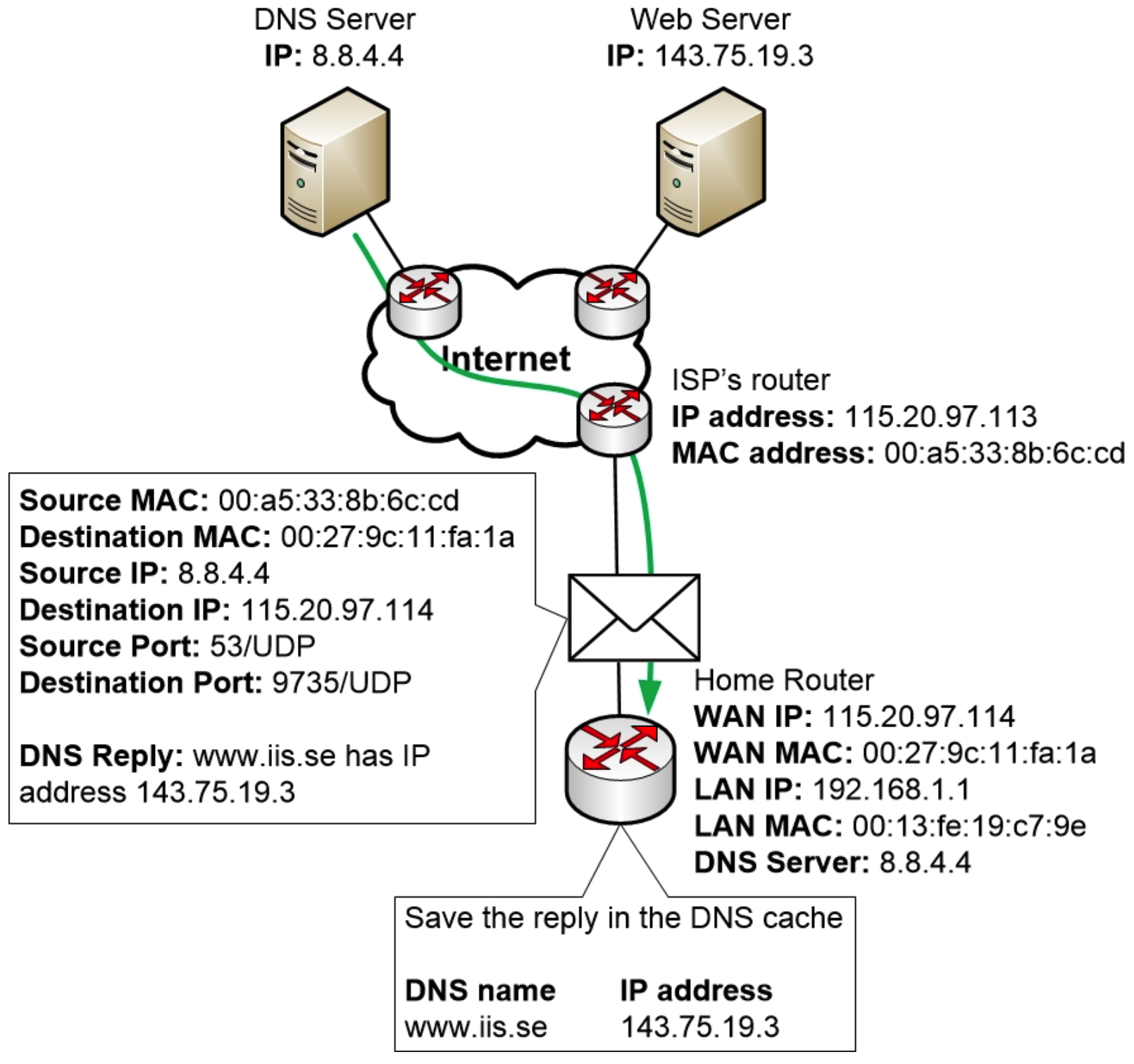
现在,在收到来自 DNS 服务器的 DNS 回复后,家用路由器终于可以创建 DNS 回复并将其发送到计算机,以便让计算机知道www.iis.se的 IP 地址。
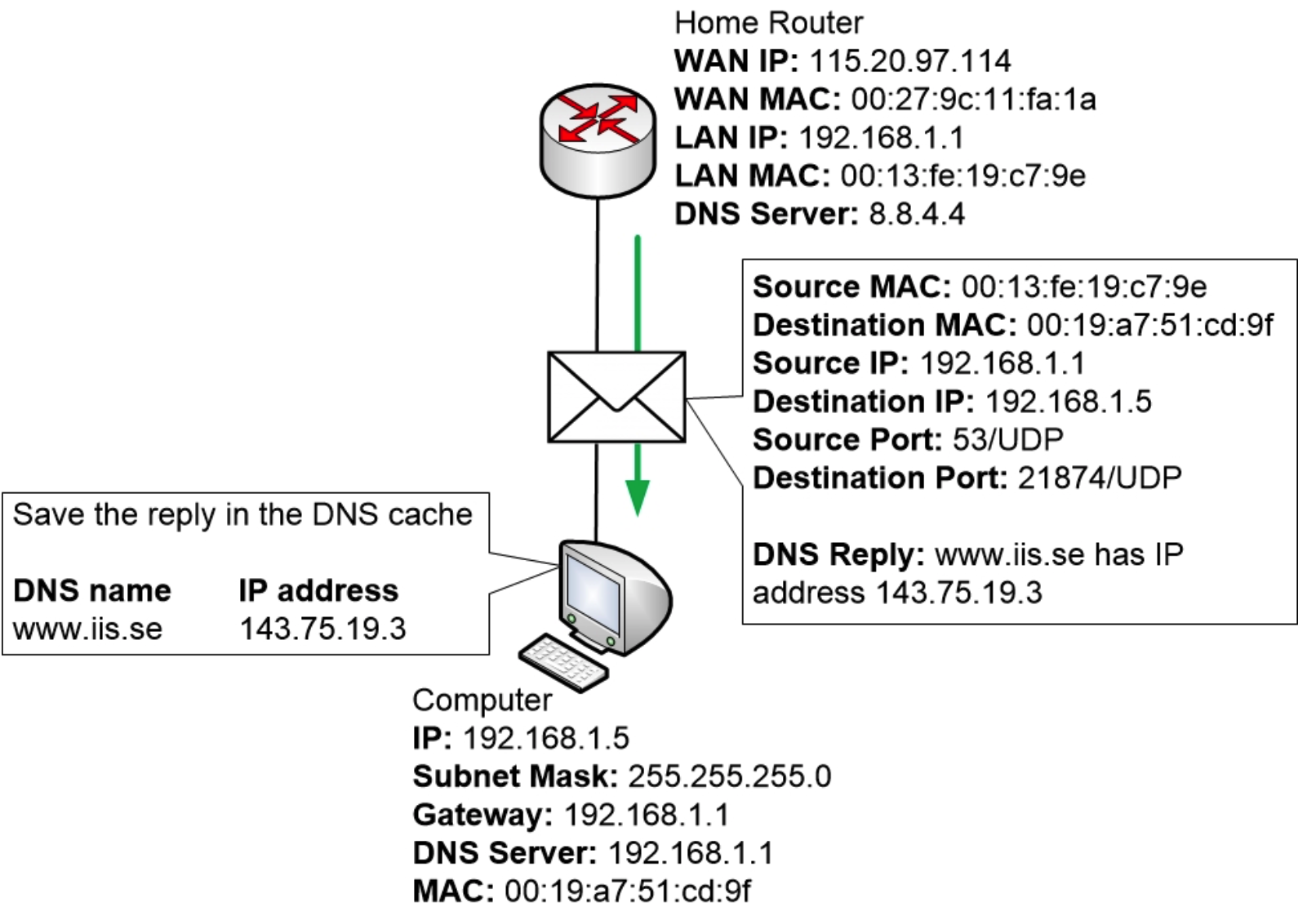
在这个阶段,很多事情同时发生。
计算机主要会启动一个名为“TCP 三次握手”的过程,这是 TCP 通信的建立阶段,包含计算机和服务器之间的三条消息。在使用 TCP 时(例如网页浏览),TCP 会尽力确保一切运行正常,包括通过握手建立会话。这样做是为了让服务器做好接收会话的准备,并确定通信应使用的端口。
TCP 三次握手由三条消息组成:
计算机的ARP缓存中已经存储了家庭路由器IP地址的正确ARP信息。因此,计算机可以通过家庭路由器向互联网发送任何数据包,而无需事先进行ARP查找。
但这也是本例中计算机首次尝试直接与路由器之外的物体通信。TCP 三次握手将在计算机和互联网上的 Web 服务器之间直接进行。
在之前的DNS查找过程中,计算机只是与家用路由器通信。家用路由器再与互联网上的DNS服务器通信。但计算机与互联网上的任何IP地址之间并没有直接通信。
区别在于,现在计算机想要直接与互联网上的某些内容通信,那么家用路由器就必须对流量执行地址转换。
接下来,我们将仔细研究计算机通过初始化 TCP 三次握手来建立 TCP 会话时发生的情况。
为此,计算机操作系统会随机生成一个用于通信的 TCP 源端口。然后,它会组装 TCP SYN 消息并将其发送到 Web 服务器。该 TCP 消息不包含任何其他数据,它只是一个空的 TCP 消息。
当 TCP SYN 消息通过路由器时,路由器会对该消息执行 NAT 转换。路由器还会将执行的 NAT 转换信息保存在其 NAT 表中,以便跟踪会话并对任何回复执行反向 NAT 转换。
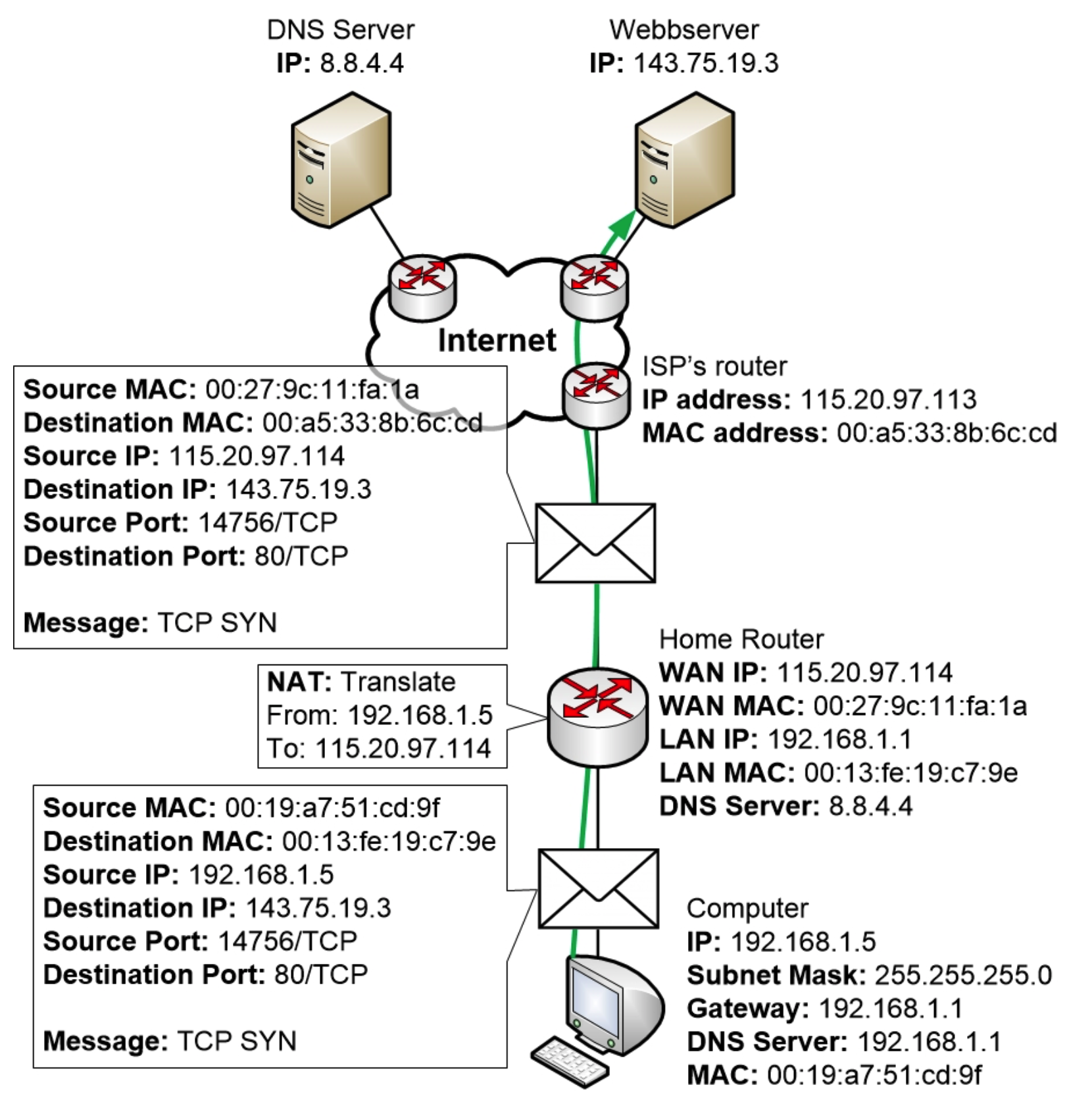
图片显示的是从计算机到Web服务器的TCP SYN数据包。
这里可以看到 Web 服务器返回给计算机的 TCP SYN-ACK 响应:
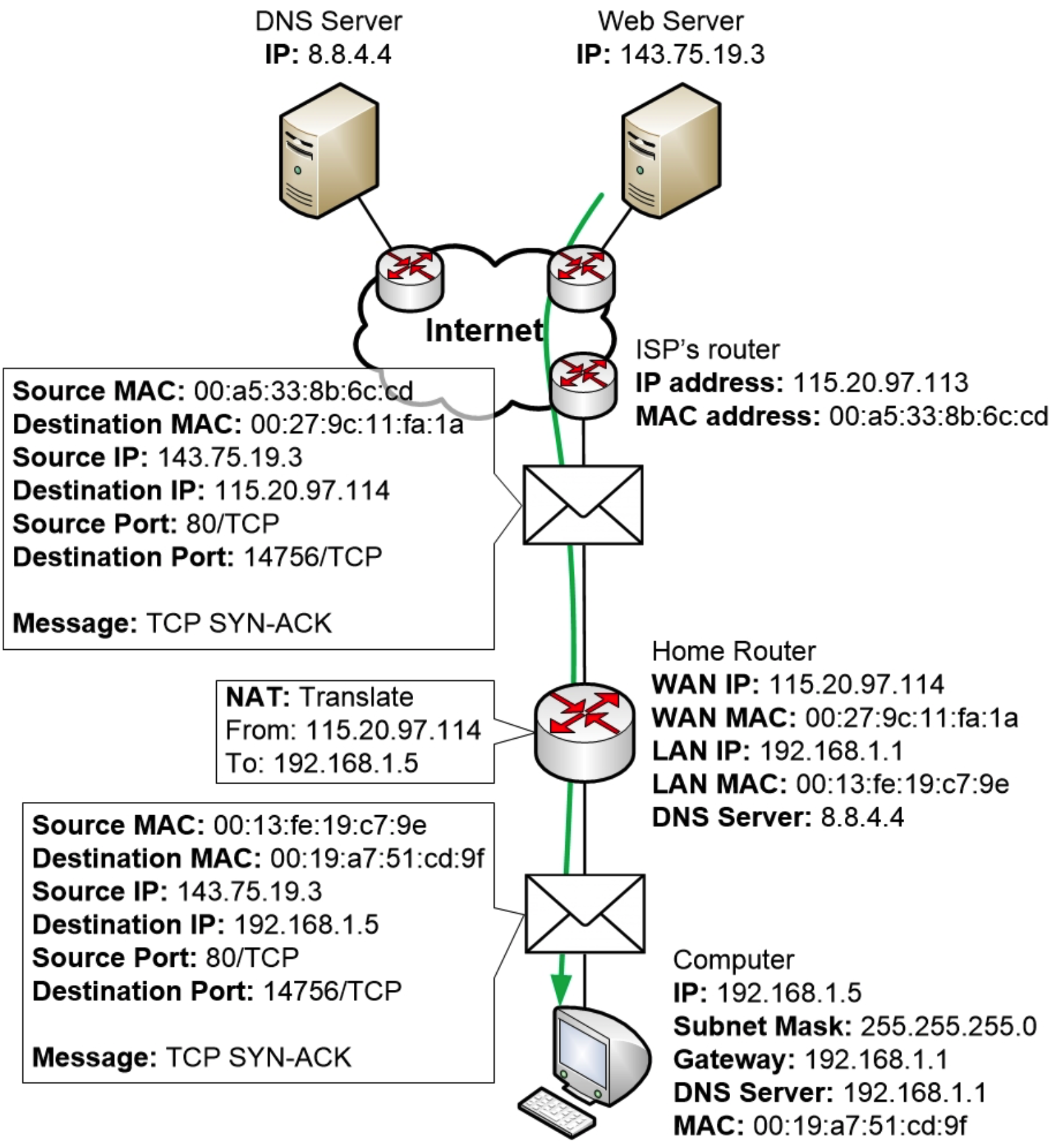
该数据包与路由器上的 NAT 表条目匹配,以便路由器能够看到应该将数据包转发到哪个 LAN 计算机以及如何对数据包执行 NAT。
最后,计算机向Web服务器发送TCP ACK确认包。
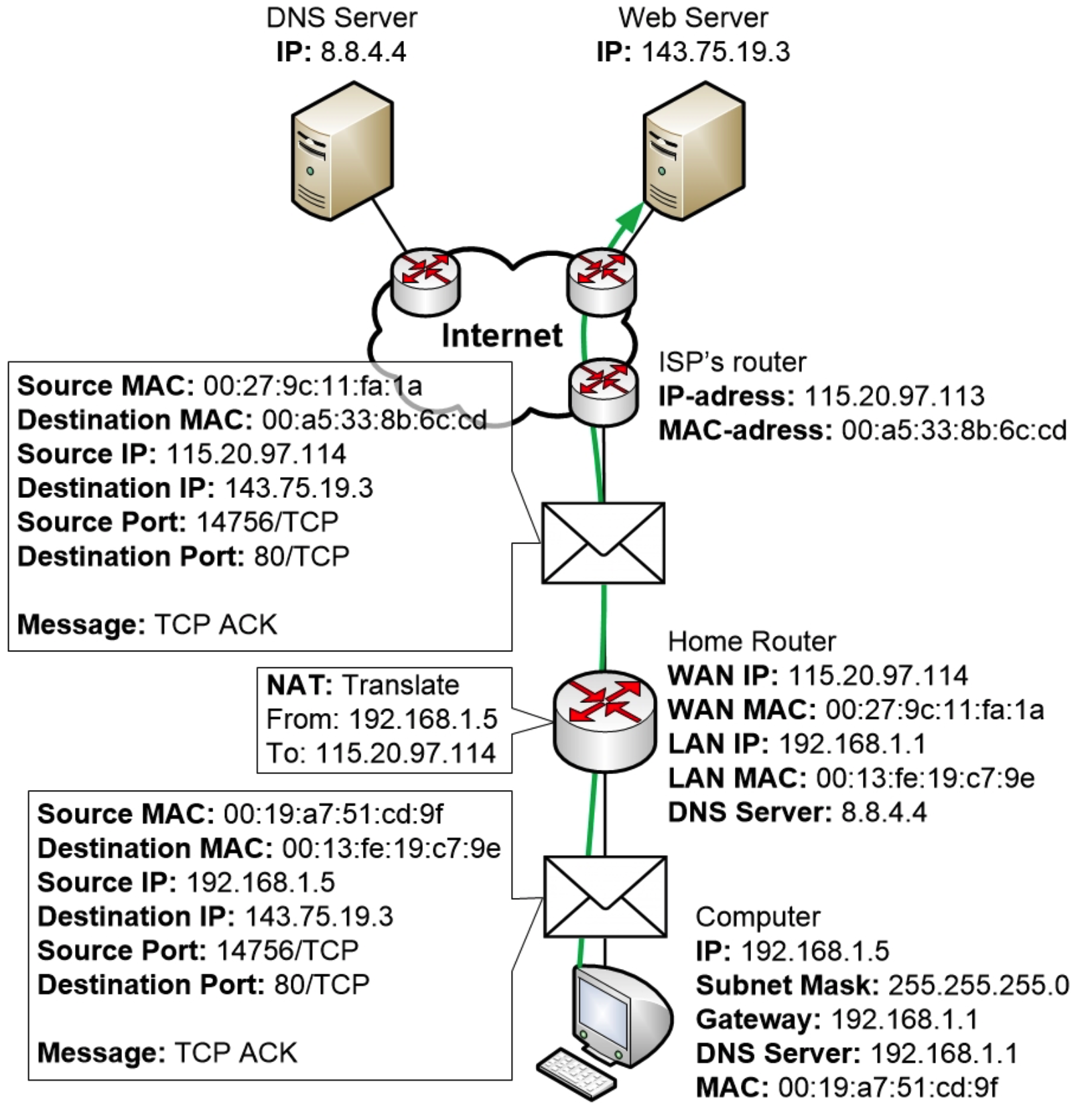
只要计算机和服务器持续通信,它们就会一直使用同一个会话进行通信。这包括使用相同的TCP端口,这样沿途的所有设备都能跟踪会话、地址转换等信息。
会话可能只持续足够长的时间以下载网页,或者网络服务器和计算机可以选择保持会话更长时间,以防用户想要继续浏览网页。
一旦操作系统建立了 TCP 会话,操作系统就会通知 Web 浏览器现在可以开始与 Web 服务器通信了。
网络浏览器会使用HTTP协议来实现这一点,HTTP协议是互联网上传输网页的标准协议。
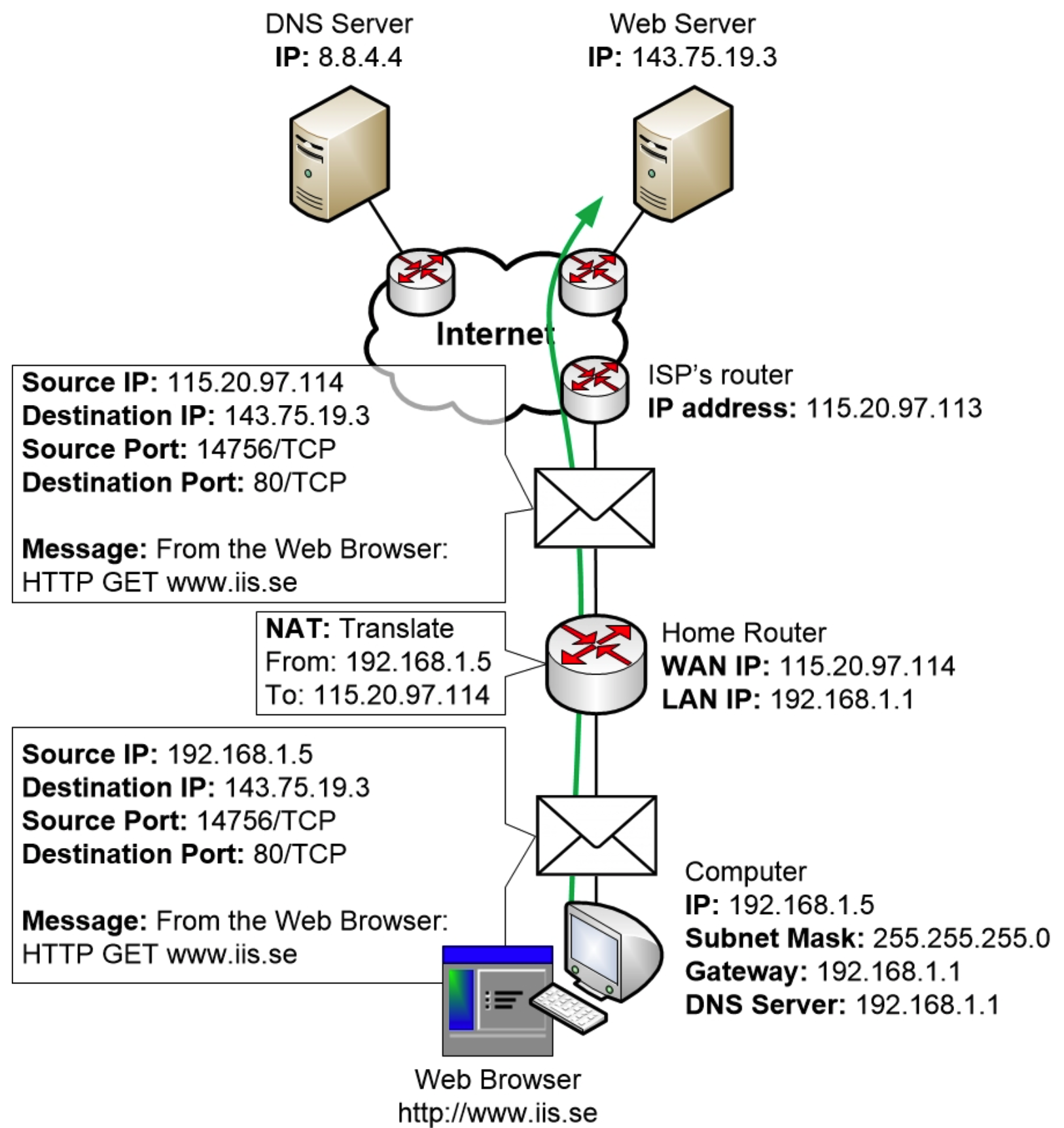
这也意味着我们已经完成了示例,其中包括建立通信的大部分步骤。从现在开始,计算机和服务器可以相互通信以传输网页,直到传输完成。然后,它们可以选择发送所谓的 TCP RESET 消息来结束会话,该消息会通知所有设备会话已结束。