将Roon引入我的听音系统的一些经验 系统迁移 我对之前的听音系统还是比较满意的,我并不是发烧友,当系统的音质能达到一定程度,剩下的就是音乐欣赏的事情了。
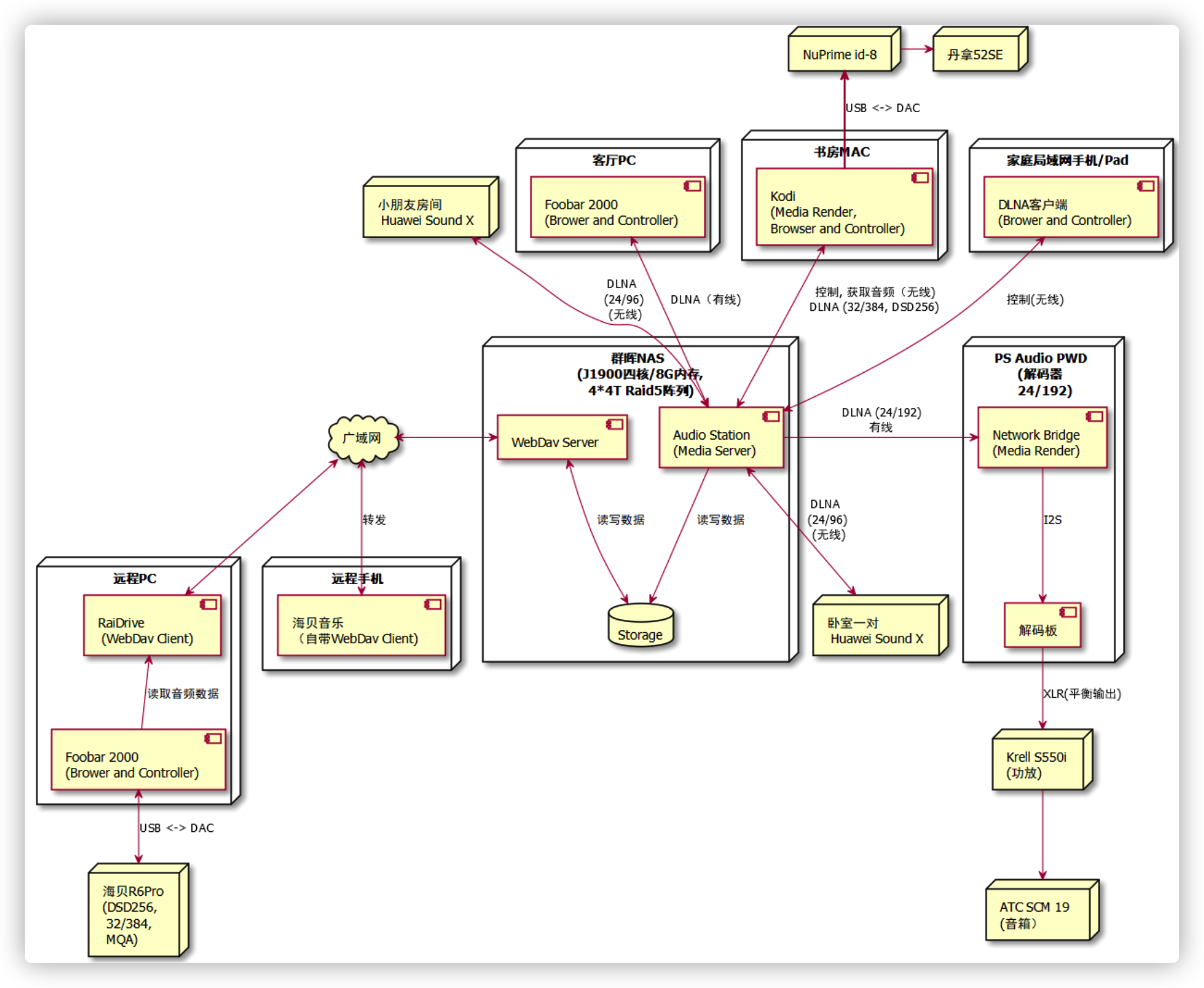
我之前听音系统的网络拓扑 我之前的听音系统终端并没有归一,音频的流动主要以DLNA为主,因为解码器的Bridge卡作为Render,内部通过I2S输入解码板,效果非常好,我又不想折腾各种USB,同轴,光纤的连接,线材不菲且完全不在我的知识范围内。
群晖NAS作为Media Server, 解码器,Mac软件,智能音箱作为Render,电脑、手机和Pad的软件作为Browser和Controller
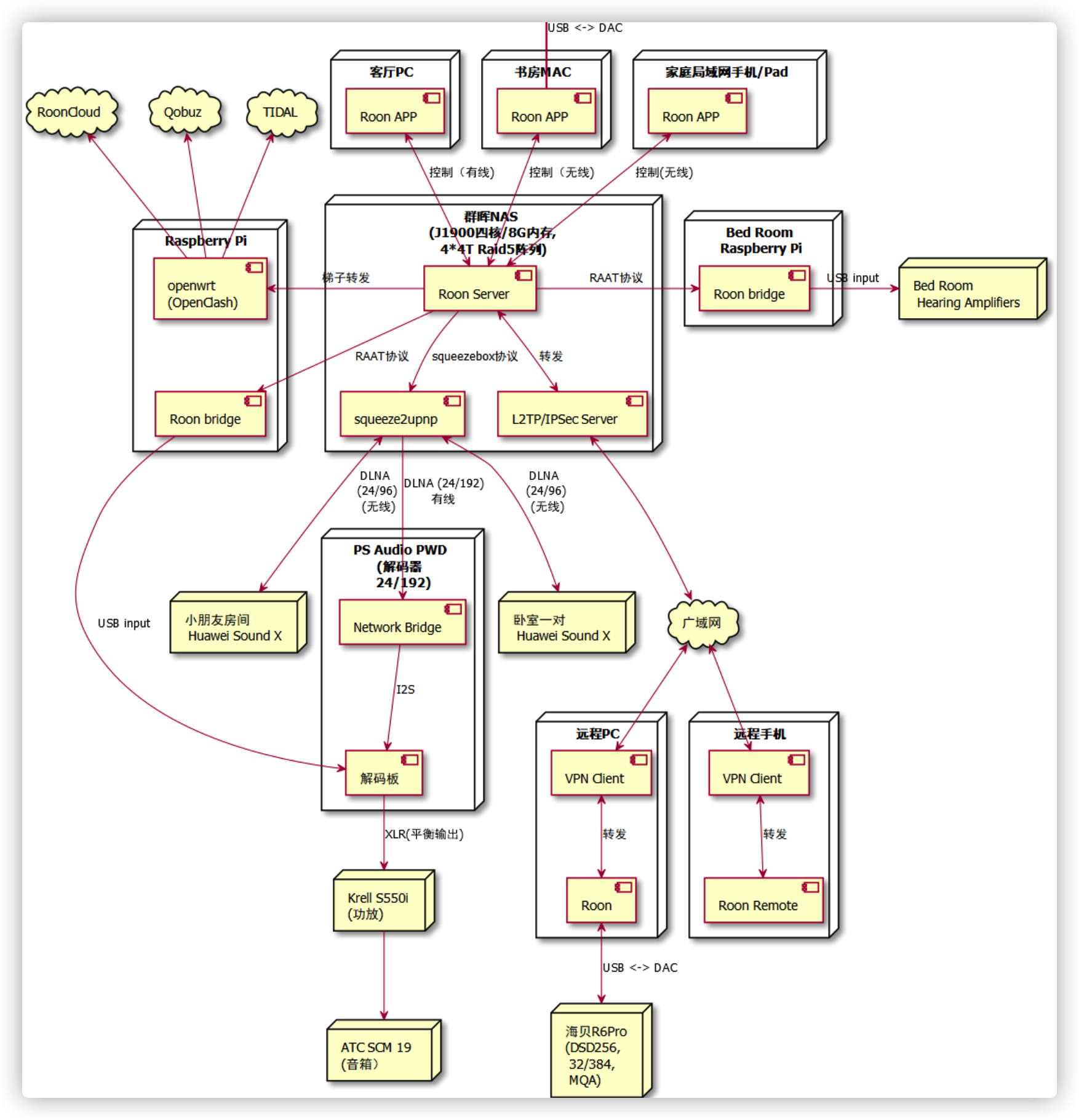
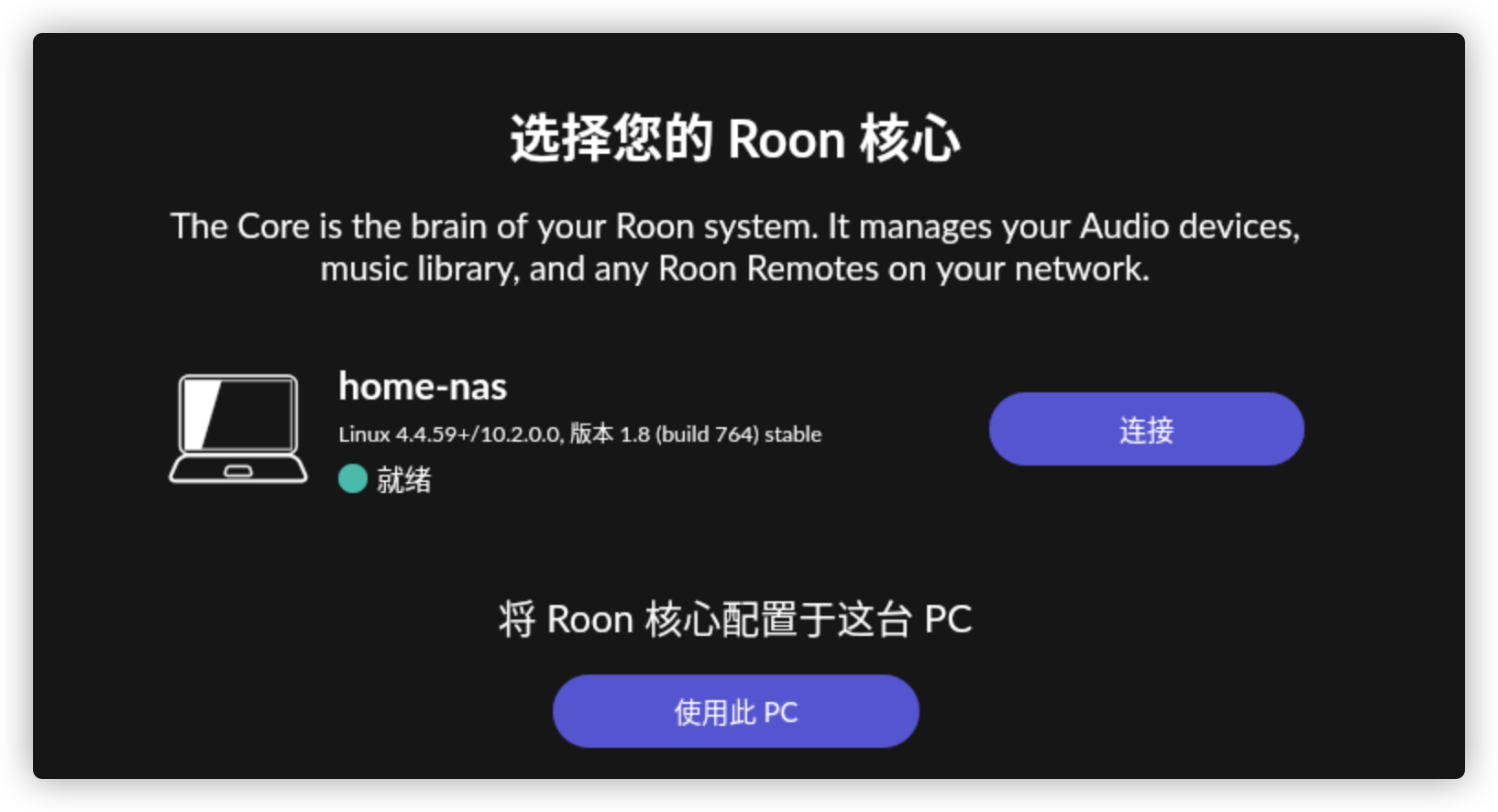
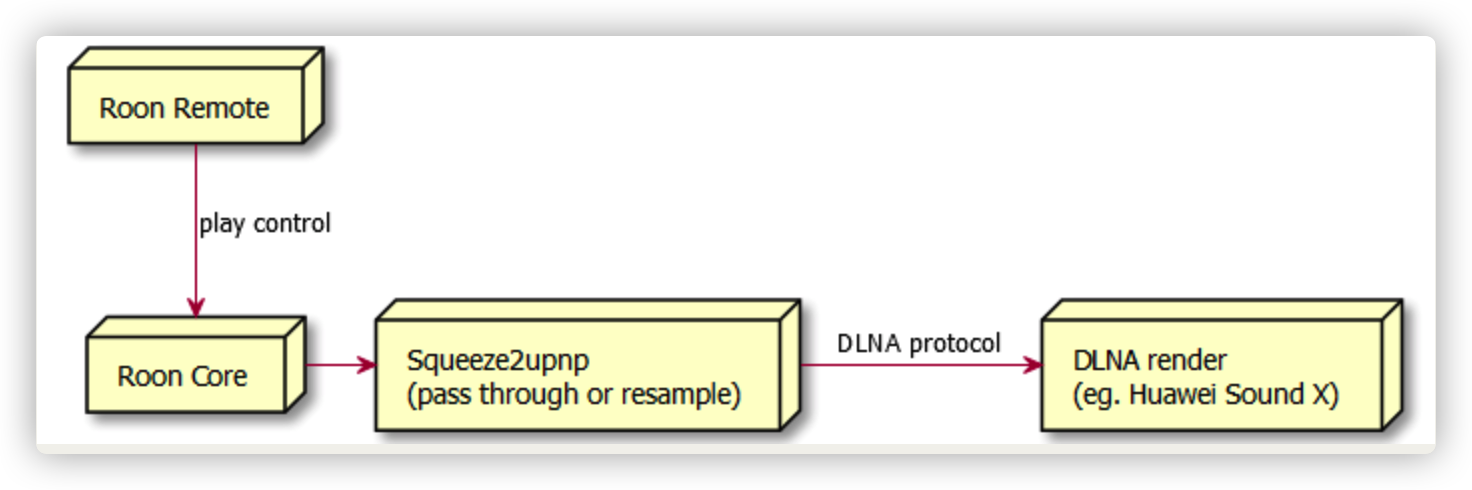
引入Roon后听音系统网络拓扑 Roon的帐号挺贵的,加上我对原来的硬件还算满意,所以想最大限度的利用,思想就是用Roon Core管理音乐,同时将Roon的RAAT协议都转为DLNA,复用现有的设备。 电脑、手机、平板的客户端都统一到Roon Remote。
感谢philippe开发的SqueezeBox桥接到Upnp的软件squeeze2upnp,使得我复用原有DLNA系统的想法成为了可能,而且他对待用户的反馈是否友好,耐心解答并能很快做出修改。
安装Roon
在这个网站下载群晖NAS的套件 : https://roononnas.org/de/synology-2/
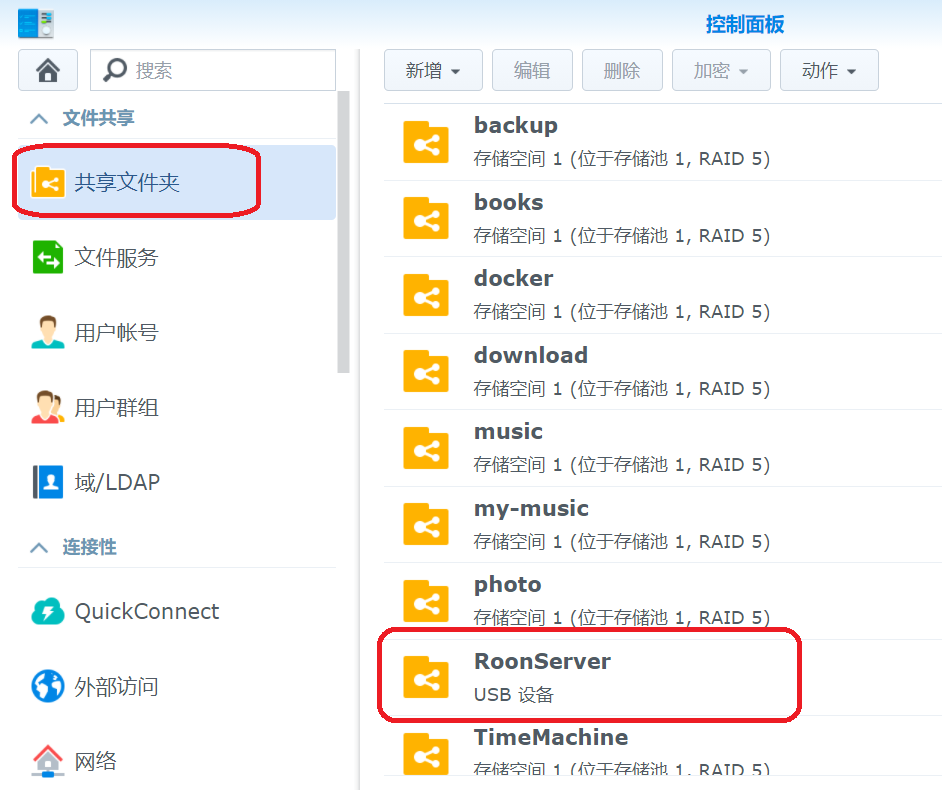
在共享文件夹中创建一个名字叫”RoonServer”的共享目录
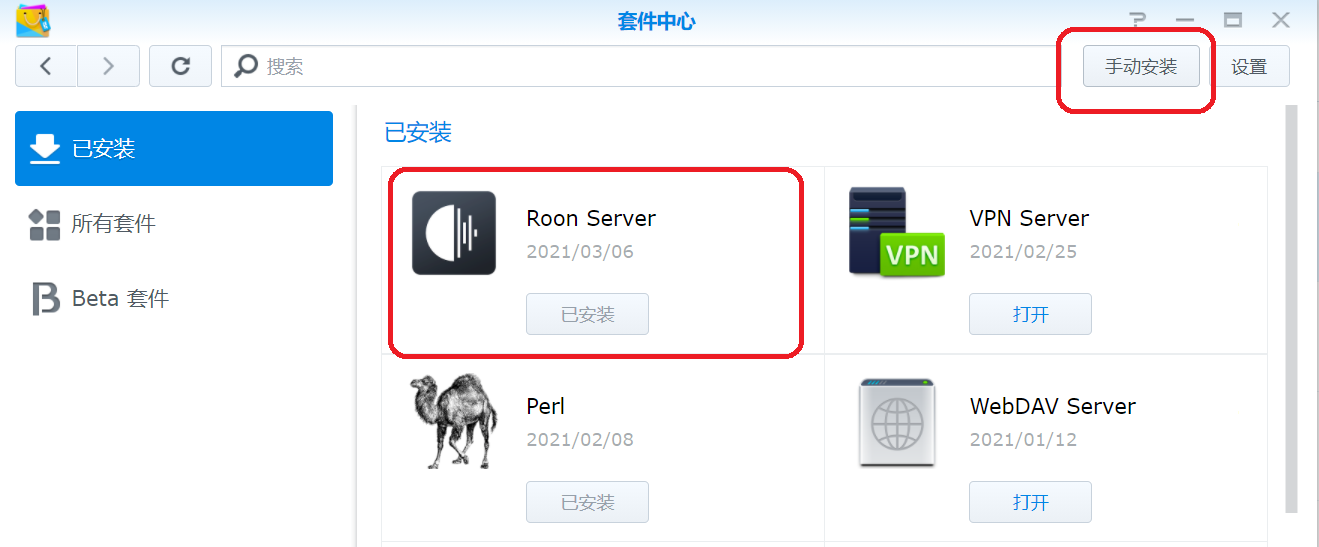
选择手动安装套件,安装过程比较长
手机,PC, MAC, Pad的客户端可以参考官网安装:https://roonlabs.com/downloads
以Windows为例,在PC上启动Roon,就回发现群晖NAS的Core,连接就可以使用
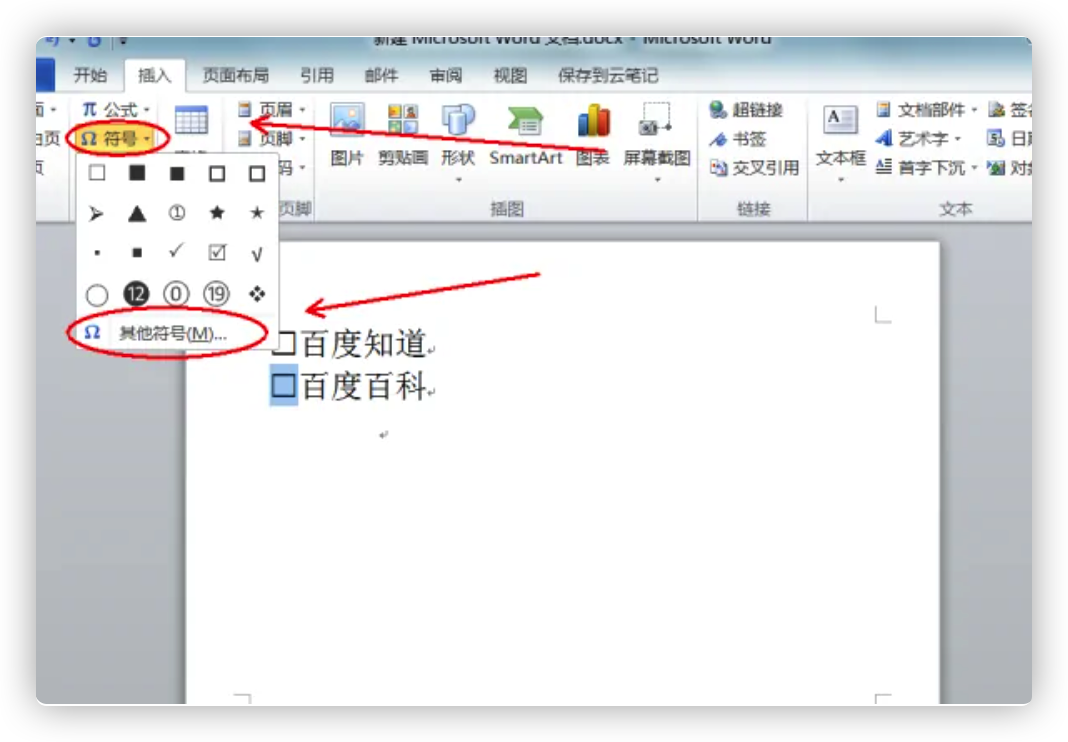
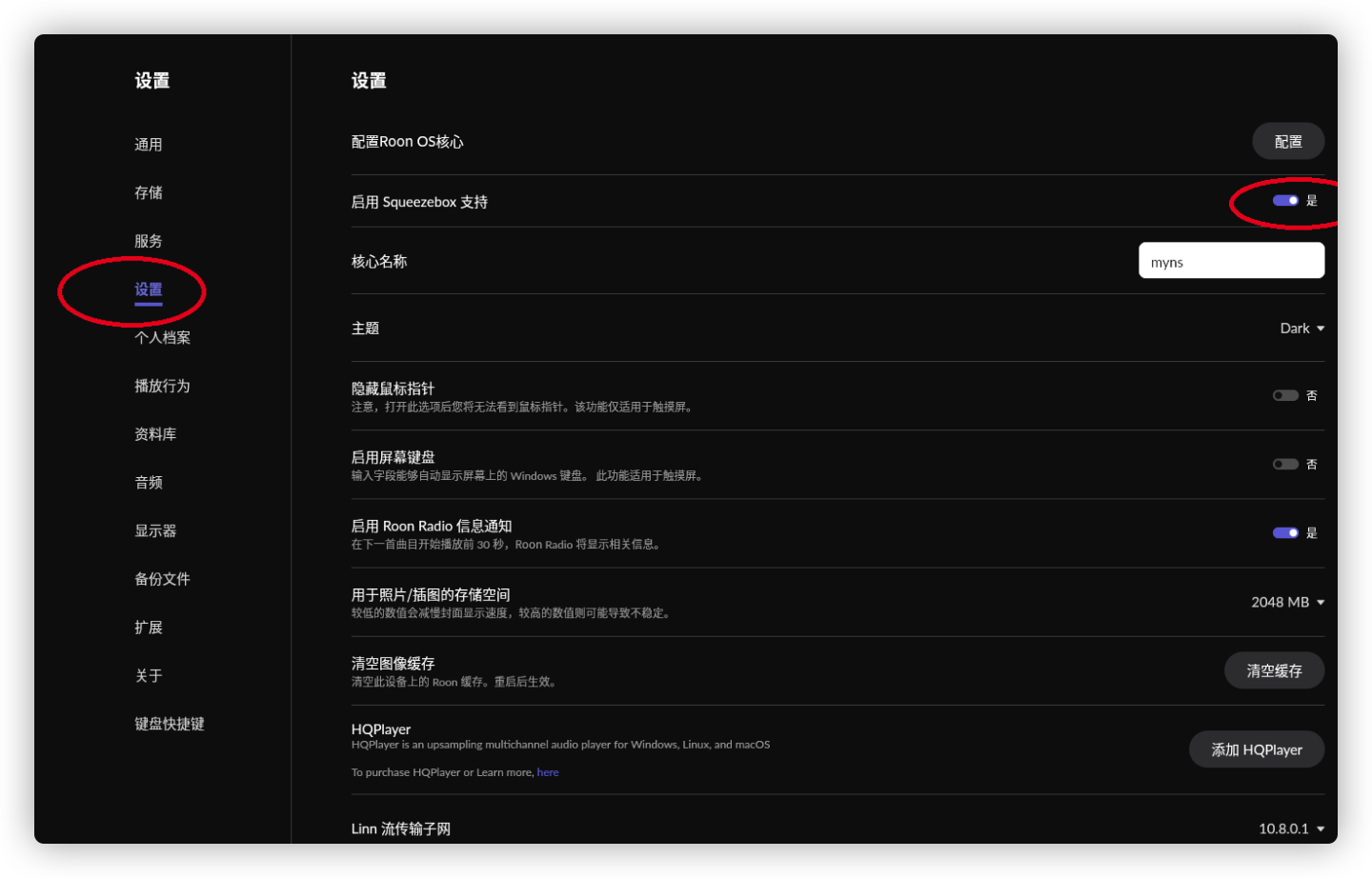
如何为Roon增加DLNA输出 Roon本身不支持输出,但是支持Squeezebox设备(就是LMS(Logitech Media Server)体系)
下图就是在Roon设置中打开对squeezbox的支持。
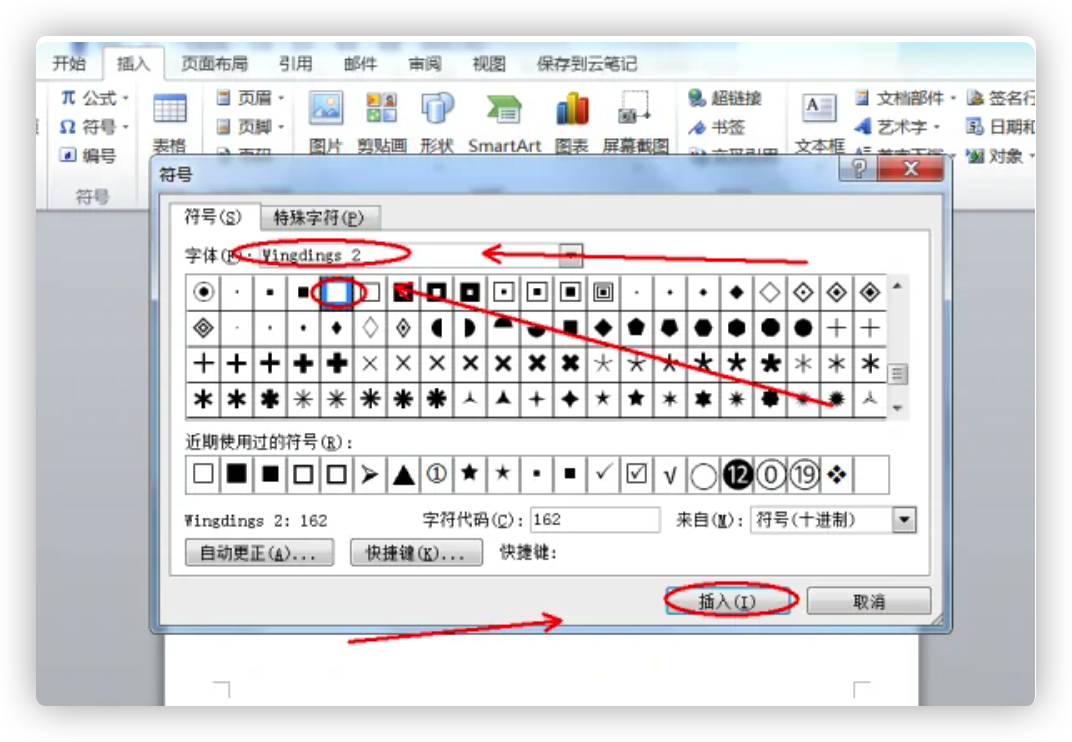
打开SqueezeBox设置
接下来的思路就是做一个桥,将Roon使用Squeezebox协议输出的音频转成DLNA的协议
使用这个软件实现:Squeeze2upnp,他的目的就是将DLNA设备变成SqueezeBox设备
软件github地址:https://github.com/philippe44/LMS-to-uPnP
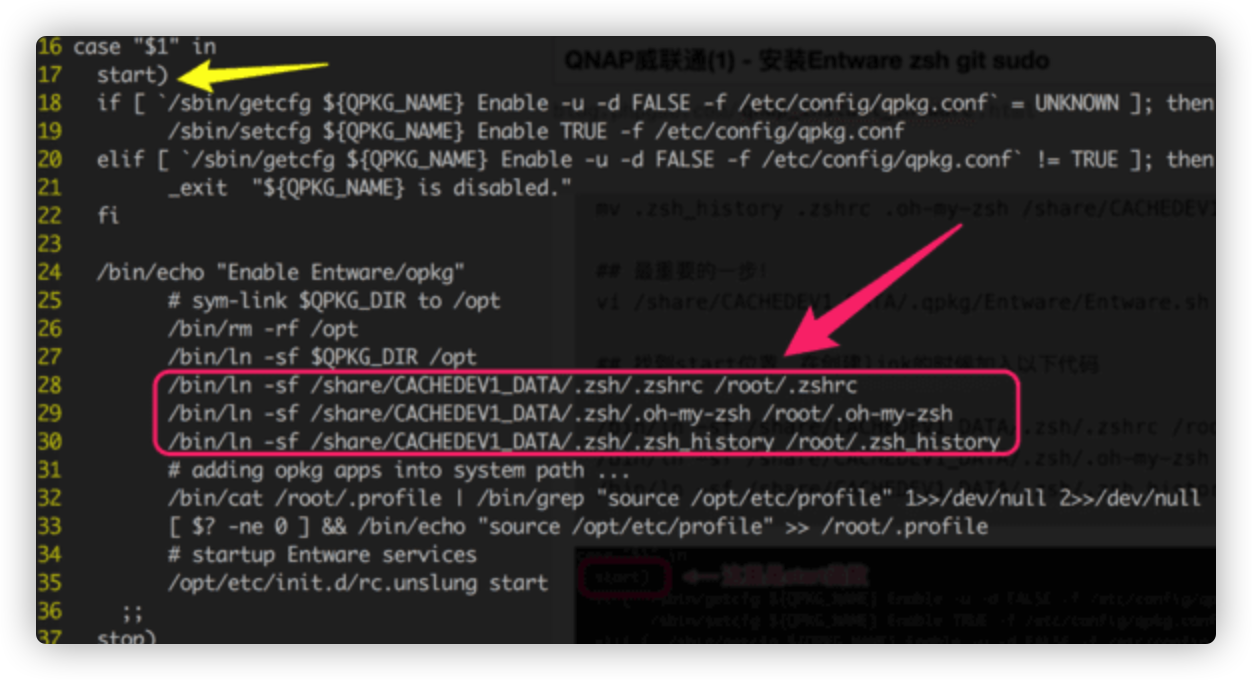
安装 安装非常简单,从github网址给出的下载网站下载最新的安装包解压即可。
!!!重要,需要安装1.49.8之后的版本,这之前的版本不支持Huawei Sound,我和作者squeeze2upnp的作者philippe反馈后并提供日志后,他经过修改,新出了版本用于支持Huawei Sound
安装包解压后有一个Bin目录,所有平台的可执行文件都在里面。
1 2 3 4 5 ls ./Bincc32160mt.dll libmad-0.dll libopusfile-0.dll pthreadBC2.dll squeeze2upnp-armv5te-static squeeze2upnp-bsd-x64-static squeeze2upnp-ppc-static squeeze2upnp-x86 ssleay32.dll libeay32.dll libogg-0.dll libsoxr.dll squeeze2upnp-aarch64 squeeze2upnp-armv6hf squeeze2upnp-osx-multi squeeze2upnp-sparc squeeze2upnp-x86-64 libfaad2.dll libogg.dll libvorbis.dll squeeze2upnp-aarch64-static squeeze2upnp-armv6hf-static squeeze2upnp-osx-multi-static squeeze2upnp-sparc-static squeeze2upnp-x86-64-static libFLAC.dll libopus-0.dll libvorbisfile.dll squeeze2upnp-armv5te squeeze2upnp-bsd-x64 squeeze2upnp-ppc squeeze2upnp-win.exe squeeze2upnp-x86-static
尽管Squeeze2upnp是LMS的一个插件,但是他并不依赖LMS,可以独立运行。解压后在Bin目录下后缀为_static的可执行程序都是独立执行程序
Squeeze2upnp支持Windows, OSX, or Linux x86/64, ARM and OSX
可以从可执行的程序名中看出哪个可执行程序对应什么平台。
例如树莓派,你可以选择 : squeeze2upnp-armv6hf-static
对于Linux,对应你平台的执行文件需要增加可执行属性,例如
1 chomd a+x squeeze2upnp-x86-64-static
以下描述以都以群晖NAS为例,其他的平台将命令中的可执行程序替换为对应平台的执行程序即可。
DLNA设备发现 对于第一次使用,或者希望重新创建一个配置文件,需要执行以下命令:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 ./Bin/squeeze2upnp-x86-64-static -i config.xml [22:18:38.897023] main:1756 Starting squeeze2upnp version: v1.49.6 (Feb 13 2021 @ 14:45:36) [22:18:38.904985] main:1764 !!!!!!!!!!!!!!!!!! ERROR LOADING CONFIG FILE !!!!!!!!!!!!!!!!!!!!! [22:18:38.943266] Start:1518 Binding to 192.168.1.100:49152 (http:0) [22:18:39.363148] AddMRDevice:1405 [0xc41840]: adding renderer (HUAWEI Sound-0286) [22:18:39.363354] AddMRDevice:1418 [0xc41840]: cannot get mac HUAWEI Sound-0286, creating fake fcceaf23 [22:18:39.371278] MasterHandler:1036 [0xc41840]: subscribe success [22:18:39.395668] AddMRDevice:1405 [0xc43a58]: adding renderer (LIVINGROOM) [22:18:39.395813] AddMRDevice:1418 [0xc43a58]: cannot get mac LIVINGROOM, creating fake 13a64ae6 [22:18:39.428824] MasterHandler:1036 [0xc43a58]: subscribe success [22:19:00.344578] Stop:1540 stopping squeezelite devices ... [22:19:00.344673] Stop:1544 terminate update thread ... [22:19:00.344770] Stop:1549 terminate main thread ... [22:19:00.344824] Stop:1553 stopping UPnP devices ...
等程序执行完,就会生成一个基础配置文件(config.xml,这个名字可以按照你的指定更换),里面包括默认配置和发现的你的局域网的DLNA设备。
其中…段是针对你所有设备的通用配置
每个发现的设备都有一个…段,你可以在段中设置和common中相同的参数,这个参数会针对这个设备覆盖common参数。
以我的设备为例,生成的设备配置如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 <device > <udn > uuid:b8aabe2db4df5481eb8b4f4cf3f302eac9a1539192127404166af840a41a0945</udn > <name > HUAWEI Sound-0286</name > <friendly_name > HUAWEI Sound-0286</friendly_name > <mac > bb:bb:23:af:ce:fc</mac > <enabled > 1</enabled > </device > <device > <udn > uuid:9166ce01-e4b5-4d56-8a1a-6a031b3b416b</udn > <name > LIVINGROOM</name > <friendly_name > LIVINGROOM</friendly_name > <mac > bb:bb:e6:4a:a6:13</mac > <enabled > 1</enabled > </device >
其中LIVINGROOM是我客厅的PS Audio PWD解码器,而HUAWEI Sound-0286则是卧室的Huawei智能音箱
接下来要对config.xml做一些简单的配置修改。例如, 在”common”段设置了设备最大支持48Khz采样率, 但是如果你的设备的最大采样率是192Khz,你可以在”device”段进行覆盖:
1 2 3 4 5 6 7 8 9 10 <common > ... <sample_rate > 48000</sample_rate > ... </common > <device > ... <sample_rate > 192000</sample_rate > ... </device >
尽管根据测试华为智能音箱支持24bit/192Khz,但是华为给出的规格是24bit/96Khz,所以建议还是把Huawei Sound的采样率设置为96Khz
每个被发现的设备的”enable”属性都是1,表示会为这个设备生成一个桥设备,在Roon设置里面的音频设备列表展现, 如果你不想在Roon中使用这个设备,就将enable设置为0.
“device”段里面有一个有个属性是DLNA Render的标识,类似:
1 <mac > bb:bb:e6:4a:a6:13</mac >
这是这个设备的标识,后续发现设备时,设备mac地址和这个段相同,就不会添加新的设备,并使用这个”device”设置的属性进行处理。
!!!!!!最重要的一点: 将roon_mode属性设置为1,否则Roon下可能不工作
1 <roon_mode > 1</roon_mode >
!!!!! **另外重要的一点,需要在Huawei Sound的”device”段中增加以下属性,否则会不能播放下一首,或者播放进度条不走
1 <accept_nexturi > 1</accept_nexturi >
后续有新设备发现,squeeze2upnp会为新设备增加一个device段到配置文件。如果你不想自动增加新设备(可能会造成问题),可以将”common”段的”enabled”属性设置为0
运行 测试运行:
1 squeeze2upnp-x86-64-static -x config.xml
调试信息会输出在终端
正式运行
1 ./Bin/squeeze2upnp-x86-64-static -z -x config.xml
要用-z参数在后台运行,否则即使使用Linux在后台运行,会占用一个CPU核的全部资源
然后需要开机启动就将上诉命令加入到/etc/rc.local 中即可
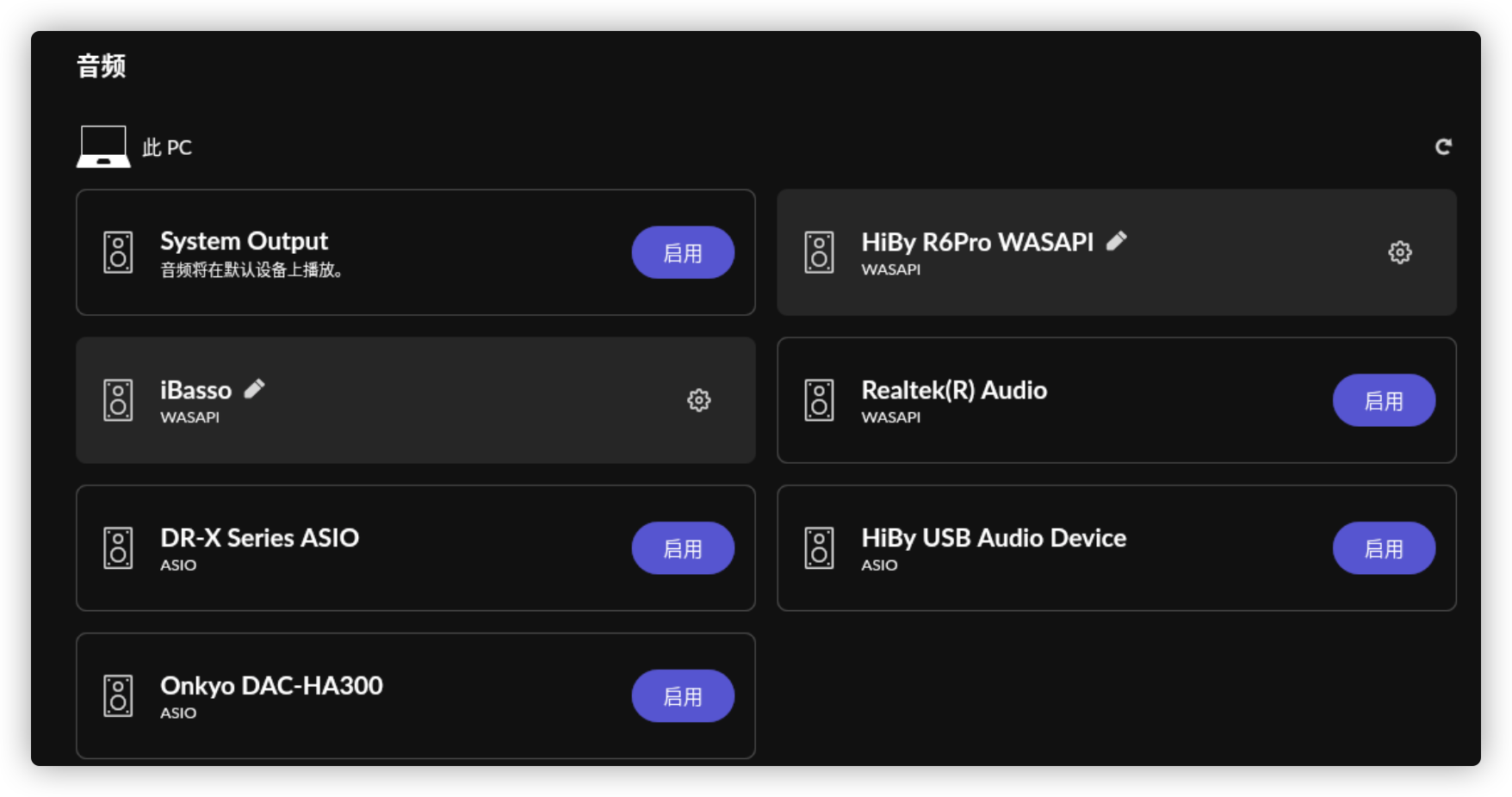
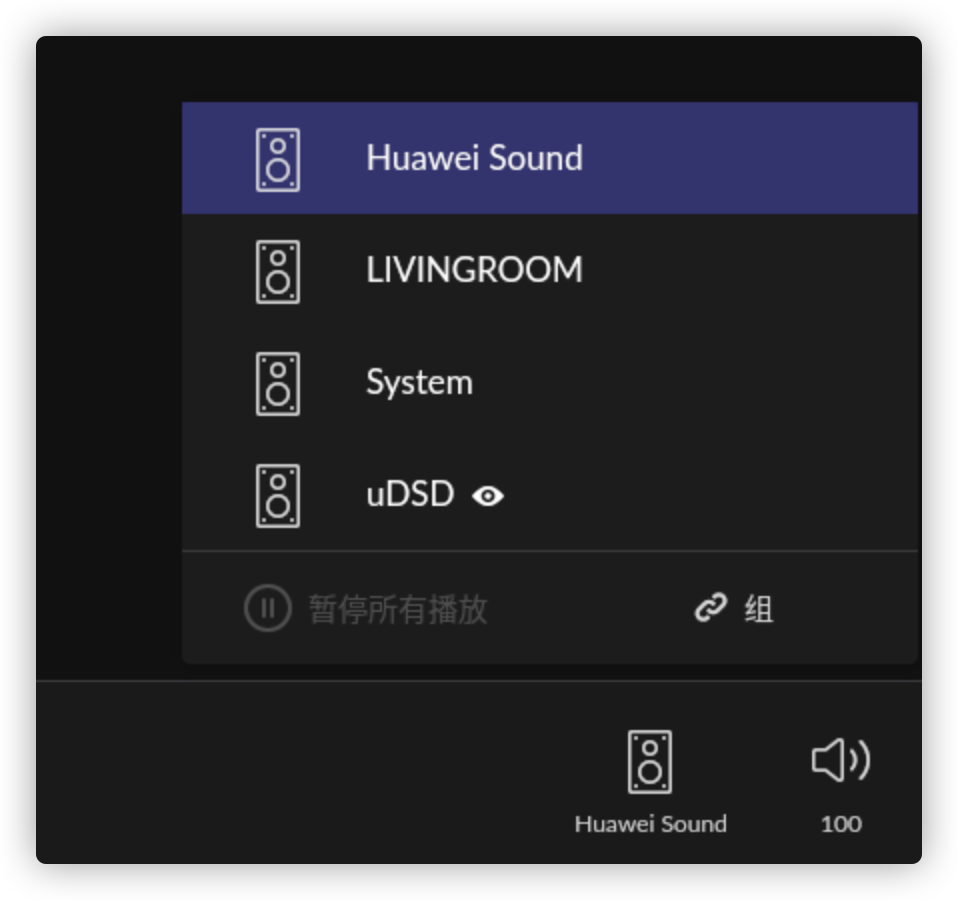
Roon配置 在Roon的“设置”->”音频”中启用桥设备,并给其命名,例如命名为Huawei Sound
对设备进行一些简单配置
在右下角的设备选择那里选择需要播放的设备,例如Huawei Sound音箱
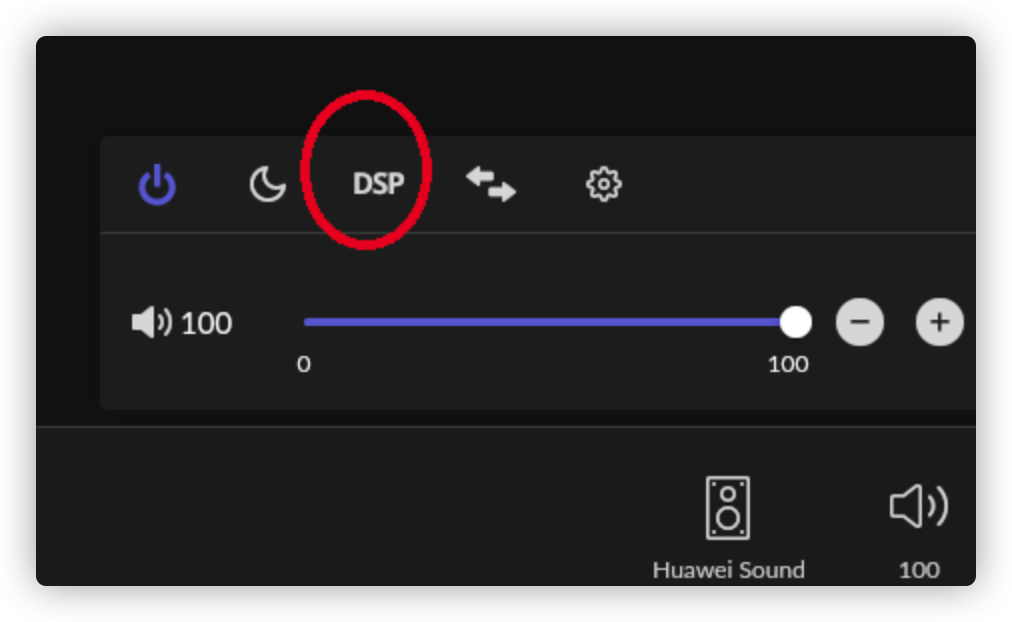
打开SqueezeBox设置
然后打开设备的DSP选项
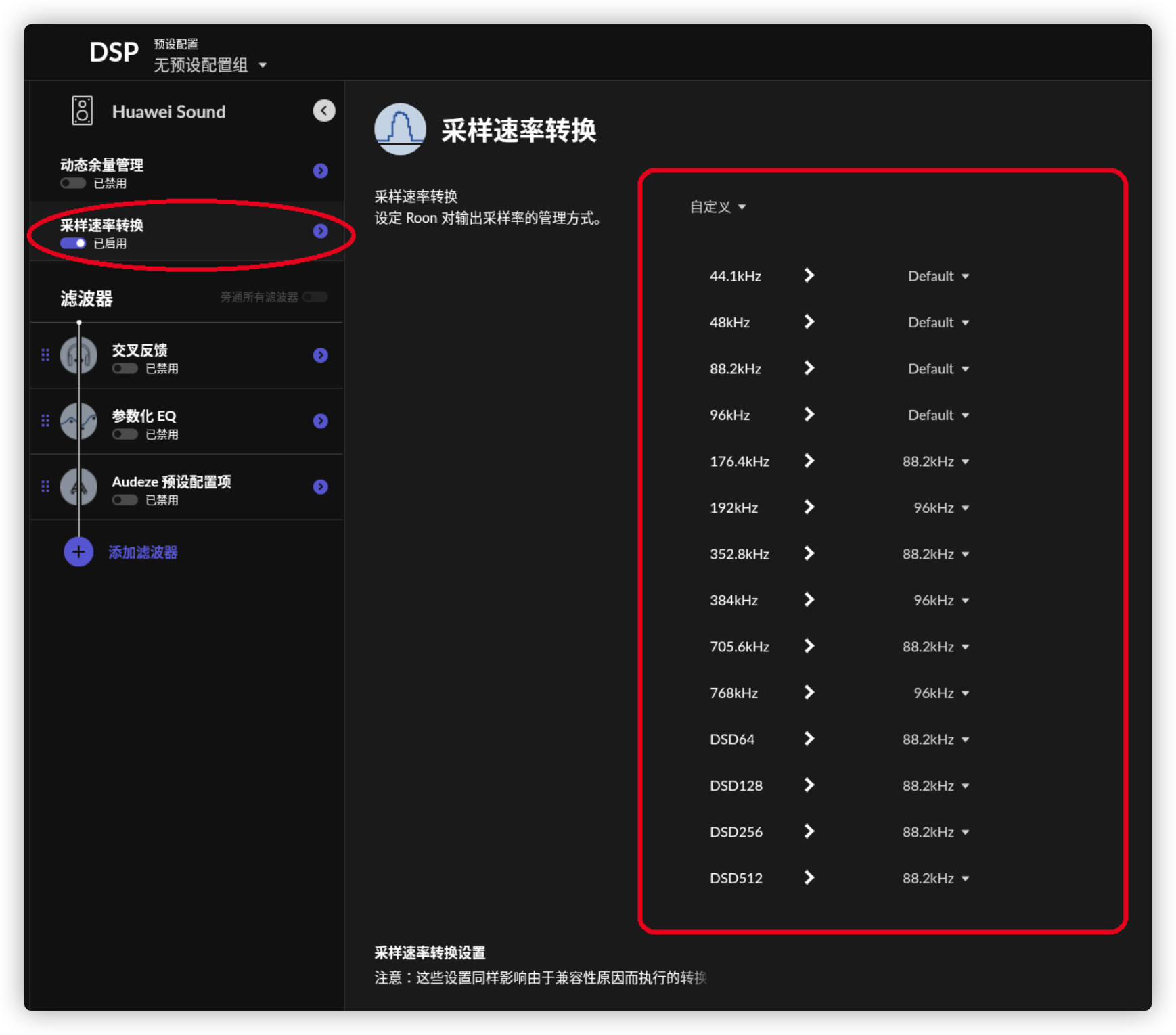
打开SqueezeBox设置
将Huawei Sound高于96k码率的音乐和DSD音乐进行转换
打开SqueezeBox设置
最终效果 这下,就可以在Roon系统中使用Huawei智能音箱了
打开SqueezeBox设置
使用docker运行squeeze2upnp 上面的squeeze2upnp安装过程依赖命令行,有点复杂,我简单做了一个docker镜像,在群晖上可以通过docker套件的界面来部署squeeze2upnp
首先需要在群晖上安装官方的docker套件:
Docker套件
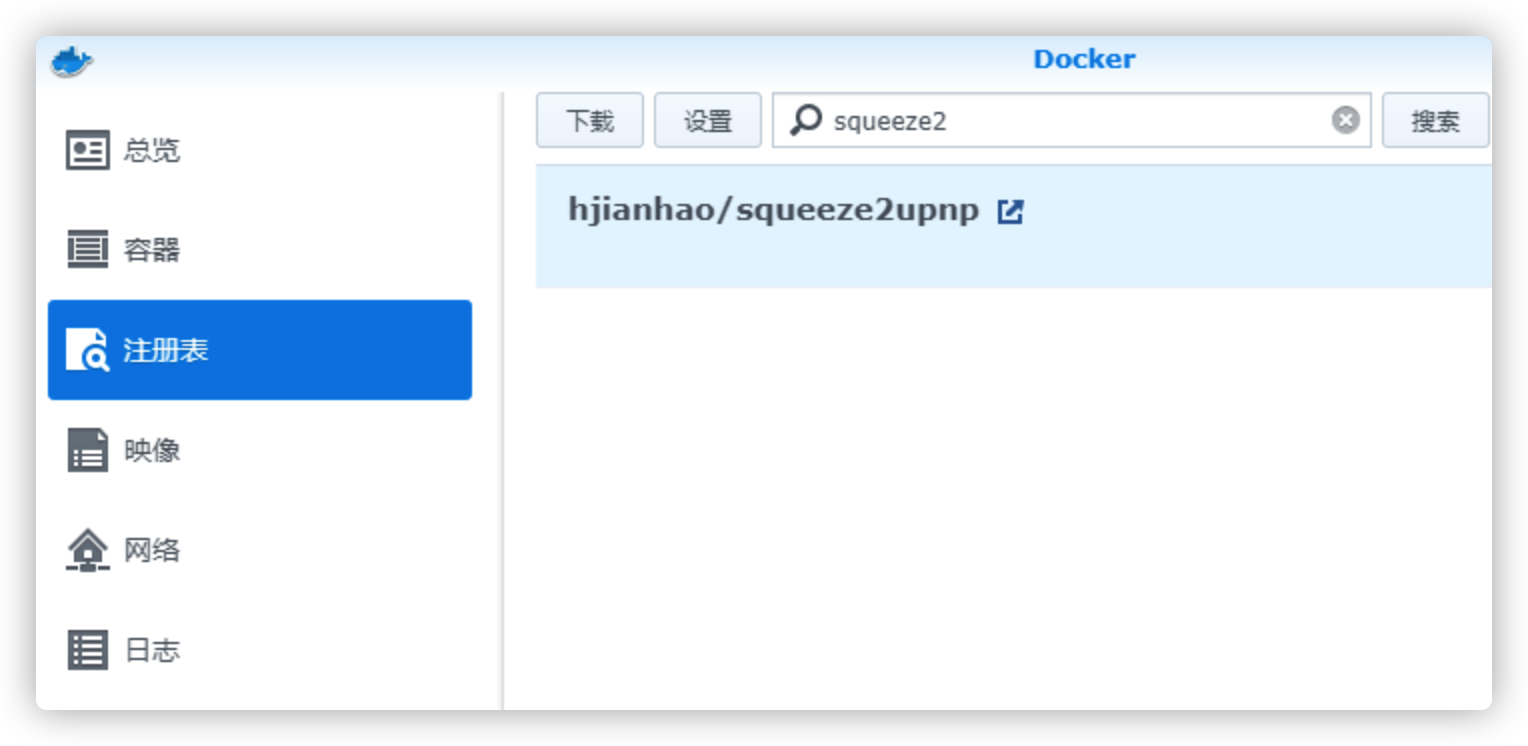
打开Docker套件界面搜索镜像hjianhao/hjianhao-squeeze2upnp
搜索镜像
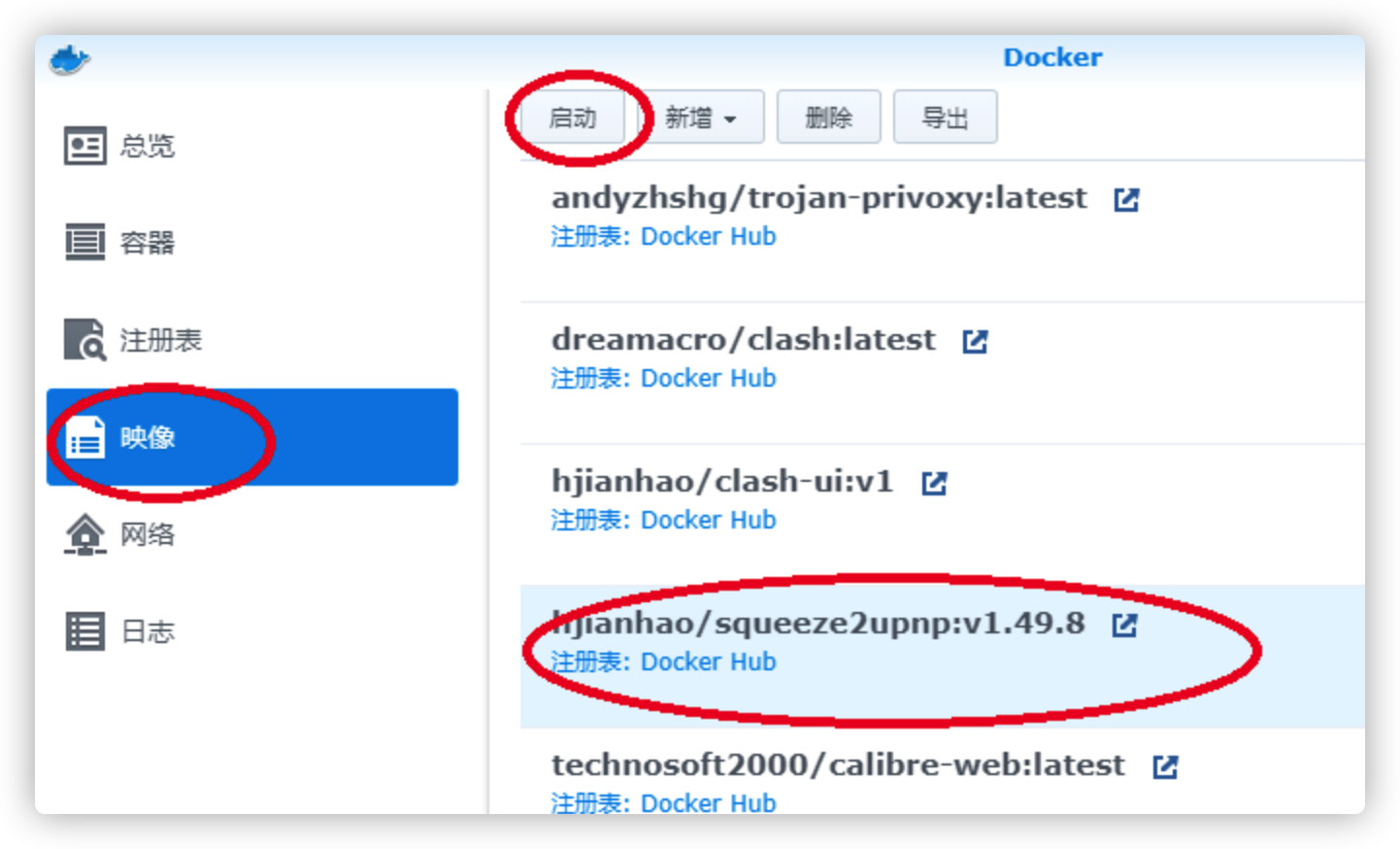
搜索到镜像后下载,并在映像界面启动容器
启动容器
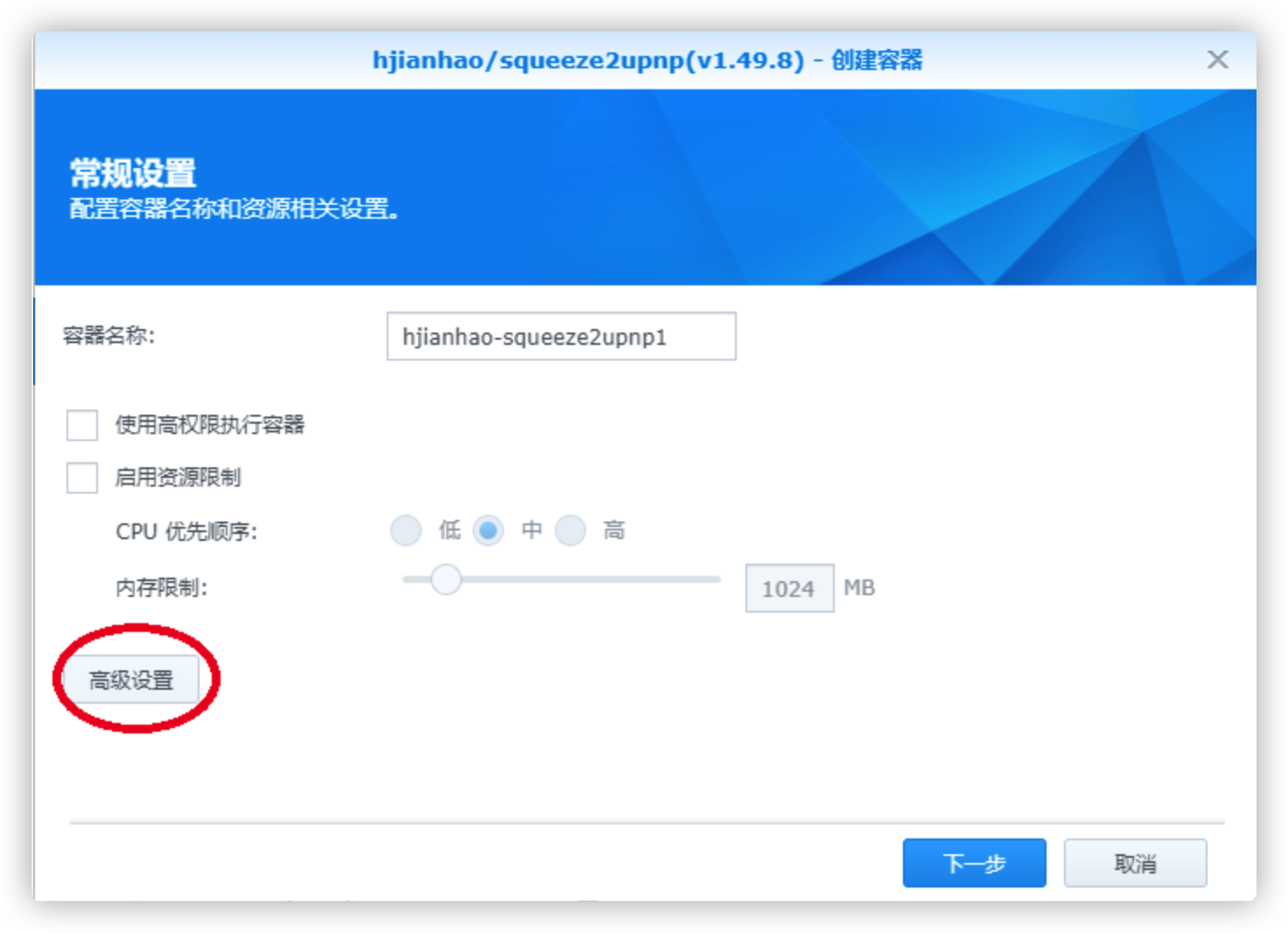
选择高级设置
高级设置
在NAS上创建一个保存配置文件(config.xml)的目录,并挂接到容器的/config目录
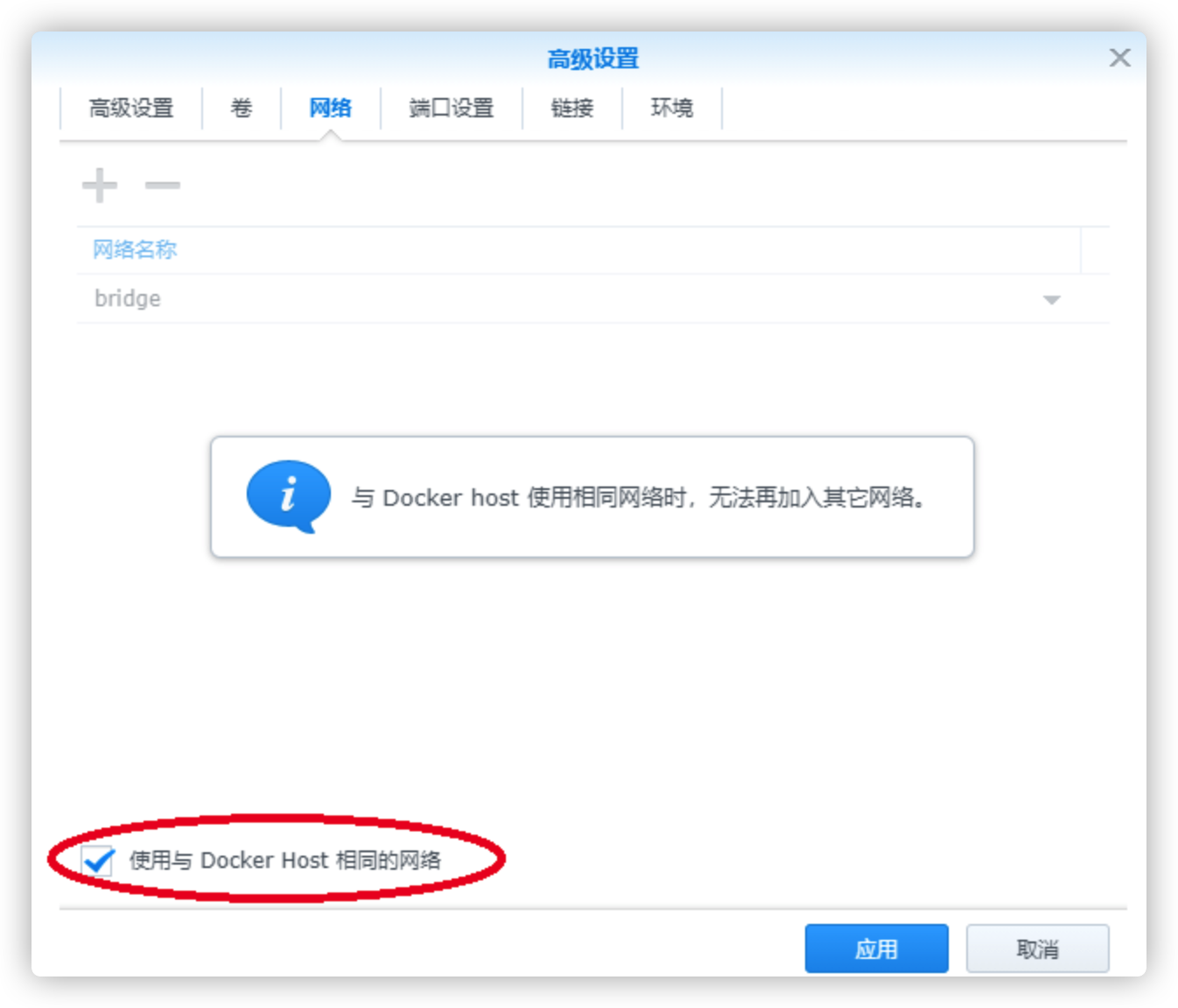
因为squeezeupnp涉及范围端口的使用,所以使用host网络
配置网络
应用后,一路“下一步”即可启动容器。
创建容器
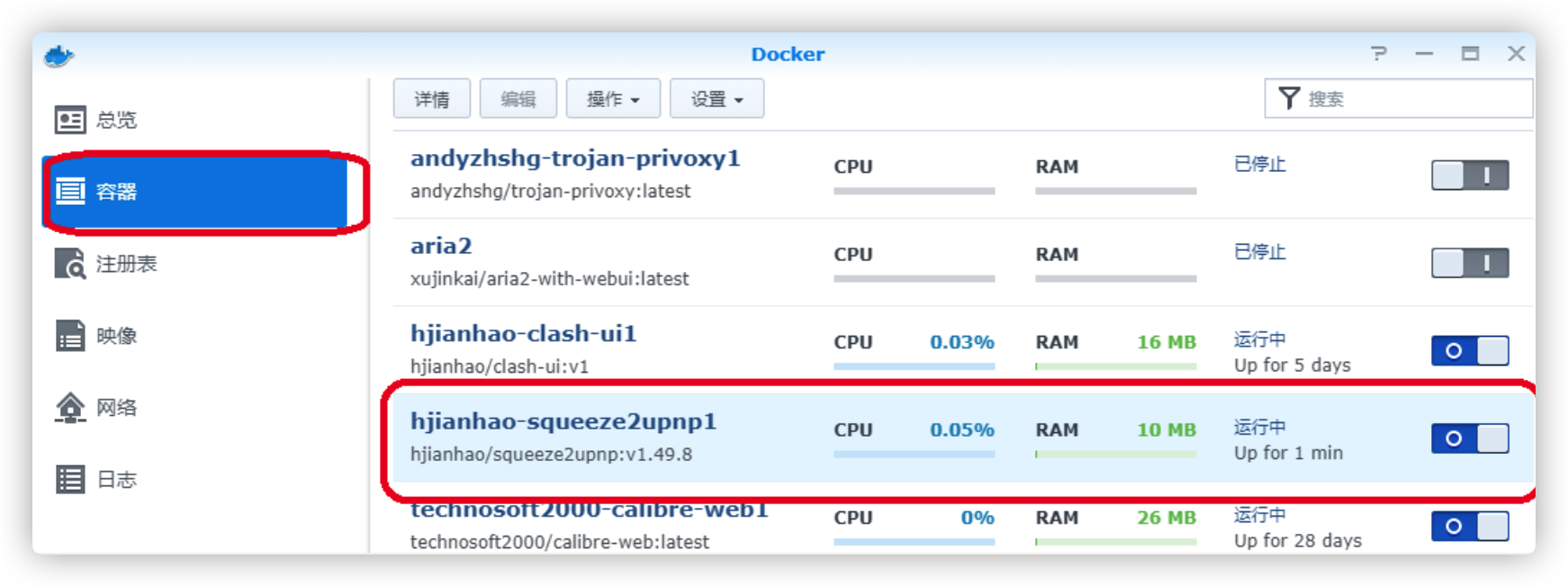
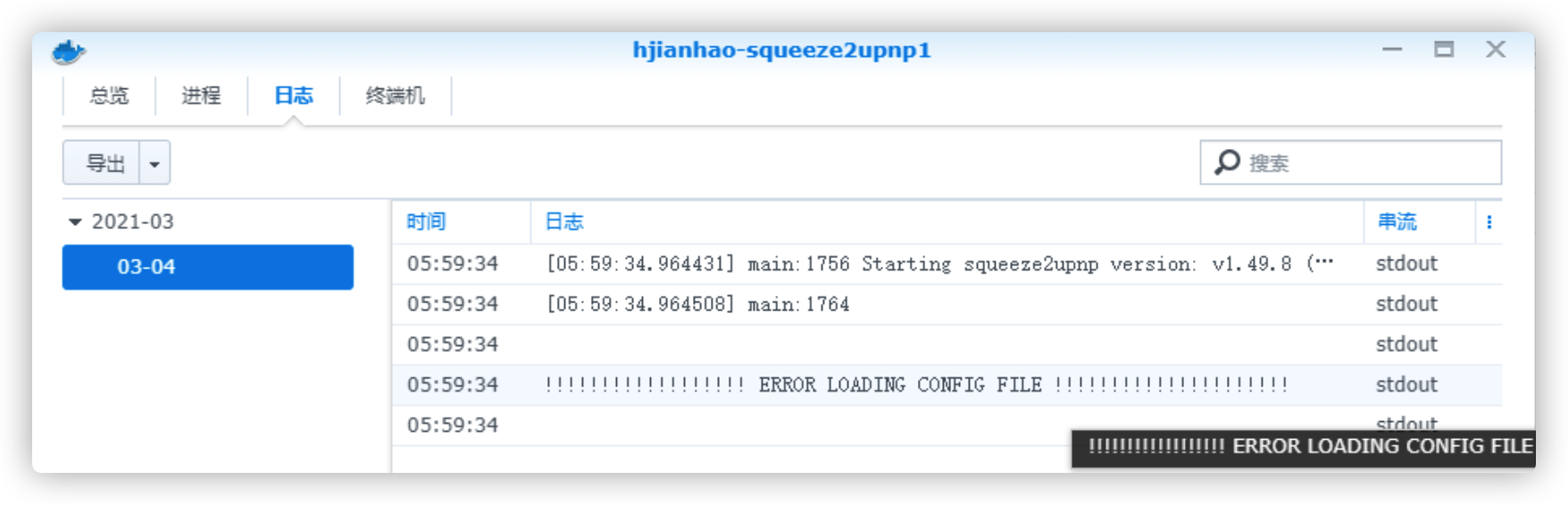
第一次容器虽然启动了,但是功能是失效的,从上面的说明可以看到此时还没有配置文件(config.xml), 点击“详情”按钮弹出容器信息窗口,从“日志”标签中可以看到,加载配置文件失败
启动失败日志
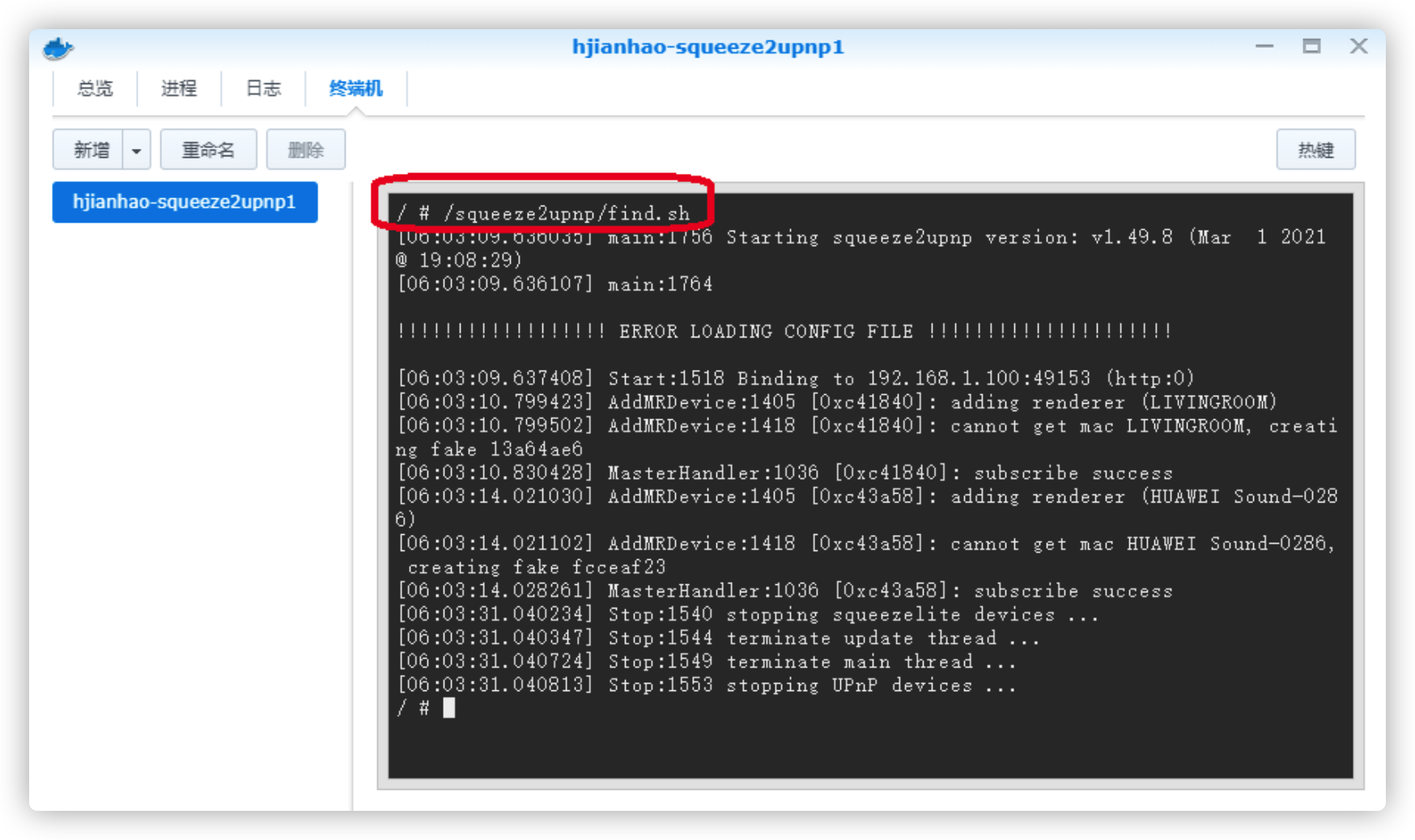
此时我们进入“终端”标签,执行/squeeze2upnp/find.sh,用于发现DLNA Render设备,并生成配置文件
发现设备
执行完成后,使用“Ctrl+D”退出并停止容器运行。此时在你挂载的配置文件目录中就会有”Config.xml”配置文件。
配置文件
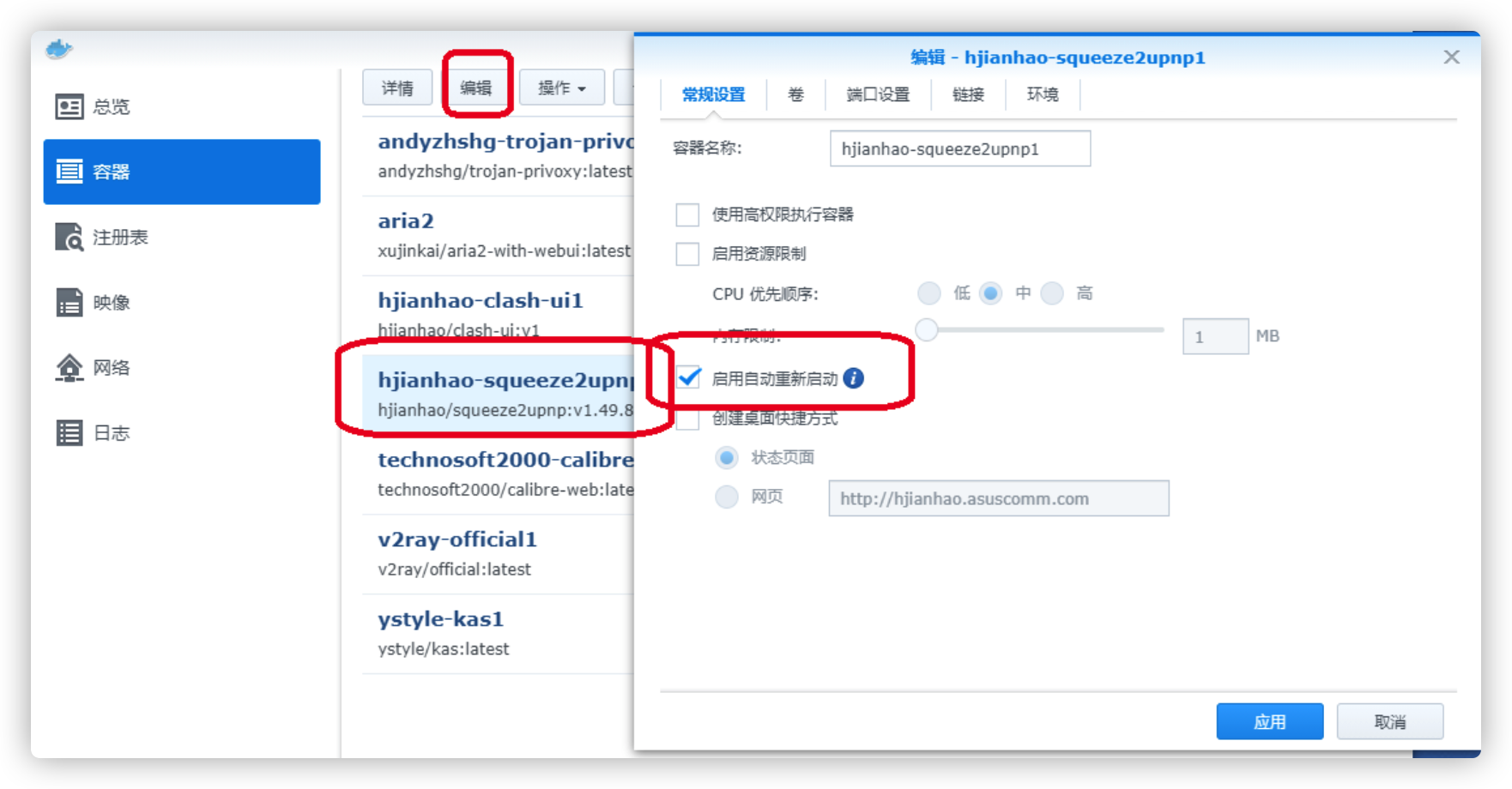
然后配置按前面对配置文件的描述修改配置文件,再重启容器即可。重启容器前最好将自动重启勾上
配置文件
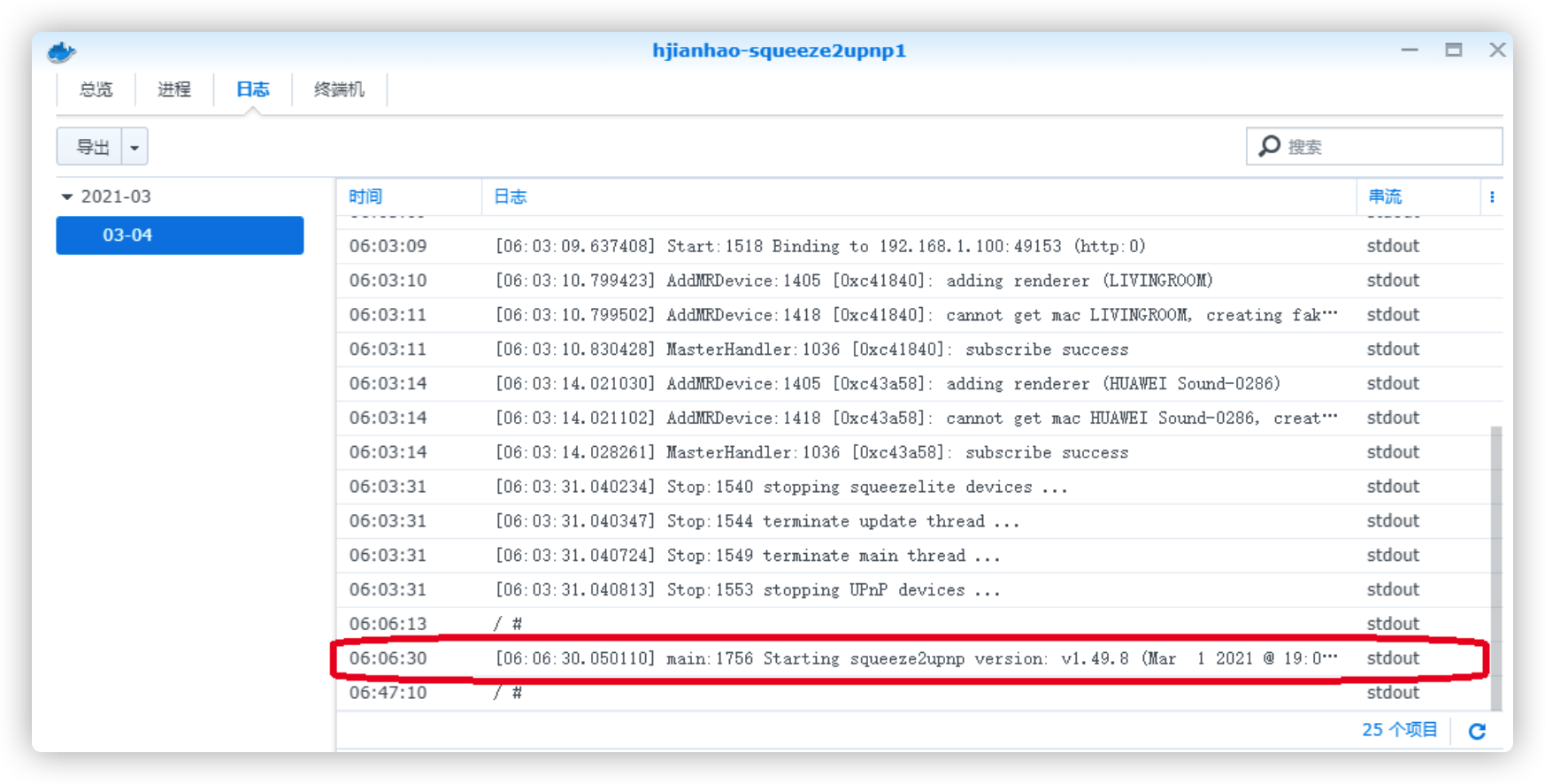
启动成功后,只有一行日志
配置文件
通过桥连接解码器 除了上面提到的通过squeeze2upnp转换用DLNA连接解码器外,还有其他的连接解码器的方式:
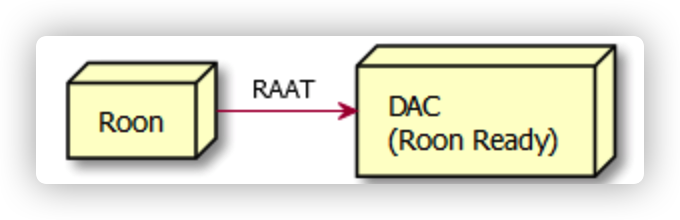
也可以通过RAAT接入Roon Ready的解码器(前提是解码器支持Roon Ready)
这种方式比较简单,只要你的解码器支持Roon Ready且解码器和Roon core在同一个局域网网段,就可以相互发现,不用配置。因为简单且我的解码器不支持Roon Ready就不在这里赘述了
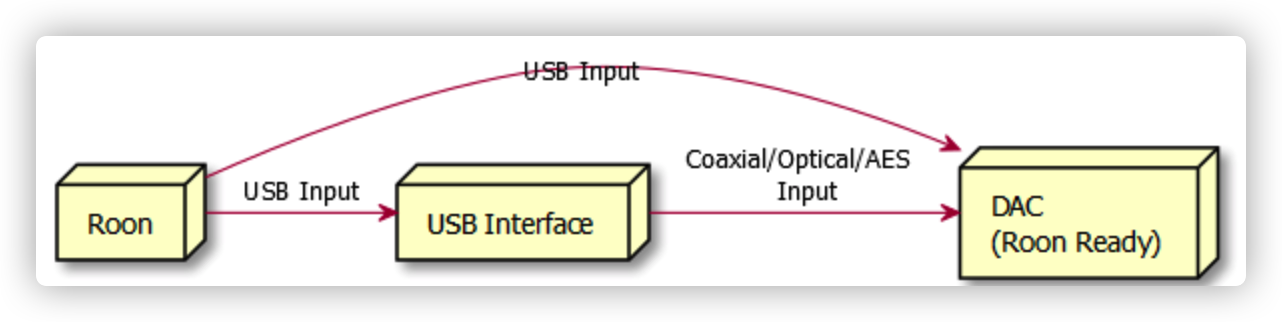
Roon Core通过USB输出接入解码器,包括直接接入到解码器的USB输入,或者通过解码器界面转换为同轴和光纤输入解码器
Roon Core通过RAAT协议接入Roon Bridge,然后Roon Bridge接入解码器,接入方式和上面说的Roon Core类似
这里主要介绍第三种,因为Bridge可以:
让Roon Core和解码器的位置摆放更为灵活,只要Bridge接近解码器即可。
Bridge使用树莓派这种低功耗设备可以比Core更容易避免干扰,同时电源也更好处理。
多个Bridge可以让Roon接入和控制多个房间的音响设备。
因为我个人的主音响系统以DLNA为主,因为我的解码器出声最好的就是DLNA接入,其他数字接入都稍微差一些。所以树莓派做Bridge一个是做对比测试,另一个方面是作为我一个房间耳放的接入。这样我就可以用Roon控制在我的耳放上播放音乐。
树莓派做Roon Bridge是性价比非常高的Roon Bridge设备,功耗低,价格低,USB输出较好,I2S数字音频卡多,电源好处理。
在树莓派上装Roon Bridge 如果树莓派专用于Roon Bridge,则最好安装volumio,moode,RoPieee这类已经预先集成了Bridge软件的,比较简单。
因为我的树莓派还需要跑其他的软件,所以我是预装了系统再手工安装Roon Bridge。也比较简单
官方有Linux安装指导:https://help.roonlabs.com/portal/en/kb/articles/linux-install
要选对架构,对于树莓派4,如果是32位系统,用armv7hf, 我用的系统是64位的,所以使用armv8,安装只有下面三个指令
1 2 3 $ curl -O http://download.roonlabs.com/builds/roonbridge-installer-linuxarmv8.sh $ chmod +x roonbridge-installer-linuxarmv8.sh $ sudo ./roonbridge-installer-linuxarmv8.sh
取消安装在执行脚本加上参数uninstall,如:
1 sudo ./roonbridge-installer-linuxarmv8.sh uninstall
安装完成后会有安装结果提示,看是否安装成功。
重要提示: 安装完成后,可能会出现在Roon的关于里面可以看到桥,但是在音频里面看不到输出设备,应该是树莓派没有启动音频设备,需要修改config.txt文件,将dtparam=audio=on这一行的注释弃掉(删除前面的#号)
除了USB输出外,也可以给树莓派添加I2S音频扩展卡,通过同轴/平衡/光纤输出到解码器。
如果选用的是兼容HiFiBerry系列的显卡,可以参考:https://www.hifiberry.com/docs/software/configuring-linux-3-18-x/
以我买的带平衡和光纤输出的兼容HiFiBerry Digi+的扩展版为例,修改/boot/config.txt
注释掉dtparam=audio=on
添加dtoverlay=hifiberry-dac
重启树莓派即可。然后用aplay指令可以看到I2S声卡
1 2 3 4 5 aplay -l **** List of PLAYBACK Hardware Devices **** card 0: sndrpihifiberry [snd_rpi_hifiberry_digi], device 0: HifiBerry Digi HiFi wm8804-spdif-0 [HifiBerry Digi HiFi wm8804-spdif-0] Subdevices: 1/1 Subdevice
通过VPN实现远程ROON 打通WAN连接服务器
首先要像运营商(如电信宽带)申请公网IP。
申请一个免费域名,同时将域名设置动态映射。这个每家域名提供商具体不一样,根据指导去配。
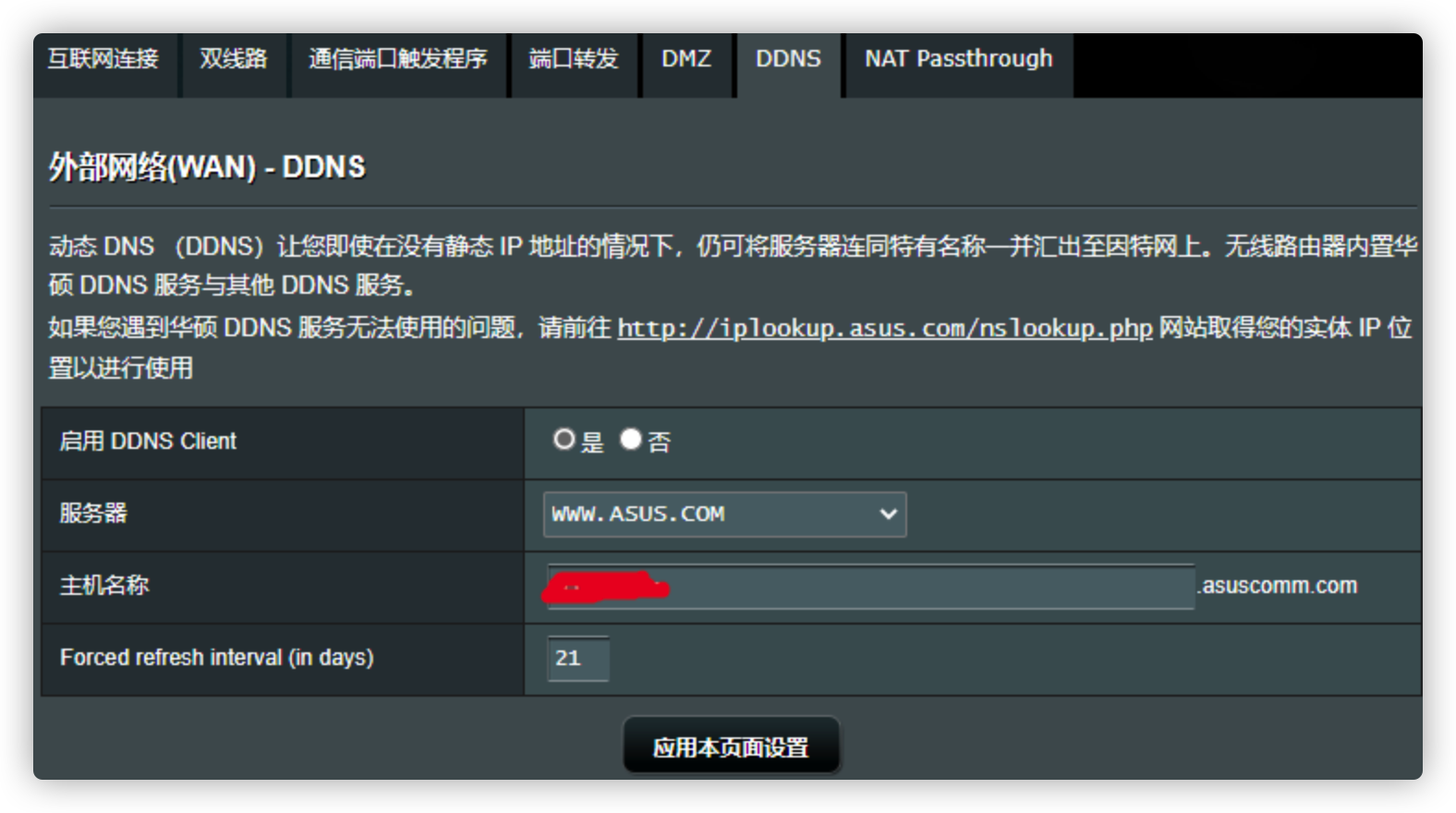
公网IP一般是动态的,会变化的,使用DDNS来做动态映射,以下以梅林固件的路由器为例:
服务器选择不同域名提供商,然后输入用户名等参数
搭建VPN服务器 以威联通QVPN为例
安装QVPN套件
启动L2TP/IPSec服务器
其中10.2.0.0是VPN虚拟机局域网的网段
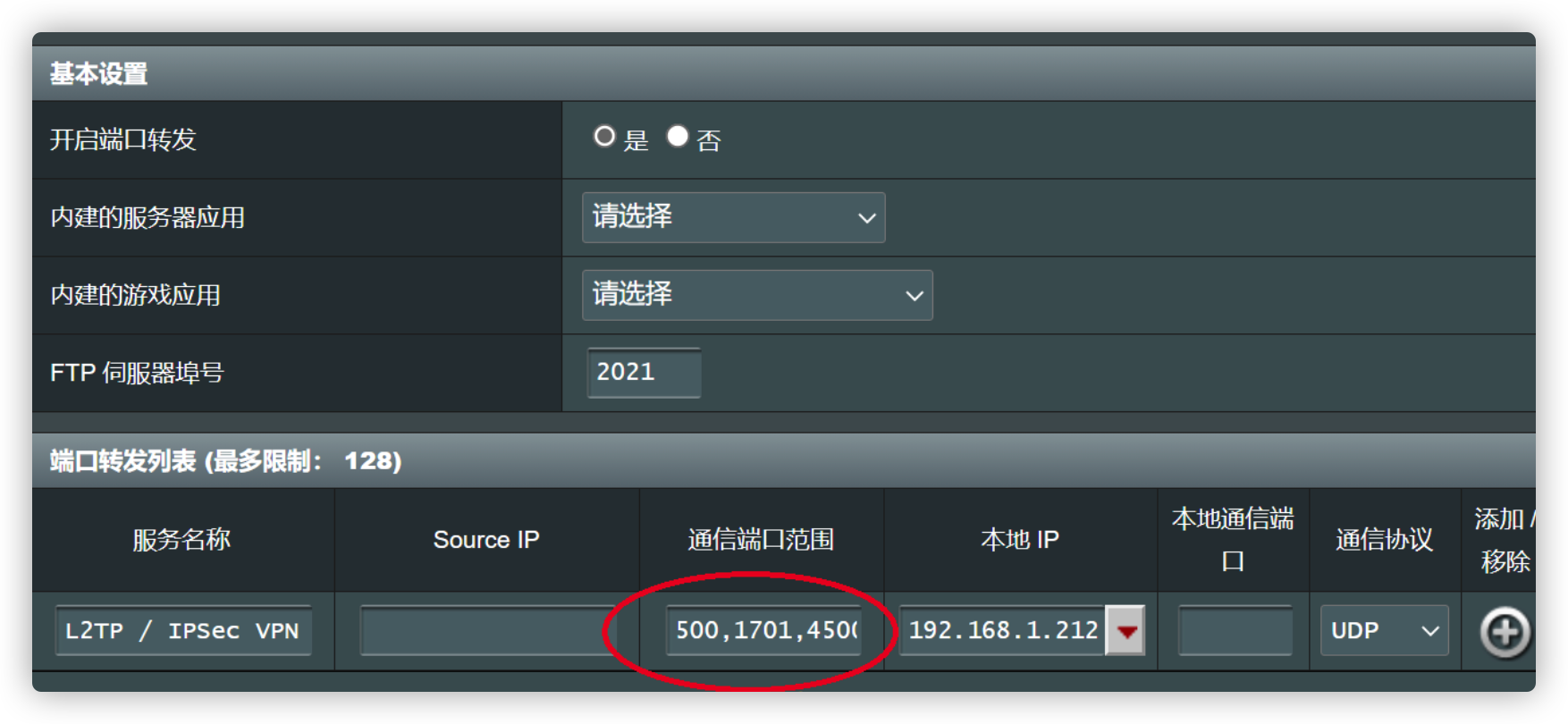
在路由器做端口映射,将以下端口流量导向NAS
端口映射
远程机器连接VPN服务器 a. 用户名和密码是你创建VPN服务器的NAS用户用户名和密码
进行连接
在Windows上创建VPN连接
连接后会增加一个虚拟网卡
1 2 3 4 5 6 7 PPP 适配器 myhome: 连接特定的 DNS 后缀 . . . . . . . : 本地链接 IPv6 地址. . . . . . . . : fe80::ecdd:7a2a:228e:9b30%51 IPv4 地址 . . . . . . . . . . . . : 10.2.0.1 子网掩码 . . . . . . . . . . . . : 255.255.255.255 默认网关. . . . . . . . . . . . . : 0.0.0.0
同时你也可以访问NAS所在局域网的地址
此时你的Windows和NAS已经处在一个虚拟局域网下,启动远程计算机上的Roon就可以连接NAS上跑的Core了。
此时你看到Roon Core的IP地址是刚才建立的VPN的网段(Core机器上也有一个虚拟网卡)
同时也可以发现远程Windows机器上连接的音频设备用于播放


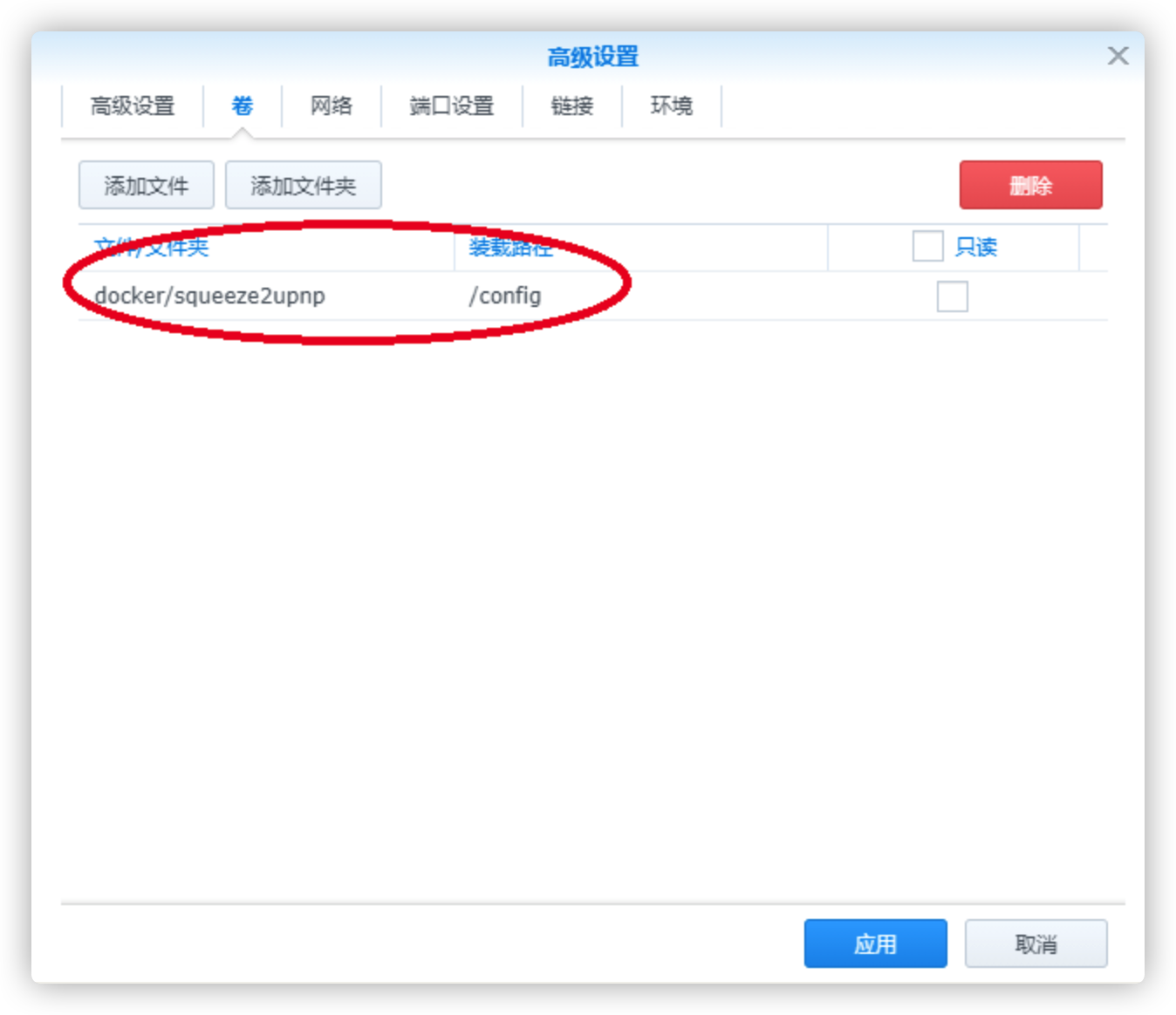 挂载配置目录
挂载配置目录