上线流程(复件)
这是一篇加密文章,需要密码才能继续阅读。
今天在工作的时候遇到了一个问题,就是List的去重,不想用双重for,感觉太low,不想用for+Map,感觉应该有更好的方法,于是,google之。发现java8的stream流能完美解决这个问题。
1 | List<BookInfoVo> list |
比如在 BookInfoVo 中有一个 recordId 属性,现在需要对此去重.
怎么办呢?
有两种方法:
1 | private List<BookInfoVo> removeDupliByRecordId(List<BookInfoVo> books) { |
1 | /** |
1 | /*方法二:炫酷的java8写法*/ |
1 | ArrayList<BookInfoVo> distinctLiost = list.stream().collect(Collectors.collectingAndThen( |
其实理解起来也不难:
关键在于Collectors.collectingAndThen( Collectors.toCollection(() -> new TreeSet<>(Comparator.comparingLong(BookInfoVo::getRecordId))), ArrayList::new)的理解,
collectingAndThen 这个方法的意思是: 将收集的结果转换为另一种类型: collectingAndThen,
因此上面的方法可以理解为,把 new TreeSet<>(Comparator.comparingLong(BookInfoVo::getRecordId))这个set转换为 ArrayList,这个结合第一种方法不难理解.
可以看到java8这种写法真是炫酷又强大!!!
[toc]
下文中出现的list、ints、integers分别代表一个列表、一个int数组、一个Integer数组。
它们之间所谓的转化,其实是 复制数据,互不干扰,可以理解为深拷贝。
1 | List<Integer> list = Arrays.stream(ints).boxed().collect(Collectors.toList()); |
Arrays.stream(ints) 之后返回的类型是 IntStream,IntStream 是一个接口继承自 BaseStream,BaseStream 又继承自AutoCloseable。所以我把IntStream看成一个方便对每个整数做操作的数据流。
之后调用了 boxed(),它的作用是对每个整数进行装箱,基本类型流转换为对象流,返回的是 Stream
最后通过collect方法将数据流 (Stream
小结:
1 | String temp = Arrays.deepToString(fooArr).replaceAll("\\[","").replaceAll("\\]",""); |
1 | List<List<Integer>> collect2 = Arrays.Stream(ints1).map(ar -> Arrays.stream(ar).boxed().collect(Collectors.toList())).collect(Collectors.toList()); |
1 | Integer[] integers = Arrays.stream(ints).boxed().toArray(Integer[]::new); |
一样的内容就不重复了,toArray(T[ ] :: new) 方法返回基本类型数组。
小结:
1 | Integer[][] integers3 = Arrays.stream(ints1).map(ints -> Arrays.stream(ints).boxed().toArray(Integer[]::new)).toArray(Integer[][]::new); |
1 | List<Integer> list = Arrays.asList(integers); |
这个就很简单了,通过Arrays类里的asList方法将数组装换为List。值得注意:
asList 返回的是 Arrays 里的静态私有类 ArrayList,而不是 java.util 里的 ArrayList,它无法自动扩容。
可以用下面2种方法生成可扩容的ArrayList:
1 | List<Integer> list = new ArrayList<>(Arrays.asList(integers)); |
或者
1 | List<Integer> list = new ArrayList<>(); |
1 | Integer[][] a = {{1,2,3},{1,2,3}}; |
1 | int[] ints = Arrays.stream(integers).mapToInt(Integer::valueOf).toArray(); |
map的意思是把每一个元素进行同样的操作。mapToInt的意思是把每一个元素转换为int。mapToInt(Integer::valueOf)方法返回的是IntStream。
小结:
1 | Integer[][] a = {{1,2,3},{1,2,3}}; |
1 | int[] ints = list.stream().mapToInt(Integer::valueOf).toArray(); |
经过上面的说明,相信这里已经很好理解了,直接小结。
小结:
1 | List<List<Integer>> lists = ...; |
1 | Integer[] integers = list.toArray(new Integer[list.size()]); |
1 | Integer[] integers = list.stream().toArray(Integer[]::new); //不推荐 |
这个也很简单,方法里的参数是一个数组,所以要规定长度。也有无参的方法,但是要进行转型,所以不推荐使用。
1 | List<List<Integer>> lists = ...; |
1 | Integer[][] arrays = lists.stream() // Stream<List<Integer>> |
1 | Integer[][] arrays = lists.stream().map(List::toArray).toArray(Integer[][]::new); |
1 | char[] chars = {'a', 'b', 'c'}; |
1 | List<List<Character>> collect2 = Arrays.stream(ints1).map(chars1 -> new String(chars1).chars().mapToObj(i -> (char) i).collect(Collectors.toList())).collect(Collectors.toList()); |
1 | char[] chars = {'a', 'b', 'c'}; |
1 | Character[][] integers3 = Arrays.stream(ints1).map(chars -> new String(chars).chars().mapToObj(i->(char)i).toArray(Character[]::new)).toArray(Character[][]::new); |
1 | List<Character> collect2 = Arrays.stream(characters).collect(Collectors.toList()); |
1 | List<List<Character>> lists = Arrays.stream(a).map(Arrays::asList).collect(Collectors.toList()); |
1 | char[] chars4 = Arrays.stream(characters1).map(String::valueOf).collect(Collectors.joining()).toCharArray(); |
1 | char[][] ints1 = Arrays.stream(a).map(a1 -> Arrays.stream(a1).map(String::valueOf).collect(Collectors.joining()).toCharArray()).toArray(char[][]::new); |
1 | char[] value = characters.stream().map(String::valueOf).collect(Collectors.joining()).toCharArray(); |
1 | Character[] charArr = characters.toArray(new Character[characters.size()]); |
1 | char[][] arrays = lists.stream() // Stream<List<Integer>> |
1 | Character[] characters2 = Arrays.stream(characters1).toArray(Character[]::new); |
1 | Character[][] integers1 = lists.stream() // Stream<List<Integer>> |
1 | Character[][] integers2 = lists.stream() // Stream<List<Integer>> |
1 | Character[][] integers = lists.stream().map(List::toArray).toArray(Character[][]::new); |
1. 类外注释
该注释放在 package 关键字之后,class 或者 interface 关键字之前。
1 | package com.huawei.msg.relay.comm; |
1 | /** |
1 | /** |
2. 类内注释
类属性、公有和保护方法必须写注释。geter、seter方法不用写注释
示例:
1 | /** |
1).成员变量注释内容:成员变量的意义、目的、功能,可能被用到的地方。
2).公有和保护方法注释内容:列出方法的一句话功能 简述、功能详细描述、输入参数、输出参数、返回值、违例等。
格式:
1 | /** |
说明: @exception或throws 列出可能仍出的异常。
示例:
1 | /** |
说明:
1).注释应与其描述的代码相近,对代码的注释应放在其上方或右方(对单条语句的注释)相邻位置,不可放在下面,如放于上方则需与其上面的代码用空行隔开。
2).注释与所描述内容进行同样的缩排。
3).将注释与其上面的代码用空行隔开。
示例:
1 | //注释 |
对变量的定义和分支语句(条件分支、循环语句等)对复杂的分支必须编写注释,如果时间允许,建议对所有分支语句写注释。
说明:这些语句往往是程序实现某一特定功能的关键,对于维护人员来说,良好的注释帮助更好的理解程序,有时甚至优于看设计文档。
1 | // 如果 receiveFlag 为真 |
1 | // 如果从连结收到消息 |
1 | if (...) |
1 | //1、 判断输入参数是否有效。 |
java //1. 如果能被4整除,是闰年; //2. 如果能被100整除,不是闰年.; //3. 如果能被400整除,是闰年.。 星期五, 23. 八月 2019 07:42下午**
**
Spring、Netty、Mybatis 等框架的代码中大量运用了 Java 多线程编程技巧。并发编程处理的恰当与否,将直接影响架构的性能。本章通过对 这些框架源码 的分析,结合并发编程的常用技巧,来讲解多线程编程在这些主流框架中的应用。
JVM 规范 定义了 Java 内存模型 来屏蔽掉各种操作系统、虚拟机实现厂商和硬件的内存访问差异,以确保 Java 程序 在所有操作系统和平台上能够达到一致的内存访问效果。
Java 内存模型 规定所有的变量都存储在主内存中,每个线程都有自己独立的工作内存,工作内存保存了 对应该线程使用的变量的主内存副本拷贝。线程对这些变量的操作都在自己的工作内存中进行,不能直接操作主内存 和 其他工作内存中存储的变量或者变量副本。线程间的变量传递需通过主内存来完成,三者的关系如下图所示。
Java 内存模型定义了 8 种操作来完成主内存和工作内存的变量访问,具体如下。
这个概念与事务中的原子性大概一致,表明此操作是不可分割,不可中断的,要么全部执行,要么全部不执行。 Java 内存模型直接保证的原子性操作包括 read、load、use、assign、store、write、lock、unlock 这八个。
可见性是指当一个线程修改了共享变量的值,其他线程能够立即得知这个修改。Java 内存模型 是通过在变量修改后将新值同步回主内存,在变量读取前从主内存刷新变量值这种依赖主内存作为传递媒介的方式来实现可见性的,无论是普通变量还是 volatile 变量 都是如此,普通变量与 volatile 变量 的区别是,volatile 的特殊规则保证了新值能立即同步到主内存,以及每次使用前立即从主内存刷新。因此,可以说 volatile 保证了多线程操作时变量的可见性,而普通变量则不能保证这一点。除了 volatile 外,synchronized 也提供了可见性,synchronized 的可见性是由 “对一个变量执行 unlock 操作 之前,必须先把此变量同步回主内存中(执行 store、write 操作)” 这条规则获得。
单线程环境下,程序会 “有序的”执行,即:线程内表现为串行语义。但是在多线程环境下,由于指令重排,并发执行的正确性会受到影响。在 Java 中使用 volatile 和 synchronized 关键字,可以保证多线程执行的有序性。volatile 通过加入内存屏障指令来禁止内存的重排序。synchronized 通过加锁,保证同一时刻只有一个线程来执行同步代码。
打开 NioEventLoop 的代码中,有一个控制 IO 操作 和 其他任务运行比例的,用 volatile 修饰的 int 类型字段 ioRatio,代码如下。
1 | private volatile int ioRatio = 50; |
这里为什么要用 volatile 修饰呢?我们首先对 volatile 关键字进行说明,然后再结合 Netty 的代码进行分析。
关键字 volatile 是 Java 提供的最轻量级的同步机制,Java 内存模型对 volatile 专门定义了一些特殊的访问规则。下面我们就看它的规则。当一个变量被 volatile 修饰后,它将具备以下两种特性。
1 | public class ThreadStopExample { |
我们预期程序会在 3s 后停止,但是实际上它会一直执行下去,原因就是虚拟机对代码进行了指令重排序和优化,优化后的指令如下。
1 | if (!stop) |
workThread 线程 在执行重排序后的代码时,是无法发现 变量 stop 被其它线程修改的,因此无法停止运行。要解决这个问题,只要将 stop 前增加 volatile 修饰符即可。volatile 解决了如下两个问题。第一,主线程对 stop 的修改在 workThread 线程 中可见,也就是说 workThread 线程 立即看到了其他线程对于 stop 变量 的修改。第二,禁止指令重排序,防止因为重排序导致的并发访问逻辑混乱。
一些人认为使用 volatile 可以代替传统锁,提升并发性能,这个认识是错误的。volatile 仅仅解决了可见性的问题,但是它并不能保证互斥性,也就是说多个线程并发修改某个变量时,依旧会产生多线程问题。因此,不能靠 volatile 来完全替代传统的锁。根据经验总结,volatile 最适用的场景是 “ 一个线程写,其他线程读 ”,如果有多个线程并发写操作,仍然需要使用锁或者线程安全的容器或者原子变量来代替。下面我们继续对 Netty 的源码做分析。上面讲到了 ioRatio 被定义成 volatile,下面看看代码为什么要这样定义。
1 | final long ioTime = System.nanoTime() - ioStartTime; |
通过代码分析我们发现,在 NioEventLoop 线程 中,ioRatio 并没有被修改,它是只读操作。既然没有修改,为什么要定义成 volatile 呢?继续看代码,我们发现 NioEventLoop 提供了重新设置 IO 执行时间比例的公共方法。
1 | public void setIoRatio(int ioRatio) { |
首先,NioEventLoop 线程 没有调用该 set 方法,说明调整 IO 执行时间比例 是外部发起的操作,通常是由业务的线程调用该方法,重新设置该参数。这样就形成了一个线程写、一个线程读。根据前面针对 volatile 的应用总结,此时可以使用 volatile 来代替传统的 synchronized 关键字,以提升并发访问的性能。
ThreadLocal 又称为线程本地存储区(Thread Local Storage,简称为 TLS),每个线程都有自己的私有的本地存储区域,不同线程之间彼此不能访问对方的 TLS 区域。使用 ThreadLocal 变量 的 set(T value)方法 可以将数据存入 该线程本地存储区,使用 get() 方法 可以获取到之前存入的值。
不使用 ThreadLocal。
1 | public class SessionBean { |
上述代码中,session 需要在方法间传递才可以修改和读取,保证线程中各方法操作的是一个。下面看一下使用 ThreadLocal 的代码。
1 | public class SessionBean { |
在方法的内部实现中,直接可以通过 session.get() 获取到当前线程的 session,省掉了参数在方法间传递的环节。
一般,类属性中的数据是多个线程共享的,但 ThreadLocal 类型的数据 声明为类属性,却可以为每一个使用它(通过 set(T value)方法)的线程存储 线程私有的数据,通过其源码我们可以发现其中的原理。
1 | public class ThreadLocal<T> { |
Spring 事务处理的设计与实现中大量使用了 ThreadLocal 类,比如,TransactionSynchronizationManager 维护了一系列的 ThreadLocal 变量,用于存储线程私有的 事务属性及资源。源码如下。
1 | /** |
Mybatis 的 SqlSession 对象 也是各线程私有的资源,所以对其的管理也使用到了 ThreadLocal 类。源码如下。
1 | public class SqlSessionManager implements SqlSessionFactory, SqlSession { |
首先通过 ThreadPoolExecutor 的源码 看一下线程池的主要参数及方法。
1 | public class ThreadPoolExecutor extends AbstractExecutorService { |
线程池执行流程,如下图所示。

Executors 类 通过 ThreadPoolExecutor 封装了 4 种常用的线程池:CachedThreadPool,FixedThreadPool,ScheduledThreadPool 和 SingleThreadExecutor。其功能如下。
Tomcat 在分发 web 请求 时使用了线程池来处理。
1 | public interface BlockingQueue<E> extends Queue<E> { |
互斥同步最主要的问题就是进行线程阻塞和唤醒所带来的性能的额外损耗,因此这种同步被称为阻塞同步,它属于一种悲观的并发策略,我们称之为悲观锁。随着硬件和操作系统指令集的发展和优化,产生了非阻塞同步,被称为乐观锁。简单地说,就是先进行操作,操作完成之后再判断操作是否成功,是否有并发问题,如果有则进行失败补偿,如果没有就算操作成功,这样就从根本上避免了同步锁的弊端。
目前,在 Java 中应用最广泛的非阻塞同步就是 CAS。从 JDK1.5 以后,可以使用 CAS 操作,该操作由 sun.misc.Unsafe 类里的 compareAndSwapInt() 和 compareAndSwapLong() 等方法实现。通常情况下 sun.misc.Unsafe 类 对于开发者是不可见的,因此,JDK 提供了很多 CAS 包装类 简化开发者的使用,如 AtomicInteger。使用 Java 自带的 Atomic 原子类,可以避免同步锁带来的并发访问性能降低的问题,减少犯错的机会。
经验都是慢慢积累的,天才不多| 第170篇
记得中学的课本上,有一篇名为《狂人日记》课文;那时候根本理解不了鲁迅写这篇文章要表达的中心思想,只觉得满篇的“吃人”令人心情压抑;老师在讲台上慷慨激昂的讲,大多数的同学同我一样,在课本面前“痴痴”的发呆。
作为一个有着8年Java编程经验的IT老兵,说起来很惭愧,我被Java当中的四五个名词一直困扰着:对象、引用、堆、栈、堆栈(栈可同堆栈,因此是四个名词,也是五个名词)。每次我看到这几个名词,都隐隐约约觉得自己在被一只无形的大口慢慢地吞噬,只剩下满地的衣服碎屑(为什么不是骨头,因为骨头也好吃)。
十几年后,再读《狂人日记》,恍然如梦:
鲁迅先生以狂人的口吻,再现了动乱时期下中国人的精神状态,视角新颖,文笔细腻又不乏辛辣之味。
当时的中国,混乱成了主色调。以清廷和孔教为主的封建旧思想还在潜移默化地影响着人们的思想,与此同时以革命和新思潮为主的现代思想已经开始了对大众灵魂的洗涤和冲击。
最近,和沉默王二技术交流群(120926808)的群友们交流后,Java中那四五个会吃人的名词:对象、引用、堆、栈、堆栈,似乎在脑海中也清晰了起来,尽管疑惑有时候仍然会在阴云密布时跑出来——正鉴于此,这篇文章恰好做一下归纳。
在Java中,尽管一切都可以看做是对象,但计算机操作的并非对象本身,而是对象的引用。 这话乍眼一看,似懂非懂。究竟什么是对象,什么又是引用呢?
先来看对象的定义:按照通俗的说法,每个对象都是某个类(class)的一个实例(instance)。那么,实例化的过程怎么描述呢?来看代码(类是String):
1 | new String("我是对象张三"); |
在Java中,实例化指的就是通过关键字“new”来创建对象的过程。以上代码在运行时就会创建两个对象——“我是对象张三”和”我是对象李四”;现在,该怎么操作他们呢?
我们都去过公园,见过几个大爷,他们很有一番本领——个个都能把风筝飞得老高老高,徒留我们眼馋的份!风筝飞那么高,没办法直接用手拽着飞啊,全要靠一根长长的看不见的结实的绳子来牵引!操作Java对象也是这个理,得有一根绳——也就是接下来要介绍的“引用”(我们肉眼也常常看不见它)。
1 | String zhangsan, lisi; |
这三行代码该怎么理解呢?
先来看第一行代码:String zhangsan, lisi;——声明了两个变量zhangsan和lisi,他们的类型为String。
①、歧义:zhangsan和lisi此时被称为引用。
你也许听过这样一句古文:“神之于形,犹利之于刀;未闻刀没而利存,岂容形亡而神在?”这是无神论者范缜(zhen)的名言,大致的意思就是:灵魂对于肉体来说,就像刀刃对于刀身;从没听说过刀身都没了刀刃还存在,那么怎么可能允许肉体死亡了而灵魂还在呢?
“引用”之于对象,就好比刀刃之于刀身,对象还没有创建,又怎么存在对象的“引用”呢?
如果zhangsan和lisi此时不能被称为“引用”,那么他们是什么呢?答案很简单,就是变量啊!(鄙人理解)
②、误解:zhangsan和lisi此时的默认值为null。
应该说zhangsan和lisi此时的值为undefined——借用JavaScript的关键字;也就是未定义;或者应该是一个新的关键字uninitialized——未初始化。但不管是undefined还是uninitialized,都与null不同。
既然没有初始化,zhangsan和lisi此时就不能被使用。假如强行使用的话,编译器就会报错,提醒zhangsan和lisi还没有出生(初始化);见下图。
如果把zhangsan和lisi初始化为null,编译器是认可的(见下图);由此可见,zhangsan和lisi此时的默认值不为null。
再来看第二行代码:zhangsan = new String("我是对象张三");——创建“我是对象张三”的String类对象,并将其赋值给zhangsan这个变量。
此时,zhangsan就是”我是对象张三”的引用;“=”操作符赋予了zhangsan这样神圣的权利。
第三行代码lisi = new String("我是对象李四");和第二行代码zhangsan = new String("我是对象张三");同理。
现在,我可以下这样一个结论了——对象是通过new关键字创建的;引用是依赖于对象的;=操作符把对象赋值给了引用。
我们再来看这样一段代码:
1 | String zhangsan, lisi; |
当zhangsan = lisi;执行过后,zhangsan就不再是”我是对象张三”的引用了;zhangsan和lisi指向了同一个对象(”我是对象李四”);因此,你知道System.out.println(zhangsan == lisi);打印的是false还是true了吗?
谁来告诉我,为什么有很多地方(书、博客等等)把栈叫做堆栈,把堆栈叫做栈?搞得我都头晕目眩了——绕着门柱估计转了80圈,不晕才怪!
我查了一下金山词霸,结果如下:
我的天呐,更晕了,有没有!怎么才能不晕呢?我这里有几招武功秘籍,你们尽管拿去一睹为快:
1)以后再看到堆、栈、堆栈三个在一起打牌的时候,直接把“堆栈”踢出去;这仨人不适合在一起玩,因为堆和栈才是老相好;你“堆栈”来这插一脚算怎么回事;这世界上只存在“堆、栈”或者“堆栈”(标点符号很重要哦)。
2)堆是在程序运行时在内存中申请的空间(可理解为动态的过程);切记,不是在编译时;因此,Java中的对象就放在这里,这样做的好处就是:
当需要一个对象时,只需要通过new关键字写一行代码即可,当执行这行代码时,会自动在内存的“堆”区分配空间——这样就很灵活。
另外,需要记住,堆遵循“先进后出”的规则。就好像,一个和尚去挑了一担水,然后把一担水装缸里面,等到他口渴的时候他再用瓢舀出来喝。请放肆地打开你的脑洞脑补一下这个流程:缸底的水是先进去的,但后出来的。所以,我建议这位和尚在缸上贴个标签——保质期90天,过期饮用,后果自负!
还是记不住,看下图:
不好意思,这是鼎,不是缸,将就一下哈
3)栈,又名堆栈(简直了,完全不符合程序员的思维啊,我们陈许愿习惯说一就是一,说二就是二嘛),能够和处理器(CPU,也就是脑子)直接关联,因此访问速度更快;举个十分不恰当的例子哈——眼睛相对嘴巴是离脑子近的一方,因此,你可以一目十行,但绝对做不到一开口就读十行字,哪怕十个字也做不到。
既然访问速度快,要好好利用啊!Java就把对象的引用放在栈里。为什么呢?因为引用的使用频率高吗?
不是的,因为Java在编译程序时,必须明确的知道存储在栈里的东西的生命周期,否则就没法释放旧的内存来开辟新的内存空间存放引用——空间就那么大,前浪要把后浪拍死在沙滩上啊。
现在清楚堆、栈和堆栈了吧?
先来看《Java编程思想》中的一段话:
在程序设计中经常用到一系列类型,他们需要特殊对待。之所以特殊对待,是因为new将对象存储于“堆”中,故用new创建一个对象──特别小、简单的变量,往往不是很有效。因此,不用new来创建这类变量,而是创建一个并非是引用的变量,这个变量直接存储值,并置于栈中,因此更加高效。
在Java中,这些基本类型有:boolean、char、byte、short、int、long、float、double和void;还有与之对应的包装器:Boolean、Character、Byte、Short、Integer、Long、Float、Double和Void;他们之间涉及到装箱和拆箱,我们有机会再聊。
看两行简单的代码:
1 | int a = 3; |
这两行代码在编译的时候是什么样子呢?
编译器当然是先处理int a = 3;,不然还能跳过吗?编译器在处理int a = 3;时在栈中创建了一个变量为a的内存空间,然后查找有没有字面值为3的地址,没找到,就开辟一个存放3这个字面值的地址,然后将a指向3的地址。
编译器忙完了int a = 3;,就来接着处理int b = 3;;在创建完b的变量后,由于栈中已经有3这个字面值,就将b直接指向3的地址;就不需要再开辟新的空间了。
依据上面的概述,我们假设在定义完a与b的值后,再令a=4,此时b是等于3呢,还是4呢?
思考一下,再看答案哈。
答案揭晓:当编译器遇到a = 4;时,它会重新搜索栈中是否有4的字面值,如果没有,重新开辟地址存放4的值;如果已经有了,则直接将a指向4这个地址;因此a值的改变不会影响到b的值哦。
最后,留个作业吧,下面这段代码在运行时会输出什么呢?
1 | public class Test1 { |
大家都知道,Java的泛型是伪泛型,这是因为Java在编译期间,所有的泛型信息都会被擦掉,正确理解泛型概念的首要前提是理解类型擦除。Java的泛型基本上都是在编译器这个层次上实现的,在生成的字节码中是不包含泛型中的类型信息的,使用泛型的时候加上类型参数,在编译器编译的时候会去掉,这个过程成为类型擦除。
如在代码中定义 List<Object>和 List<String>等类型,在编译后都会变成 List,JVM看到的只是List,而由泛型附加的类型信息对JVM是看不到的。Java编译器会在编译时尽可能的发现可能出错的地方,但是仍然无法在运行时刻出现的类型转换异常的情况,类型擦除也是Java的泛型与C++模板机制实现方式之间的重要区别。
例1.原始类型相等
1 | public class Test { |
在这个例子中,我们定义了两个 ArrayList数组,不过一个是 ArrayList<String>泛型类型的,只能存储字符串;一个是 ArrayList<Integer>泛型类型的,只能存储整数,最后,我们通过 list1对象和 list2对象的 getClass()方法获取他们的类的信息,最后发现结果为 true。说明泛型类型 String和 Integer都被擦除掉了,只剩下原始类型。
例2.通过反射添加其它类型元素
1 | public class Test { |
在程序中定义了一个 ArrayList泛型类型实例化为 Integer对象,如果直接调用 add()方法,那么只能存储整数数据,不过当我们利用反射调用 add()方法的时候,却可以存储字符串,这说明了 Integer泛型实例在编译之后被擦除掉了,只保留了原始类型。
在上面,两次提到了原始类型,什么是原始类型?
原始类型 就是擦除去了泛型信息,最后在字节码中的类型变量的真正类型,无论何时定义一个泛型,相应的原始类型都会被自动提供,类型变量擦除,并使用其限定类型(无限定的变量用Object)替换。
例3.原始类型Object
1 | class Pair<t> { |
Pair的原始类型为:
1 | class Pair { |
因为在 Pair<t></t>中,T 是一个无限定的类型变量,所以用 Object替换,其结果就是一个普通的类,如同泛型加入Java语言之前的已经实现的样子。在程序中可以包含不同类型的 Pair,如 Pair<String>或 Pair<Integer>,但是擦除类型后他们的就成为原始的 Pair类型了,原始类型都是 Object。
从上面的例2中,我们也可以明白 ArrayList<Integer>被擦除类型后,原始类型也变为 Object,所以通过反射我们就可以存储字符串了。
如果类型变量有限定,那么原始类型就用第一个边界的类型变量类替换。
比如: Pair这样声明的话
1 | public class Pair<t extends comparable> {} |
那么原始类型就是 Comparable。
要区分原始类型和泛型变量的类型。
在调用泛型方法时,可以指定泛型,也可以不指定泛型。
1 | public class Test { |
其实在泛型类中,不指定泛型的时候,也差不多,只不过这个时候的泛型为 Object,就比如 ArrayList中,如果不指定泛型,那么这个 ArrayList可以存储任意的对象。
例4.Object泛型
1 | public static void main(String[] args) { |
因为种种原因,Java不能实现真正的泛型,只能使用类型擦除来实现伪泛型,这样虽然不会有类型膨胀问题,但是也引起来许多新问题,所以,SUN对这些问题做出了种种限制,避免我们发生各种错误。
Q: 既然说类型变量会在编译的时候擦除掉,那为什么我们往 ArrayList 创建的对象中添加整数会报错呢?不是说泛型变量String会在编译的时候变为Object类型吗?为什么不能存别的类型呢?既然类型擦除了,如何保证我们只能使用泛型变量限定的类型呢?
A: Java编译器是通过先检查代码中泛型的类型,然后再进行类型擦除,再进行编译。
例如:
1 | public static void main(String[] args) { |
在上面的程序中,使用 add方法添加一个整型,在IDE中,直接会报错,说明这就是在编译之前的检查,因为如果是在编译之后检查,类型擦除后,原始类型为 Object,是应该允许任意引用类型添加的。可实际上却不是这样的,这恰恰说明了关于泛型变量的使用,是会在编译之前检查的。
那么,这个类型检查是针对谁的呢?我们先看看参数化类型和原始类型的兼容。
以 ArrayList举例子,以前的写法:
1 | ArrayList list = new ArrayList(); |
现在的写法:
1 | ArrayList<String> list = new ArrayList<String>(); |
如果是与以前的代码兼容,各种引用传值之间,必然会出现如下的情况:
1 | ArrayList<String> list1 = new ArrayList(); //第一种情况 |
这样是没有错误的,不过会有个编译时警告。
不过在第一种情况,可以实现与完全使用泛型参数一样的效果,第二种则没有效果。
因为类型检查就是编译时完成的, new ArrayList()只是在内存中开辟了一个存储空间,可以存储任何类型对象,而真正设计类型检查的是它的引用,因为我们是使用它引用 list1来调用它的方法,比如说调用 add方法,所以 list1引用能完成泛型类型的检查。而引用 list2没有使用泛型,所以不行。
举例子:
1 | public class Test { |
通过上面的例子,我们可以明白,类型检查就是针对引用的,谁是一个引用,用这个引用调用泛型方法,就会对这个引用调用的方法进行类型检测,而无关它真正引用的对象。
泛型中参数化类型为什么不考虑继承关系?
在Java中,像下面形式的引用传递是不允许的:
1 | ArrayList<String> list1 = new ArrayList<object>(); //编译错误 ArrayList<Object> |
我们先看第一种情况,将第一种情况拓展成下面的形式:
1 | ArrayList<object> list1 = new ArrayList<object>(); |
实际上,在第4行代码的时候,就会有编译错误。那么,我们先假设它编译没错。那么当我们使用 list2引用用 get()方法取值的时候,返回的都是 String类型的对象(上面提到了,类型检测是根据引用来决定的),可是它里面实际上已经被我们存放了 Object类型的对象,这样就会有 ClassCastException了。所以为了避免这种极易出现的错误,Java不允许进行这样的引用传递。(这也是泛型出现的原因,就是为了解决类型转换的问题,我们不能违背它的初衷)。
再看第二种情况,将第二种情况拓展成下面的形式:
1 | ArrayList<String> list1 = new ArrayList<String>(); |
没错,这样的情况比第一种情况好的多,最起码,在我们用 list2取值的时候不会出现 ClassCastException,因为是从 String转换为 Object。可是,这样做有什么意义呢,泛型出现的原因,就是为了解决类型转换的问题。我们使用了泛型,到头来,还是要自己强转,违背了泛型设计的初衷。所以java不允许这么干。再说,你如果又用 list2往里面 add()新的对象,那么到时候取得时候,我怎么知道我取出来的到底是 String类型的,还是 Object类型的呢?
所以,要格外注意,泛型中的引用传递的问题。
因为类型擦除的问题,所以所有的泛型类型变量最后都会被替换为原始类型。
既然都被替换为原始类型,那么为什么我们在获取的时候,不需要进行强制类型转换呢?
看下 ArrayList.get()方法:
1 | public E get(int index) { |
可以看到,在 return之前,会根据泛型变量进行强转。假设泛型类型变量为 Date,虽然泛型信息会被擦除掉,但是会将 (E) elementData[index],编译为 (Date)elementData[index]。所以我们不用自己进行强转。当存取一个泛型域时也会自动插入强制类型转换。假设 Pair类的 value域是 public的,那么表达式:
1 | Date Date = pair.value; |
也会自动地在结果字节码中插入强制类型转换。
现在有这样一个泛型类:
1 | class Pair<t> { |
然后我们想要一个子类继承它。
1 | class DateInter extends Pair<Date> { |
在这个子类中,我们设定父类的泛型类型为 Pair<Date>,在子类中,我们覆盖了父类的两个方法,我们的原意是这样的:将父类的泛型类型限定为 Date,那么父类里面的两个方法的参数都为 Date类型。
1 | public Date getValue() { |
所以,我们在子类中重写这两个方法一点问题也没有,实际上,从他们的 @Override标签中也可以看到,一点问题也没有,实际上是这样的吗?
分析:实际上,类型擦除后,父类的的泛型类型全部变为了原始类型 Object,所以父类编译之后会变成下面的样子:
1 | class Pair { |
再看子类的两个重写的方法的类型:
1 |
|
先来分析 setValue方法,父类的类型是 Object,而子类的类型是 Date,参数类型不一样,这如果是在普通的继承关系中,根本就不会是重写,而是重载。
我们在一个main方法测试一下:
1 | public static void main(String[] args) throws ClassNotFoundException { |
如果是重载,那么子类中两个 setValue方法,一个是参数 Object类型,一个是 Date类型,可是我们发现,根本就没有这样的一个子类继承自父类的Object类型参数的方法。所以说,确实是重写了,而不是重载了。
为什么会这样呢?
原因是这样的,我们传入父类的泛型类型是 Date, Pair<Date>,我们的本意是将泛型类变为如下:
1 | class Pair { |
然后在子类中重写参数类型为Date的那两个方法,实现继承中的多态。
可是由于种种原因,虚拟机并不能将泛型类型变为 Date,只能将类型擦除掉,变为原始类型 Object。这样,我们的本意是进行重写,实现多态。可是类型擦除后,只能变为了重载。这样,类型擦除就和多态有了冲突。JVM知道你的本意吗?知道!!!可是它能直接实现吗,不能!!!如果真的不能的话,那我们怎么去重写我们想要的 Date类型参数的方法啊。
于是JVM采用了一个特殊的方法,来完成这项功能,那就是桥方法。
首先,我们用 javap -c className的方式反编译下 DateInter子类的字节码,结果如下:
1 | class com.tao.test.DateInter extends com.tao.test.Pair<java.util.Date> { |
从编译的结果来看,我们本意重写 setValue和 getValue方法的子类,竟然有4个方法,其实不用惊奇,最后的两个方法,就是编译器自己生成的桥方法。可以看到桥方法的参数类型都是Object,也就是说,子类中真正覆盖父类两个方法的就是这两个我们看不到的桥方法。而打在我们自己定义的 setvalue和 getValue方法上面的 @Override只不过是假象。而桥方法的内部实现,就只是去调用我们自己重写的那两个方法。
所以,虚拟机巧妙的使用了桥方法,来解决了类型擦除和多态的冲突。
不过,要提到一点,这里面的 setValue和 getValue这两个桥方法的意义又有不同。
setValue方法是为了解决类型擦除与多态之间的冲突。
而 getValue却有普遍的意义,怎么说呢,如果这是一个普通的继承关系:
那么父类的 setValue方法如下:
1 | public Object getValue() { |
而子类重写的方法是:
1 | public Date getValue() { |
其实这在普通的类继承中也是普遍存在的重写,这就是协变。
关于协变:。。。。。。
并且,还有一点也许会有疑问,子类中的桥方法 Object getValue()和 Date getValue()是同 时存在的,可是如果是常规的两个方法,他们的方法签名是一样的,也就是说虚拟机根本不能分别这两个方法。如果是我们自己编写Java代码,这样的代码是无法通过编译器的检查的,但是虚拟机却是允许这样做的,因为虚拟机通过参数类型和返回类型来确定一个方法,所以编译器为了实现泛型的多态允许自己做这个看起来”不合法”的事情,然后交给虚拟器去区别。
不能用类型参数替换基本类型。就比如,没有 ArrayList<double>,只有 ArrayList<Double>。因为当类型擦除后, ArrayList的原始类型变为 Object,但是 Object类型不能存储 double值,只能引用 Double的值。
1 | ArrayList<String> arrayList = new ArrayList<String>(); |
因为类型擦除之后, ArrayList<String>只剩下原始类型,泛型信息 String不存在了。
那么,编译时进行类型查询的时候使用下面的方法是错误的
1 | if( arrayList instanceof ArrayList<String>) |
泛型类中的静态方法和静态变量不可以使用泛型类所声明的泛型类型参数
举例说明:
1 | public class Test2<T> { |
因为泛型类中的泛型参数的实例化的时候确定,而静态变量和静态方法不需要使用对象来调用。对象都没有创建,如何确定这个泛型参数是何种类型,所以当然是错误的。
但是要注意区分下面的一种情况:
1 | public class Test2<T> { |
因为这是一个泛型方法,在泛型方法中使用的T是自己在方法中定义的 T,而不是泛型类中的T。
随着计算机行业的飞速发展,摩尔定律逐渐失效,多核CPU成为主流。使用多线程并行计算逐渐成为开发人员提升服务器性能的基本武器。J.U.C提供的线程池:ThreadPoolExecutor类,帮助开发人员管理线程并方便地执行并行任务。了解并合理使用线程池,是一个开发人员必修的基本功。
本文开篇简述线程池概念和用途,接着结合线程池的源码,帮助读者领略线程池的设计思路,最后回归实践,通过案例讲述使用线程池遇到的问题,并给出了一种动态化线程池解决方案。
线程池(Thread Pool)是一种基于池化思想管理线程的工具,经常出现在多线程服务器中,如MySQL。
线程过多会带来额外的开销,其中包括创建销毁线程的开销、调度线程的开销等等,同时也降低了计算机的整体性能。线程池维护多个线程,等待监督管理者分配可并发执行的任务。这种做法,一方面避免了处理任务时创建销毁线程开销的代价,另一方面避免了线程数量膨胀导致的过分调度问题,保证了对内核的充分利用。
而本文描述线程池是JDK中提供的ThreadPoolExecutor类。
当然,使用线程池可以带来一系列好处:
线程池解决的核心问题就是资源管理问题。在并发环境下,系统不能够确定在任意时刻中,有多少任务需要执行,有多少资源需要投入。这种不确定性将带来以下若干问题:
为解决资源分配这个问题,线程池采用了“池化”(Pooling)思想。池化,顾名思义,是为了最大化收益并最小化风险,而将资源统一在一起管理的一种思想。
Pooling is the grouping together of resources (assets, equipment, personnel, effort, etc.) for the purposes of maximizing advantage or minimizing risk to the users. The term is used in finance, computing and equipment management.——wikipedia
“池化”思想不仅仅能应用在计算机领域,在金融、设备、人员管理、工作管理等领域也有相关的应用。
在计算机领域中的表现为:统一管理IT资源,包括服务器、存储、和网络资源等等。通过共享资源,使用户在低投入中获益。除去线程池,还有其他比较典型的几种使用策略包括:
在了解完“是什么”和“为什么”之后,下面我们来一起深入一下线程池的内部实现原理。
在前文中,我们了解到:线程池是一种通过“池化”思想,帮助我们管理线程而获取并发性的工具,在Java中的体现是ThreadPoolExecutor类。那么它的的详细设计与实现是什么样的呢?我们会在本章进行详细介绍。
Java中的线程池核心实现类是ThreadPoolExecutor,本章基于JDK 1.8的源码来分析Java线程池的核心设计与实现。我们首先来看一下ThreadPoolExecutor的UML类图,了解下ThreadPoolExecutor的继承关系。
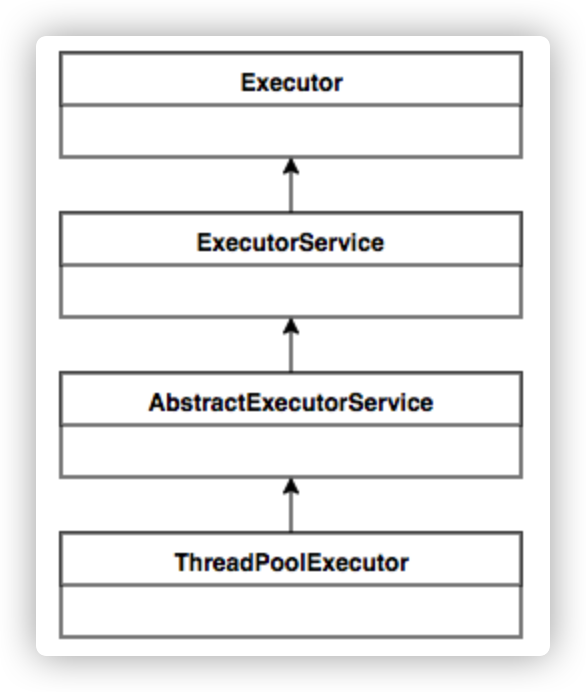
ThreadPoolExecutor实现的顶层接口是Executor,顶层接口Executor提供了一种思想:将任务提交和任务执行进行解耦。用户无需关注如何创建线程,如何调度线程来执行任务,用户只需提供Runnable对象,将任务的运行逻辑提交到执行器(Executor)中,由Executor框架完成线程的调配和任务的执行部分。ExecutorService接口增加了一些能力:(1)扩充执行任务的能力,补充可以为一个或一批异步任务生成Future的方法;(2)提供了管控线程池的方法,比如停止线程池的运行。AbstractExecutorService则是上层的抽象类,将执行任务的流程串联了起来,保证下层的实现只需关注一个执行任务的方法即可。最下层的实现类ThreadPoolExecutor实现最复杂的运行部分,ThreadPoolExecutor将会一方面维护自身的生命周期,另一方面同时管理线程和任务,使两者良好的结合从而执行并行任务。
ThreadPoolExecutor是如何运行,如何同时维护线程和执行任务的呢?其运行机制如下图所示:\
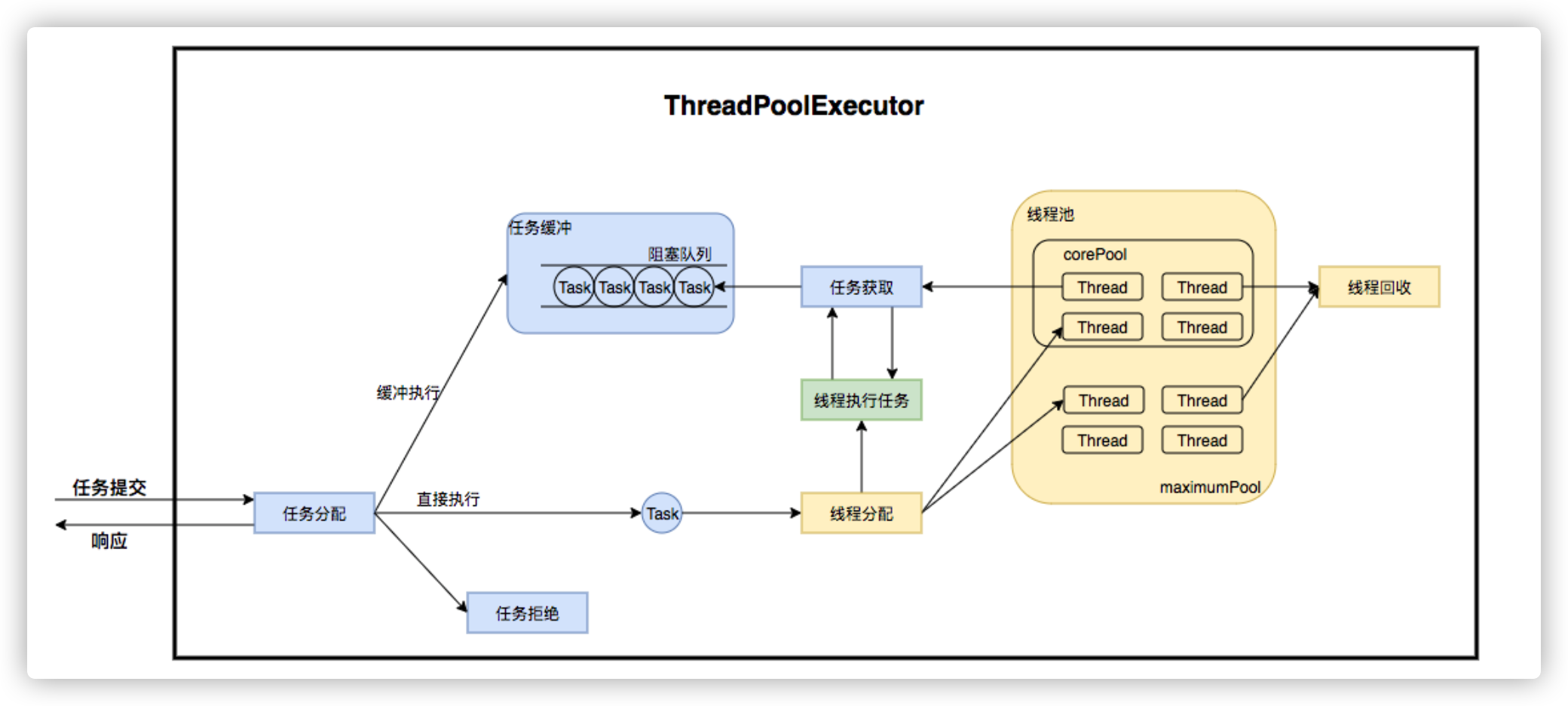
线程池在内部实际上构建了一个生产者消费者模型,将线程和任务两者解耦,并不直接关联,从而良好的缓冲任务,复用线程。线程池的运行主要分成两部分:任务管理、线程管理。任务管理部分充当生产者的角色,当任务提交后,线程池会判断该任务后续的流转:(1)直接申请线程执行该任务;(2)缓冲到队列中等待线程执行;(3)拒绝该任务。线程管理部分是消费者,它们被统一维护在线程池内,根据任务请求进行线程的分配,当线程执行完任务后则会继续获取新的任务去执行,最终当线程获取不到任务的时候,线程就会被回收。
接下来,我们会按照以下三个部分去详细讲解线程池运行机制:
线程池运行的状态,并不是用户显式设置的,而是伴随着线程池的运行,由内部来维护。线程池内部使用一个变量维护两个值:运行状态(runState)和线程数量 (workerCount)。在具体实现中,线程池将运行状态(runState)、线程数量 (workerCount)两个关键参数的维护放在了一起,如下代码所示:
1 | private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0)); |
ctl这个AtomicInteger类型,是对线程池的运行状态和线程池中有效线程的数量进行控制的一个字段, 它同时包含两部分的信息:线程池的运行状态 (runState) 和线程池内有效线程的数量 (workerCount),高3位保存runState,低29位保存workerCount,两个变量之间互不干扰。用一个变量去存储两个值,可避免在做相关决策时,出现不一致的情况,不必为了维护两者的一致,而占用锁资源。通过阅读线程池源代码也可以发现,经常出现要同时判断线程池运行状态和线程数量的情况。线程池也提供了若干方法去供用户获得线程池当前的运行状态、线程个数。这里都使用的是位运算的方式,相比于基本运算,速度也会快很多。
关于内部封装的获取生命周期状态、获取线程池线程数量的计算方法如以下代码所示:
1 | private static int runStateOf(int c) { return c & ~CAPACITY; } //计算当前运行状态 |
ThreadPoolExecutor的运行状态有5种,分别为:

其生命周期转换如下入所示:
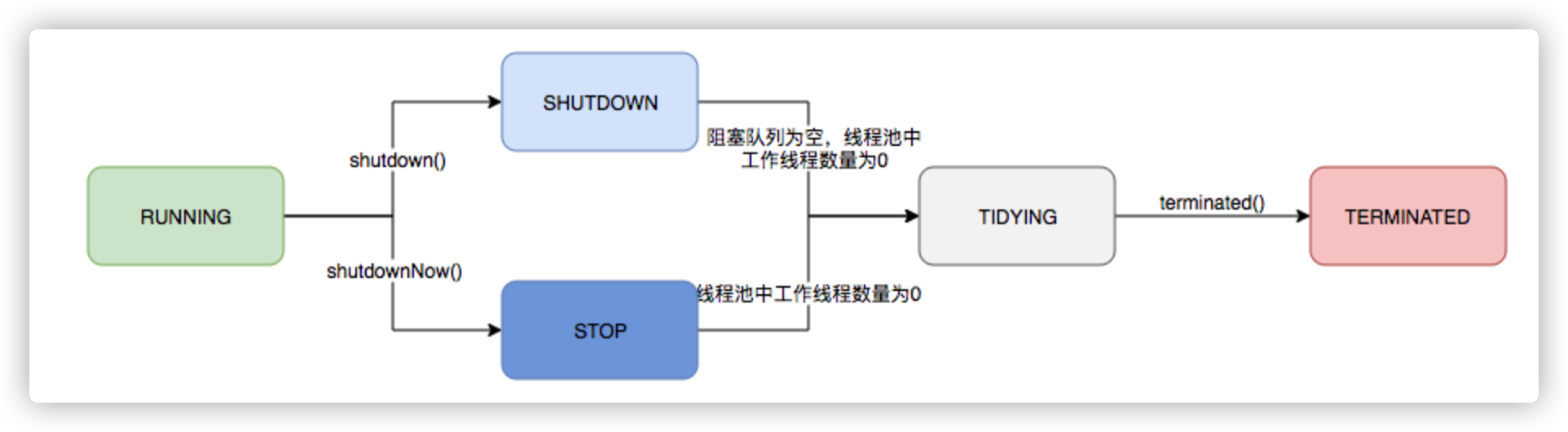
图3 线程池生命周期
2.3.1 任务调度
任务调度是线程池的主要入口,当用户提交了一个任务,接下来这个任务将如何执行都是由这个阶段决定的。了解这部分就相当于了解了线程池的核心运行机制。
首先,所有任务的调度都是由execute方法完成的,这部分完成的工作是:检查现在线程池的运行状态、运行线程数、运行策略,决定接下来执行的流程,是直接申请线程执行,或是缓冲到队列中执行,亦或是直接拒绝该任务。其执行过程如下:
其执行流程如下图所示:
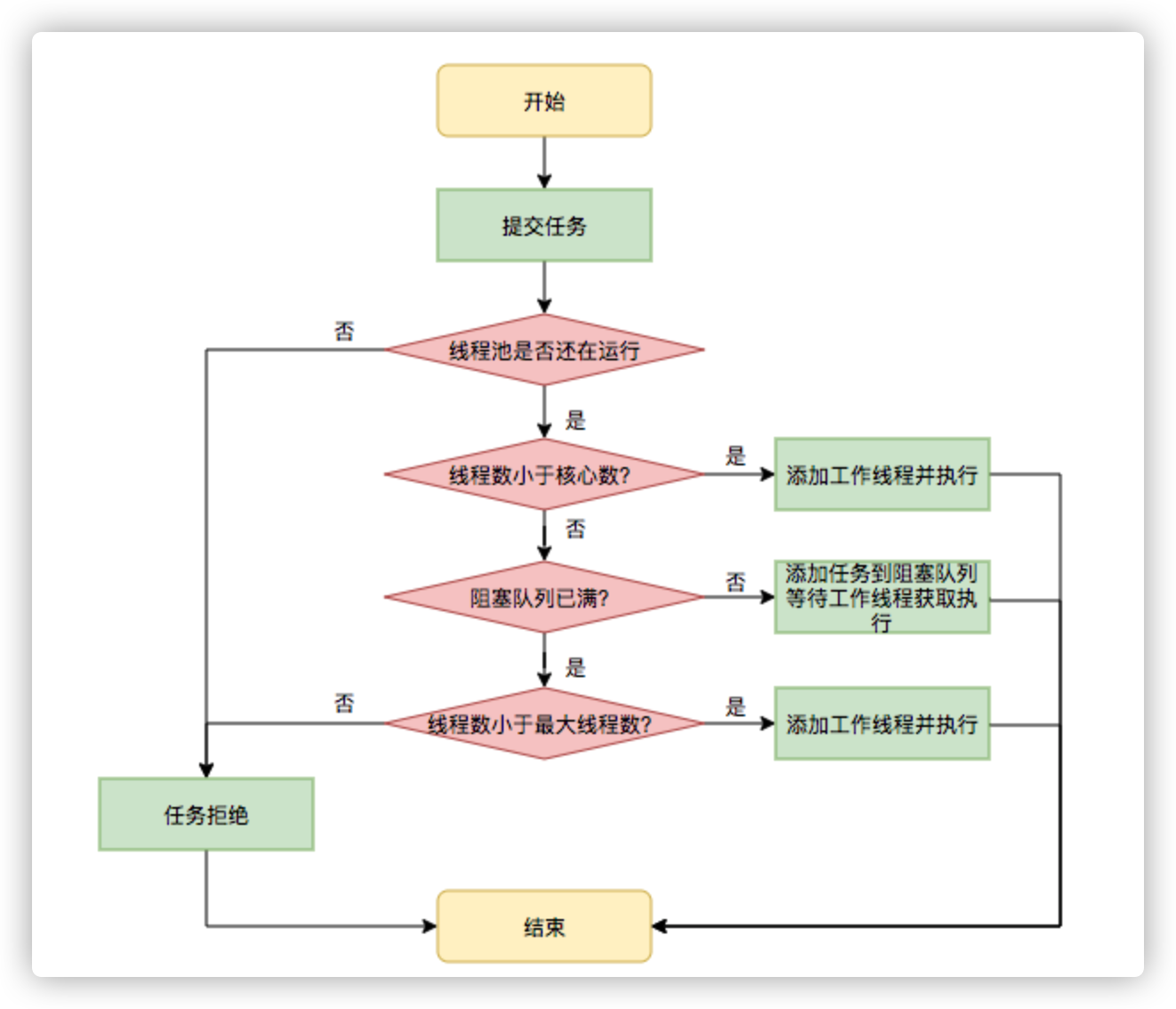
2.3.2 任务缓冲
任务缓冲模块是线程池能够管理任务的核心部分。线程池的本质是对任务和线程的管理,而做到这一点最关键的思想就是将任务和线程两者解耦,不让两者直接关联,才可以做后续的分配工作。线程池中是以生产者消费者模式,通过一个阻塞队列来实现的。阻塞队列缓存任务,工作线程从阻塞队列中获取任务。
阻塞队列(BlockingQueue)是一个支持两个附加操作的队列。这两个附加的操作是:在队列为空时,获取元素的线程会等待队列变为非空。当队列满时,存储元素的线程会等待队列可用。阻塞队列常用于生产者和消费者的场景,生产者是往队列里添加元素的线程,消费者是从队列里拿元素的线程。阻塞队列就是生产者存放元素的容器,而消费者也只从容器里拿元素。
下图中展示了线程1往阻塞队列中添加元素,而线程2从阻塞队列中移除元素:
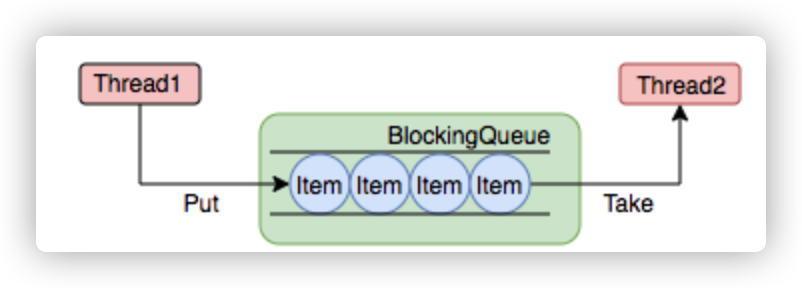
使用不同的队列可以实现不一样的任务存取策略。在这里,我们可以再介绍下阻塞队列的成员:

2.3.3 任务申请
由上文的任务分配部分可知,任务的执行有两种可能:一种是任务直接由新创建的线程执行。另一种是线程从任务队列中获取任务然后执行,执行完任务的空闲线程会再次去从队列中申请任务再去执行。第一种情况仅出现在线程初始创建的时候,第二种是线程获取任务绝大多数的情况。
线程需要从任务缓存模块中不断地取任务执行,帮助线程从阻塞队列中获取任务,实现线程管理模块和任务管理模块之间的通信。这部分策略由getTask方法实现,其执行流程如下图所示:
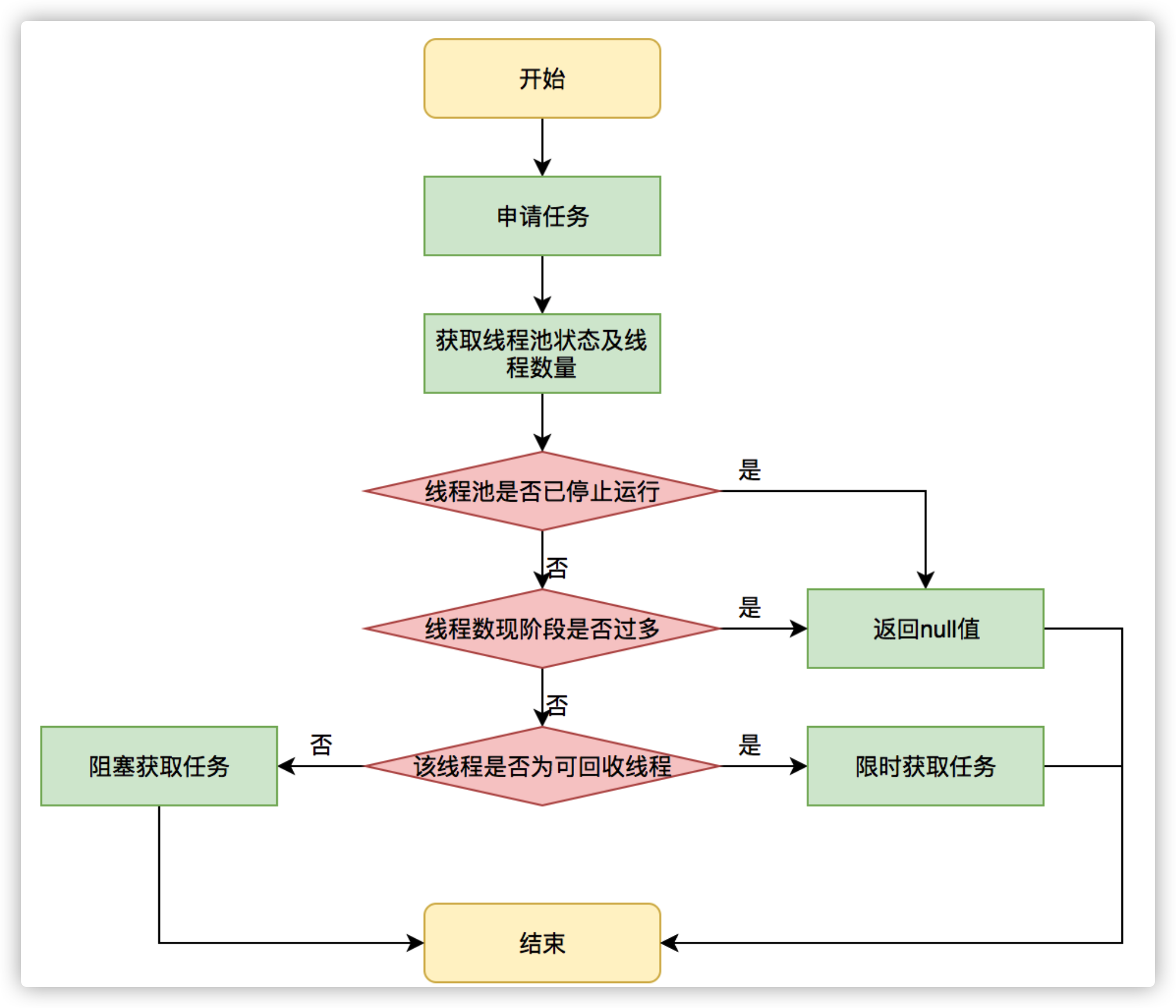
getTask这部分进行了多次判断,为的是控制线程的数量,使其符合线程池的状态。如果线程池现在不应该持有那么多线程,则会返回null值。工作线程Worker会不断接收新任务去执行,而当工作线程Worker接收不到任务的时候,就会开始被回收。
2.3.4 任务拒绝
任务拒绝模块是线程池的保护部分,线程池有一个最大的容量,当线程池的任务缓存队列已满,并且线程池中的线程数目达到maximumPoolSize时,就需要拒绝掉该任务,采取任务拒绝策略,保护线程池。
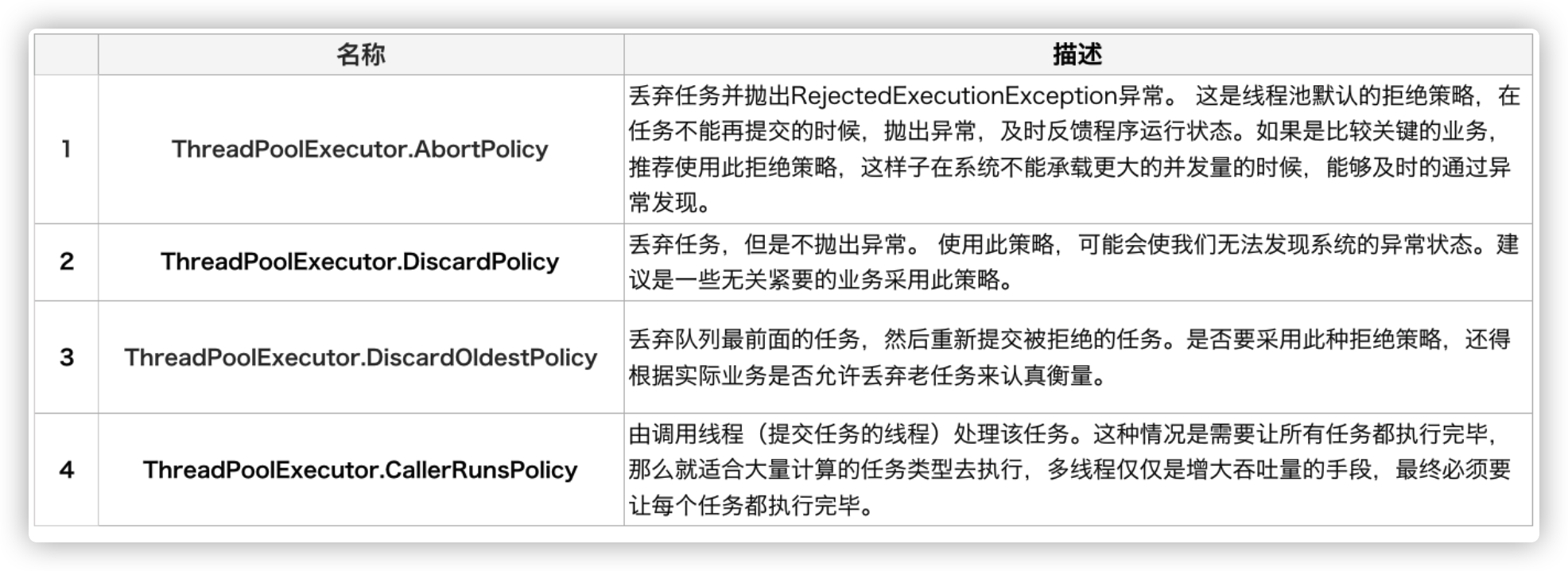
拒绝策略是一个接口,其设计如下:
1 | public interface RejectedExecutionHandler { |
用户可以通过实现这个接口去定制拒绝策略,也可以选择JDK提供的四种已有拒绝策略,其特点如下:
2.4 Worker线程管理
2.4.1 Worker线程
线程池为了掌握线程的状态并维护线程的生命周期,设计了线程池内的工作线程Worker。我们来看一下它的部分代码:
1 | private final class Worker extends AbstractQueuedSynchronizer implements Runnable{ |
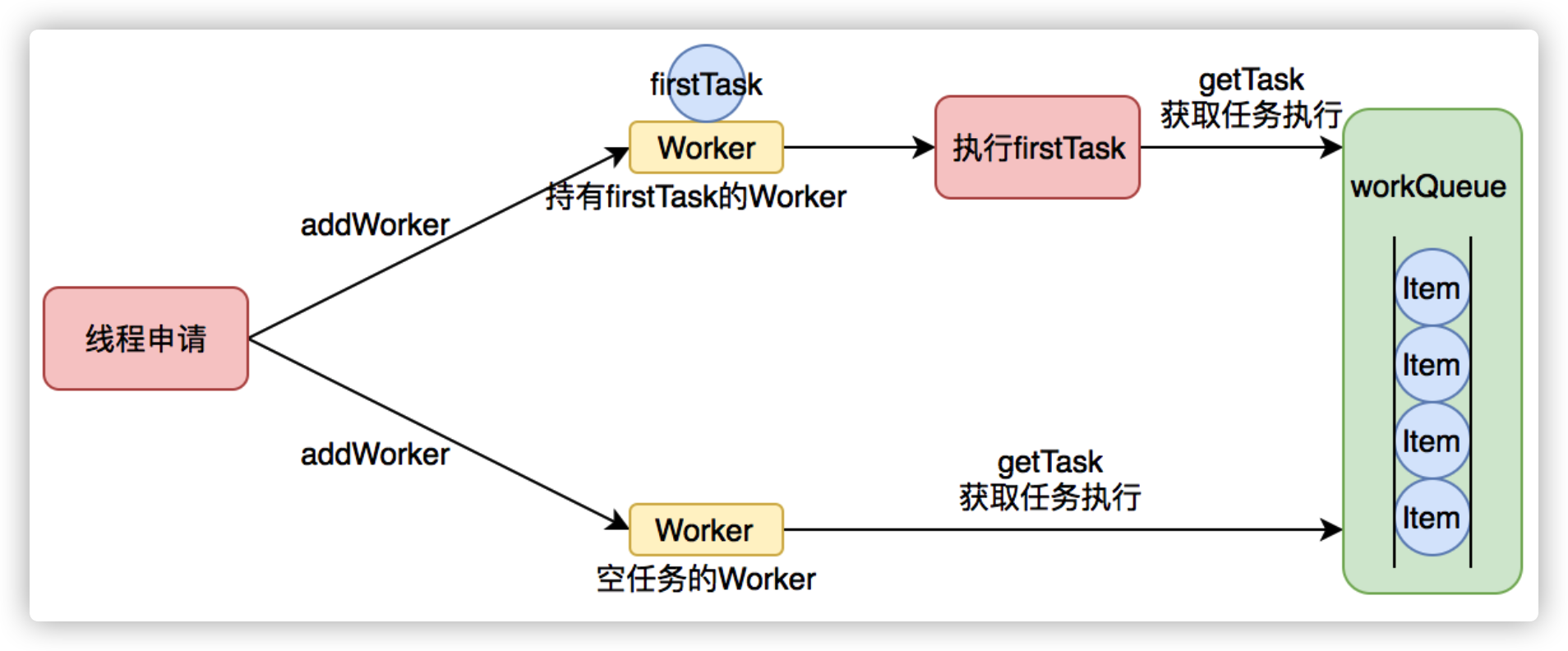
Worker这个工作线程,实现了Runnable接口,并持有一个线程thread,一个初始化的任务firstTask。thread是在调用构造方法时通过ThreadFactory来创建的线程,可以用来执行任务;firstTask用它来保存传入的第一个任务,这个任务可以有也可以为null。如果这个值是非空的,那么线程就会在启动初期立即执行这个任务,也就对应核心线程创建时的情况;如果这个值是null,那么就需要创建一个线程去执行任务列表(workQueue)中的任务,也就是非核心线程的创建。
Worker执行任务的模型如下图所示:
线程池需要管理线程的生命周期,需要在线程长时间不运行的时候进行回收。线程池使用一张Hash表去持有线程的引用,这样可以通过添加引用、移除引用这样的操作来控制线程的生命周期。这个时候重要的就是如何判断线程是否在运行。
Worker是通过继承AQS,使用AQS来实现独占锁这个功能。没有使用可重入锁ReentrantLock,而是使用AQS,为的就是实现不可重入的特性去反应线程现在的执行状态。
1.lock方法一旦获取了独占锁,表示当前线程正在执行任务中。 2.如果正在执行任务,则不应该中断线程。 3.如果该线程现在不是独占锁的状态,也就是空闲的状态,说明它没有在处理任务,这时可以对该线程进行中断。 4.线程池在执行shutdown方法或tryTerminate方法时会调用interruptIdleWorkers方法来中断空闲的线程,interruptIdleWorkers方法会使用tryLock方法来判断线程池中的线程是否是空闲状态;如果线程是空闲状态则可以安全回收。
在线程回收过程中就使用到了这种特性,回收过程如下图所示:
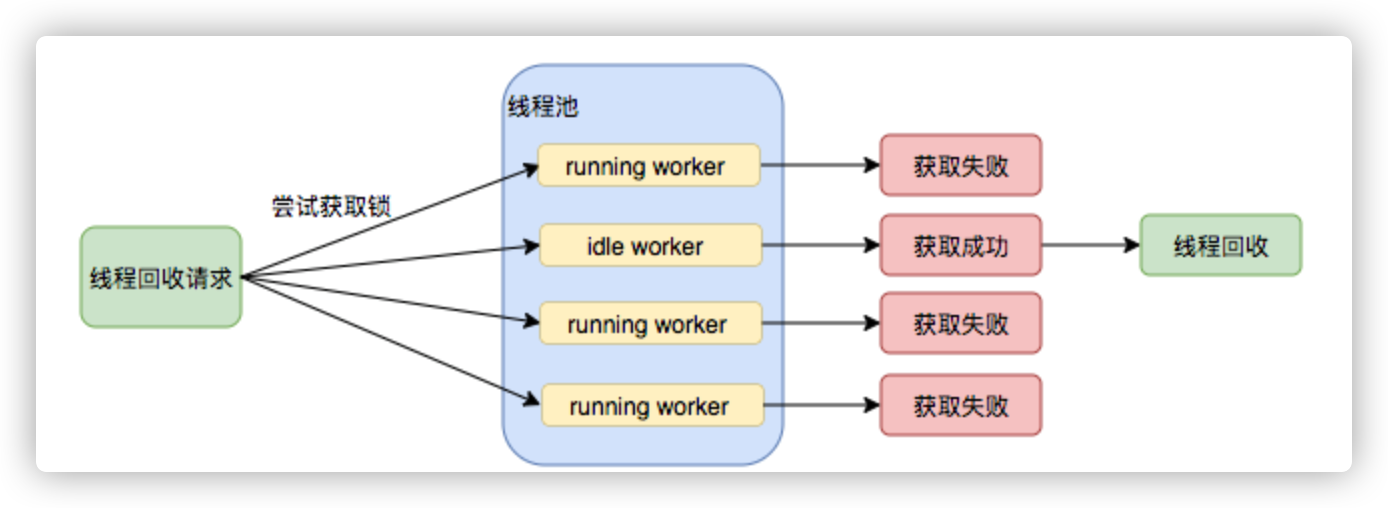
图8 线程池回收过程
2.4.2 Worker线程增加
增加线程是通过线程池中的addWorker方法,该方法的功能就是增加一个线程,该方法不考虑线程池是在哪个阶段增加的该线程,这个分配线程的策略是在上个步骤完成的,该步骤仅仅完成增加线程,并使它运行,最后返回是否成功这个结果。addWorker方法有两个参数:firstTask、core。firstTask参数用于指定新增的线程执行的第一个任务,该参数可以为空;core参数为true表示在新增线程时会判断当前活动线程数是否少于corePoolSize,false表示新增线程前需要判断当前活动线程数是否少于maximumPoolSize,其执行流程如下图所示:
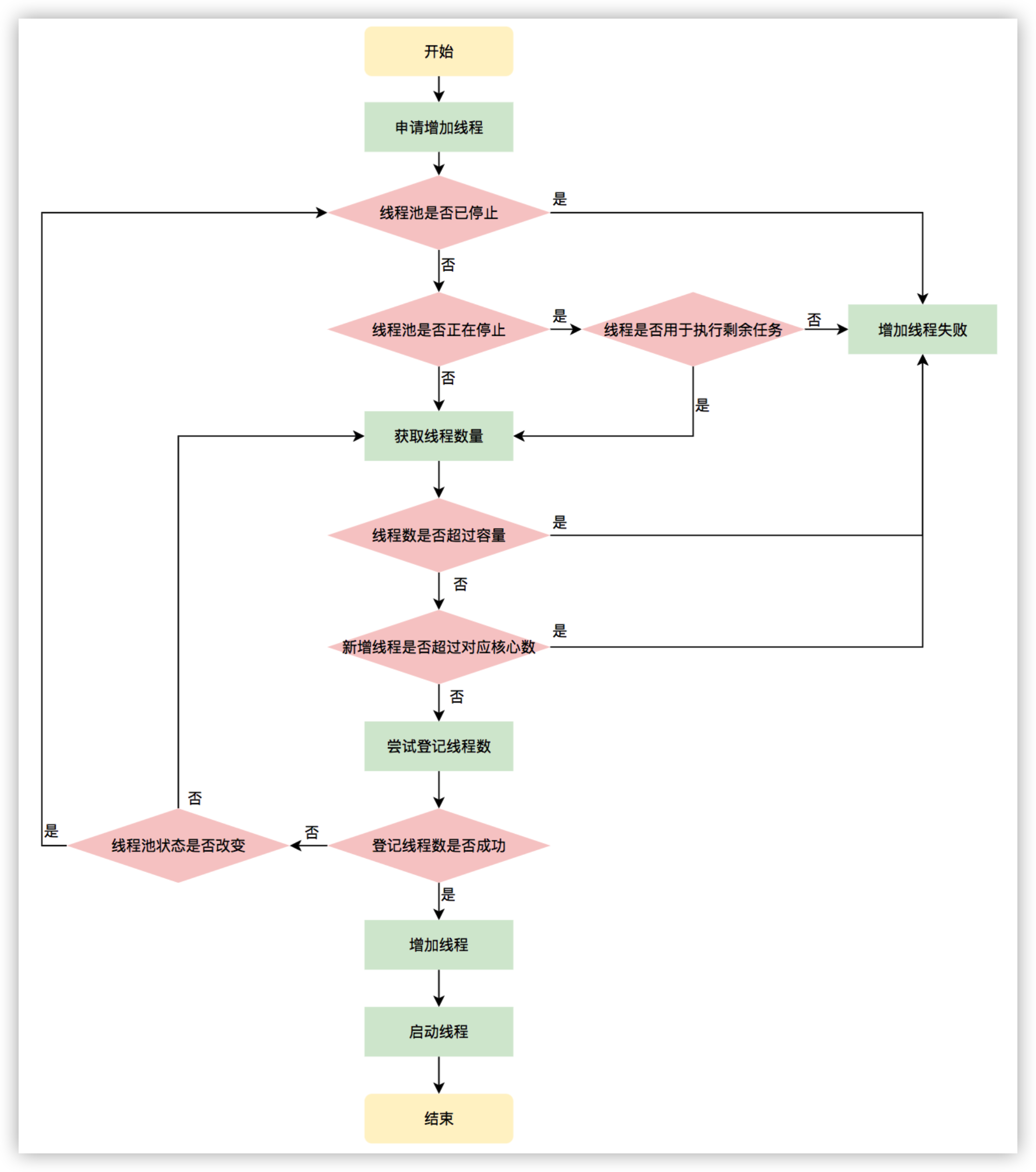
图9 申请线程执行流程图
2.4.3 Worker线程回收
线程池中线程的销毁依赖JVM自动的回收,线程池做的工作是根据当前线程池的状态维护一定数量的线程引用,防止这部分线程被JVM回收,当线程池决定哪些线程需要回收时,只需要将其引用消除即可。Worker被创建出来后,就会不断地进行轮询,然后获取任务去执行,核心线程可以无限等待获取任务,非核心线程要限时获取任务。当Worker无法获取到任务,也就是获取的任务为空时,循环会结束,Worker会主动消除自身在线程池内的引用。
1 | try { |
线程回收的工作是在processWorkerExit方法完成的。

图10 线程销毁流程
事实上,在这个方法中,将线程引用移出线程池就已经结束了线程销毁的部分。但由于引起线程销毁的可能性有很多,线程池还要判断是什么引发了这次销毁,是否要改变线程池的现阶段状态,是否要根据新状态,重新分配线程。
2.4.4 Worker线程执行任务
在Worker类中的run方法调用了runWorker方法来执行任务,runWorker方法的执行过程如下:
1.while循环不断地通过getTask()方法获取任务。 2.getTask()方法从阻塞队列中取任务。 3.如果线程池正在停止,那么要保证当前线程是中断状态,否则要保证当前线程不是中断状态。 4.执行任务。 5.如果getTask结果为null则跳出循环,执行processWorkerExit()方法,销毁线程。
执行流程如下图所示:
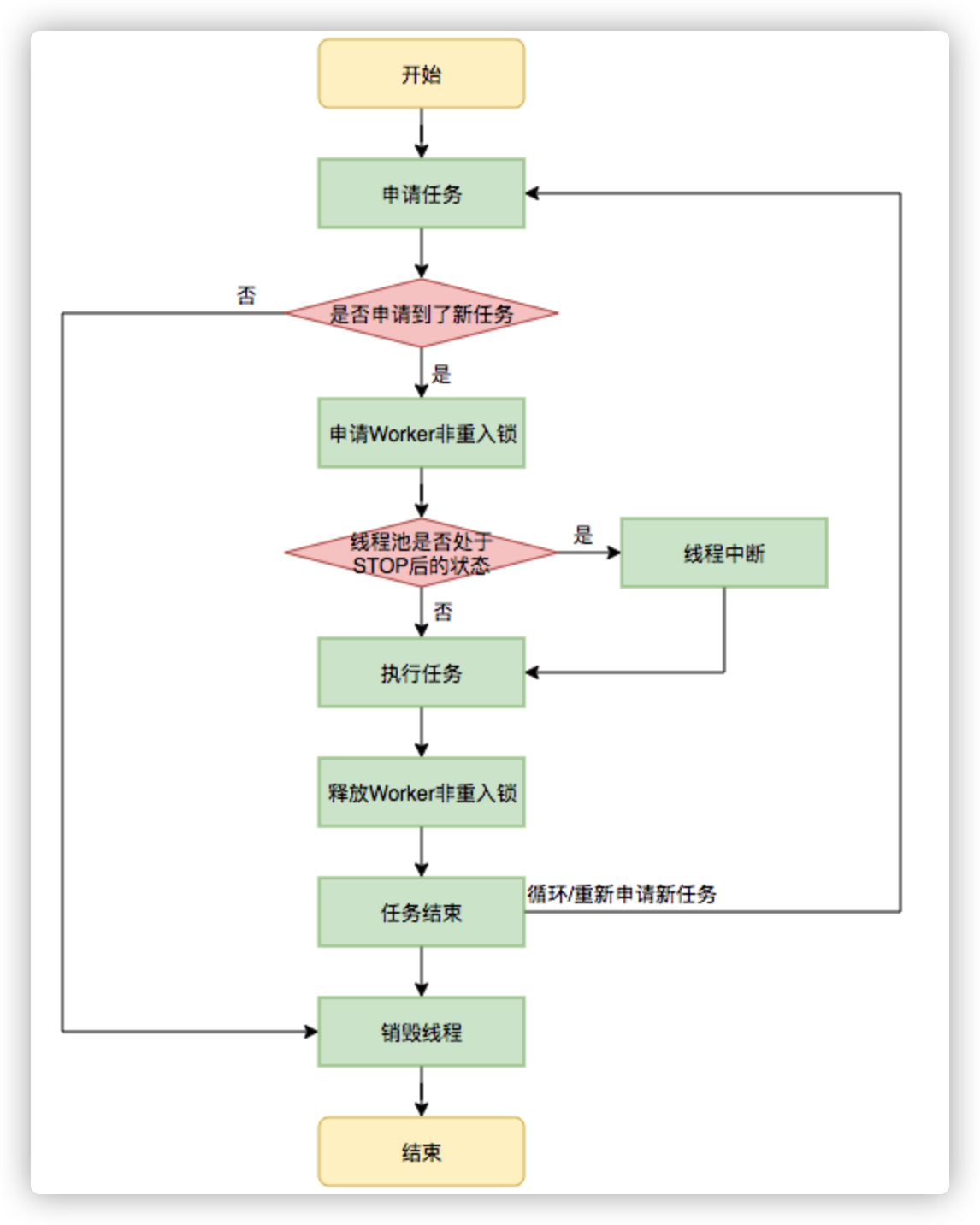
图11 执行任务流程
在当今的互联网业界,为了最大程度利用CPU的多核性能,并行运算的能力是不可或缺的。通过线程池管理线程获取并发性是一个非常基础的操作,让我们来看两个典型的使用线程池获取并发性的场景。
场景1:快速响应用户请求
描述:用户发起的实时请求,服务追求响应时间。比如说用户要查看一个商品的信息,那么我们需要将商品维度的一系列信息如商品的价格、优惠、库存、图片等等聚合起来,展示给用户。
分析:从用户体验角度看,这个结果响应的越快越好,如果一个页面半天都刷不出,用户可能就放弃查看这个商品了。而面向用户的功能聚合通常非常复杂,伴随着调用与调用之间的级联、多级级联等情况,业务开发同学往往会选择使用线程池这种简单的方式,将调用封装成任务并行的执行,缩短总体响应时间。另外,使用线程池也是有考量的,这种场景最重要的就是获取最大的响应速度去满足用户,所以应该不设置队列去缓冲并发任务,调高corePoolSize和maxPoolSize去尽可能创造多的线程快速执行任务。
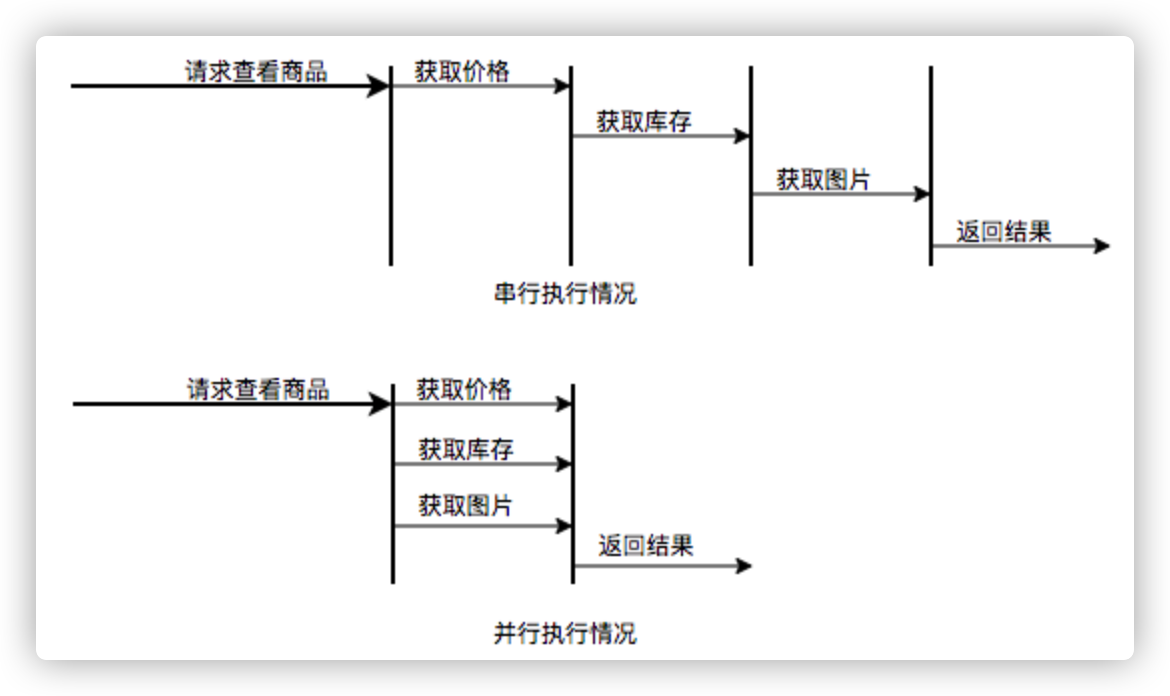
图12 并行执行任务提升任务响应速度
场景2:快速处理批量任务
描述:离线的大量计算任务,需要快速执行。比如说,统计某个报表,需要计算出全国各个门店中有哪些商品有某种属性,用于后续营销策略的分析,那么我们需要查询全国所有门店中的所有商品,并且记录具有某属性的商品,然后快速生成报表。
分析:这种场景需要执行大量的任务,我们也会希望任务执行的越快越好。这种情况下,也应该使用多线程策略,并行计算。但与响应速度优先的场景区别在于,这类场景任务量巨大,并不需要瞬时的完成,而是关注如何使用有限的资源,尽可能在单位时间内处理更多的任务,也就是吞吐量优先的问题。所以应该设置队列去缓冲并发任务,调整合适的corePoolSize去设置处理任务的线程数。在这里,设置的线程数过多可能还会引发线程上下文切换频繁的问题,也会降低处理任务的速度,降低吞吐量。
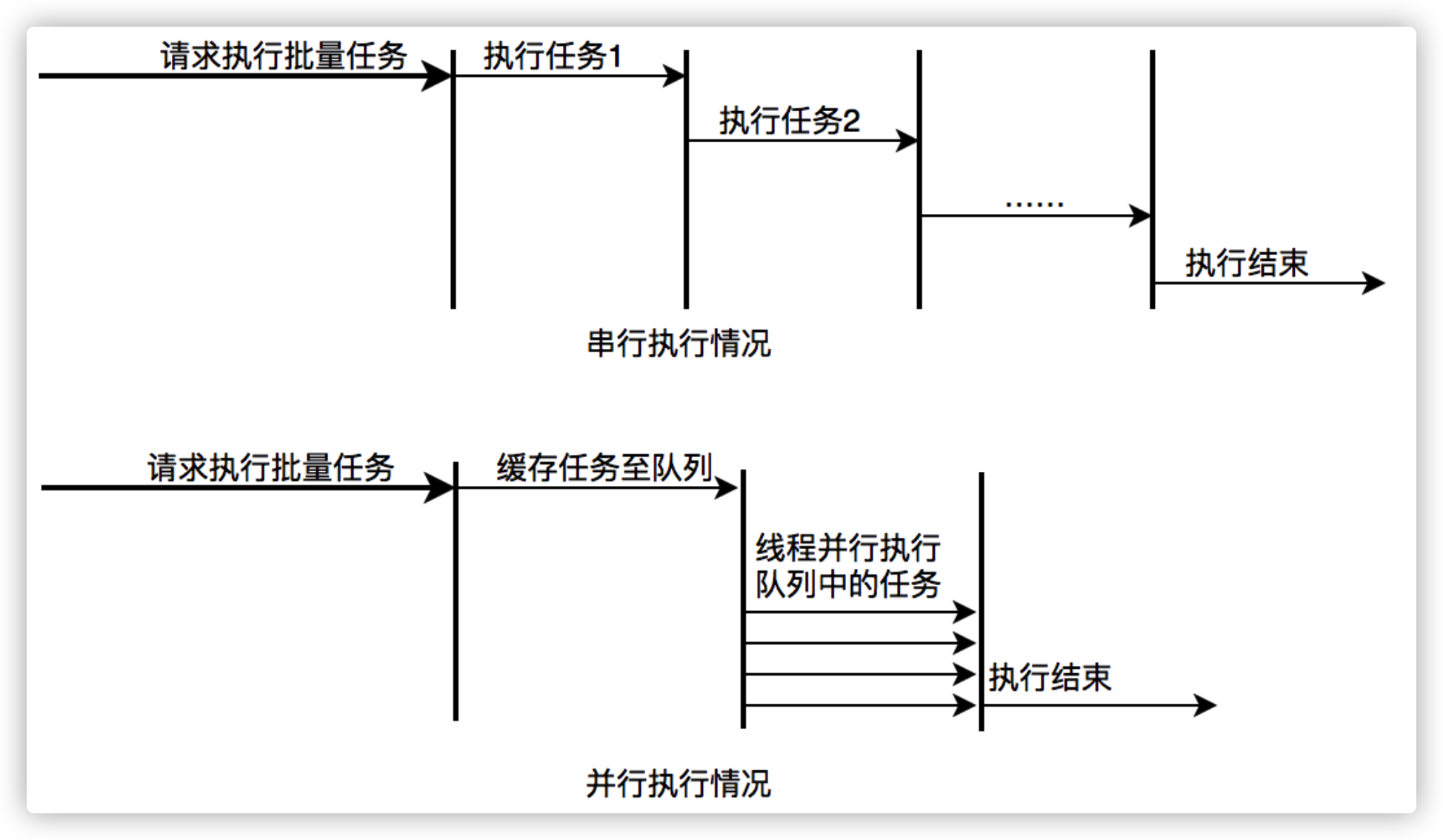
图13 并行执行任务提升批量任务执行速度
线程池使用面临的核心的问题在于:线程池的参数并不好配置。一方面线程池的运行机制不是很好理解,配置合理需要强依赖开发人员的个人经验和知识;另一方面,线程池执行的情况和任务类型相关性较大,IO密集型和CPU密集型的任务运行起来的情况差异非常大,这导致业界并没有一些成熟的经验策略帮助开发人员参考。
关于线程池配置不合理引发的故障,公司内部有较多记录,下面举一些例子:
Case1:2018年XX页面展示接口大量调用降级:
事故描述:XX页面展示接口产生大量调用降级,数量级在几十到上百。
事故原因:该服务展示接口内部逻辑使用线程池做并行计算,由于没有预估好调用的流量,导致最大核心数设置偏小,大量抛出RejectedExecutionException,触发接口降级条件,示意图如下:
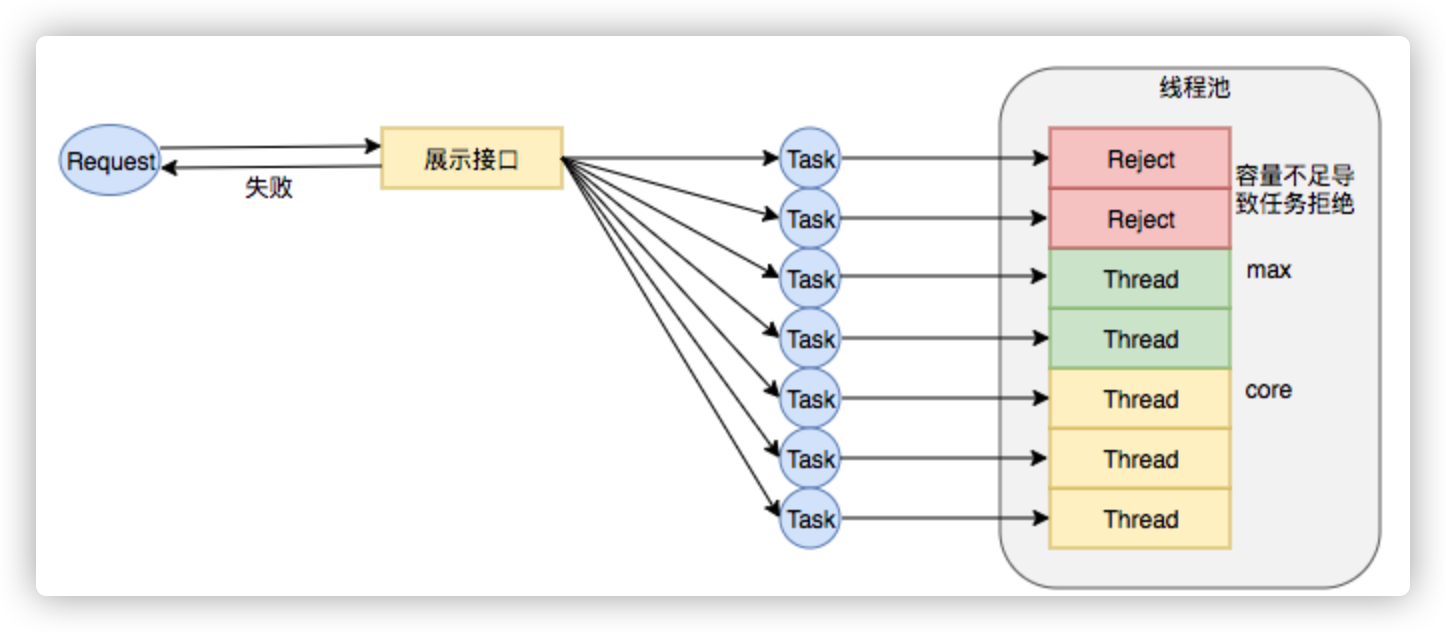
图14 线程数核心设置过小引发RejectExecutionException
Case2:2018年XX业务服务不可用S2级故障
事故描述:XX业务提供的服务执行时间过长,作为上游服务整体超时,大量下游服务调用失败。
事故原因:该服务处理请求内部逻辑使用线程池做资源隔离,由于队列设置过长,最大线程数设置失效,导致请求数量增加时,大量任务堆积在队列中,任务执行时间过长,最终导致下游服务的大量调用超时失败。示意图如下:
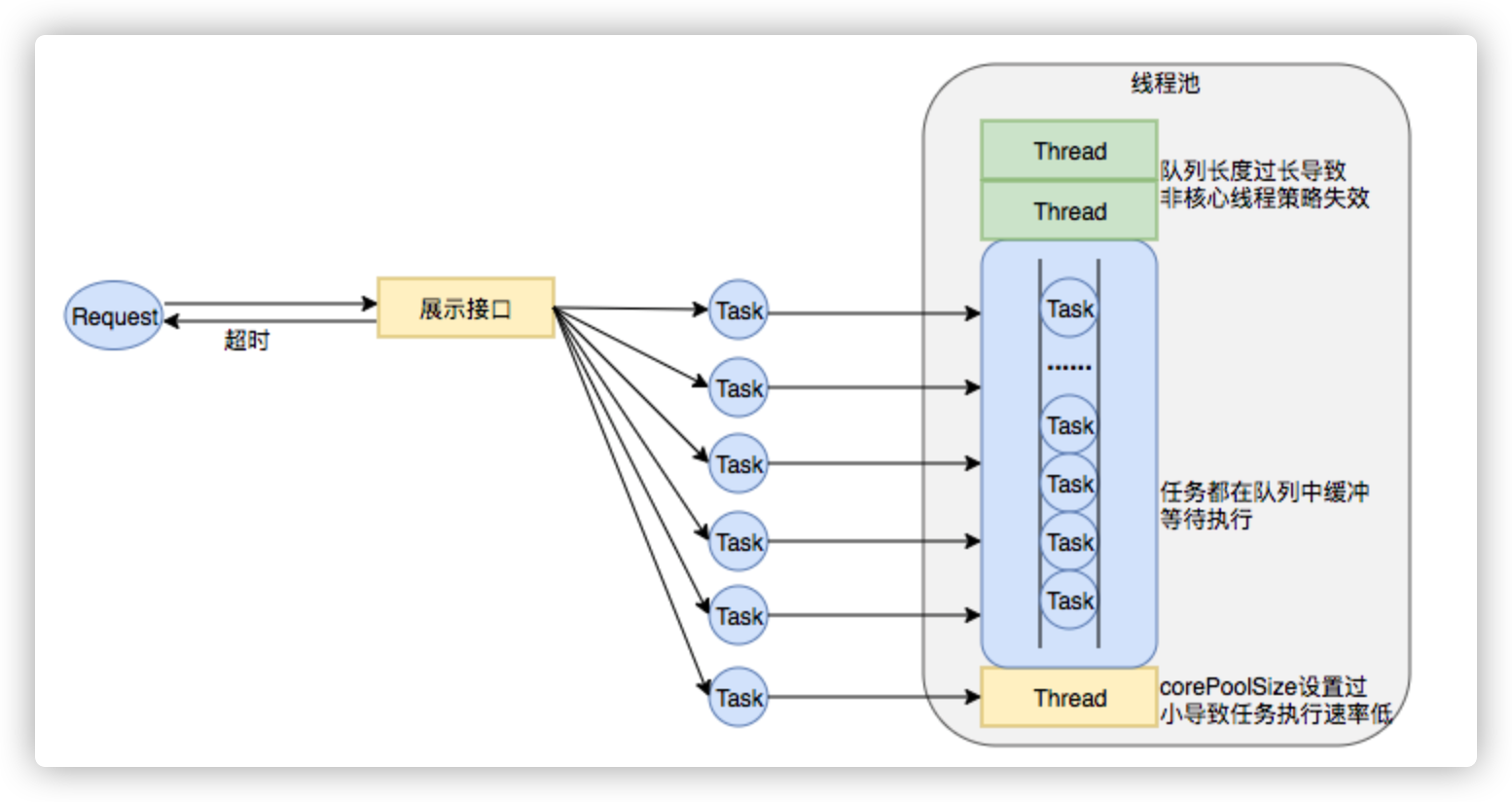
图15 线程池队列长度设置过长、corePoolSize设置过小导致任务执行速度低
业务中要使用线程池,而使用不当又会导致故障,那么我们怎样才能更好地使用线程池呢?针对这个问题,我们下面延展几个方向:
1. 能否不用线程池?
回到最初的问题,业务使用线程池是为了获取并发性,对于获取并发性,是否可以有什么其他的方案呢替代?我们尝试进行了一些其他方案的调研:
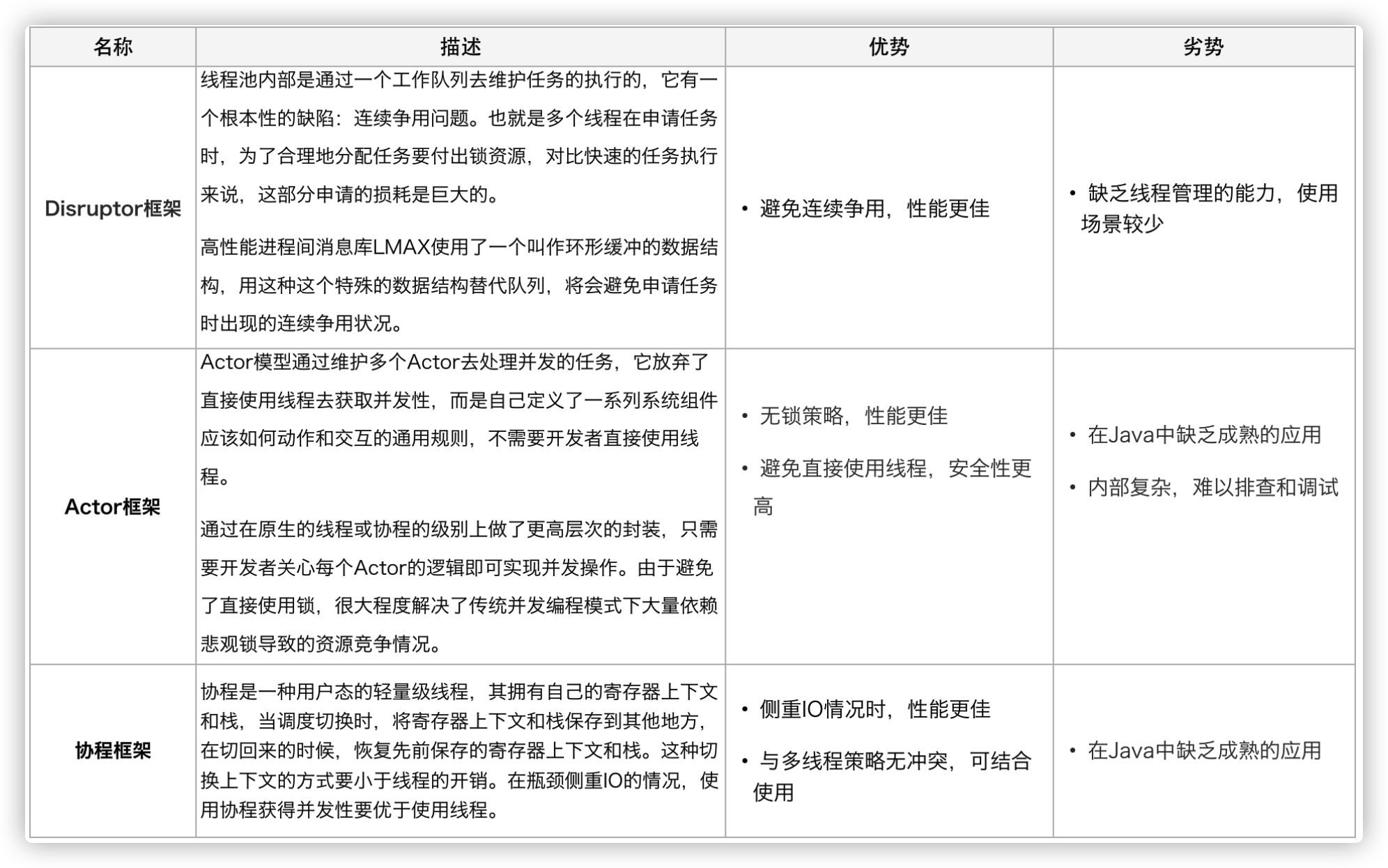
综合考虑,这些新的方案都能在某种情况下提升并行任务的性能,然而本次重点解决的问题是如何更简易、更安全地获得的并发性。另外,Actor模型的应用实际上甚少,只在Scala中使用广泛,协程框架在Java中维护的也不成熟。这三者现阶段都不是足够的易用,也并不能解决业务上现阶段的问题。
2. 追求参数设置合理性?
有没有一种计算公式,能够让开发同学很简易地计算出某种场景中的线程池应该是什么参数呢?
带着这样的疑问,我们调研了业界的一些线程池参数配置方案:

调研了以上业界方案后,我们并没有得出通用的线程池计算方式。并发任务的执行情况和任务类型相关,IO密集型和CPU密集型的任务运行起来的情况差异非常大,但这种占比是较难合理预估的,这导致很难有一个简单有效的通用公式帮我们直接计算出结果。
3. 线程池参数动态化?
尽管经过谨慎的评估,仍然不能够保证一次计算出来合适的参数,那么我们是否可以将修改线程池参数的成本降下来,这样至少可以发生故障的时候可以快速调整从而缩短故障恢复的时间呢?基于这个思考,我们是否可以将线程池的参数从代码中迁移到分布式配置中心上,实现线程池参数可动态配置和即时生效,线程池参数动态化前后的参数修改流程对比如下:
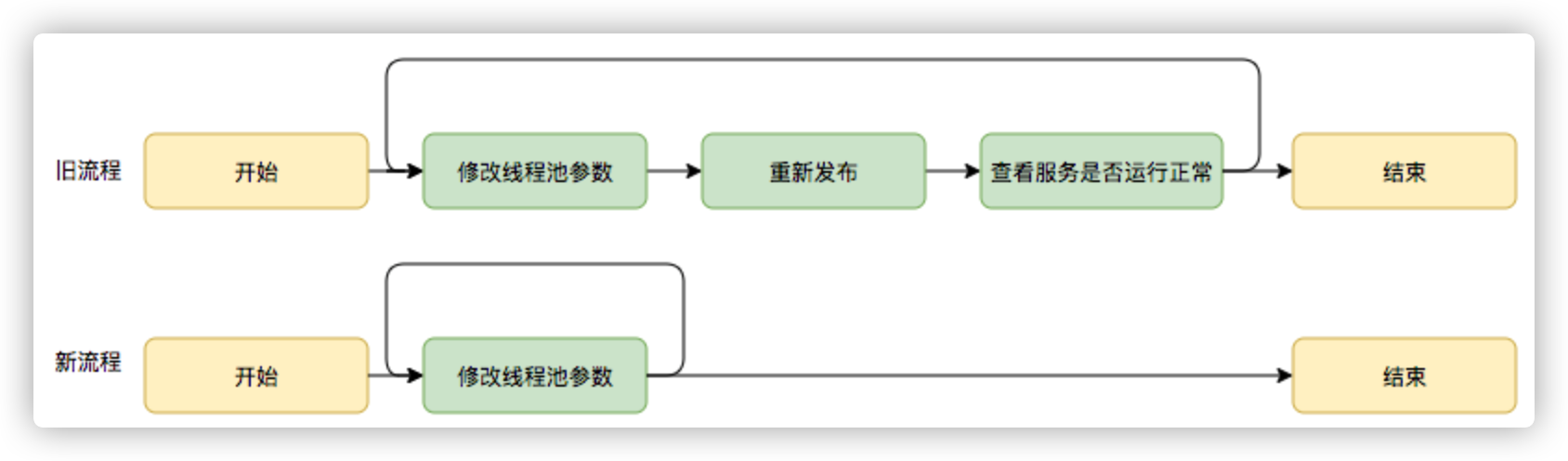
图16 动态修改线程池参数新旧流程对比
基于以上三个方向对比,我们可以看出参数动态化方向简单有效。
3.3.1 整体设计
动态化线程池的核心设计包括以下三个方面:
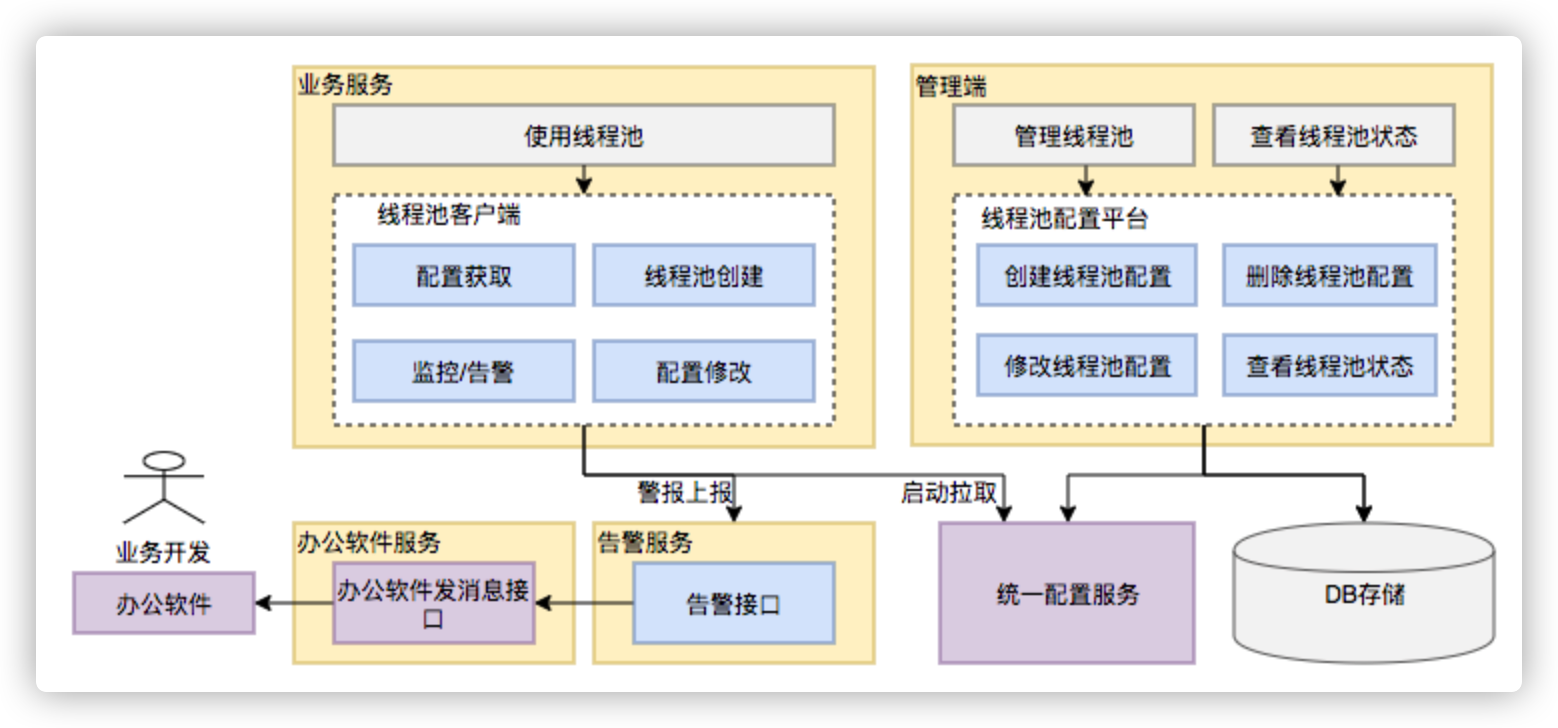
图17 动态化线程池整体设计
3.3.2 功能架构
动态化线程池提供如下功能:
动态调参:支持线程池参数动态调整、界面化操作;包括修改线程池核心大小、最大核心大小、队列长度等;参数修改后及时生效。 任务监控:支持应用粒度、线程池粒度、任务粒度的Transaction监控;可以看到线程池的任务执行情况、最大任务执行时间、平均任务执行时间、95/99线等。 负载告警:线程池队列任务积压到一定值的时候会通过大象(美团内部通讯工具)告知应用开发负责人;当线程池负载数达到一定阈值的时候会通过大象告知应用开发负责人。 操作监控:创建/修改和删除线程池都会通知到应用的开发负责人。 操作日志:可以查看线程池参数的修改记录,谁在什么时候修改了线程池参数、修改前的参数值是什么。 权限校验:只有应用开发负责人才能够修改应用的线程池参数。
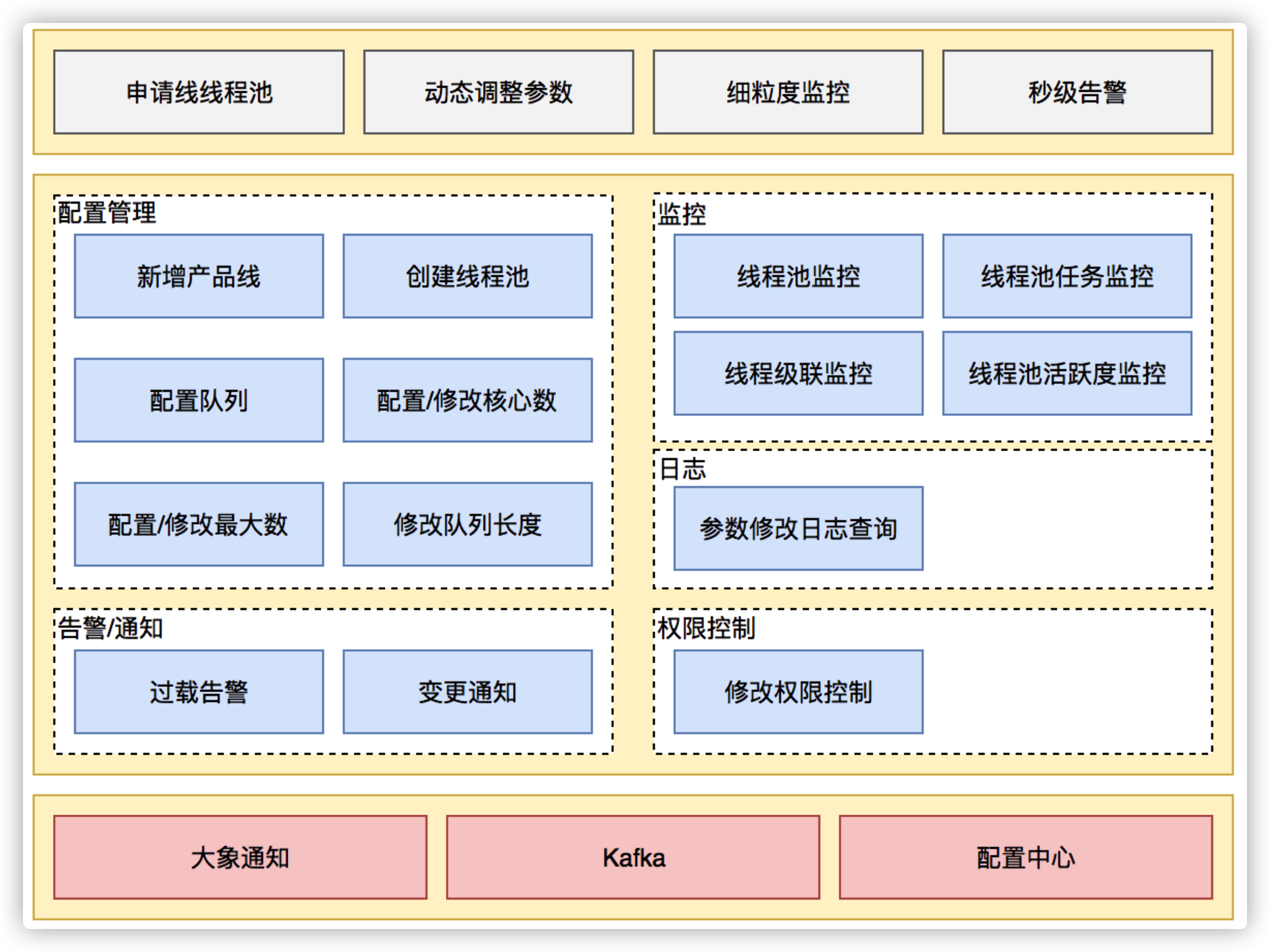
图18 动态化线程池功能架构
参数动态化
JDK原生线程池ThreadPoolExecutor提供了如下几个public的setter方法,如下图所示:

图19 JDK 线程池参数设置接口
JDK允许线程池使用方通过ThreadPoolExecutor的实例来动态设置线程池的核心策略,以setCorePoolSize为方法例,在运行期线程池使用方调用此方法设置corePoolSize之后,线程池会直接覆盖原来的corePoolSize值,并且基于当前值和原始值的比较结果采取不同的处理策略。对于当前值小于当前工作线程数的情况,说明有多余的worker线程,此时会向当前idle的worker线程发起中断请求以实现回收,多余的worker在下次idel的时候也会被回收;对于当前值大于原始值且当前队列中有待执行任务,则线程池会创建新的worker线程来执行队列任务,setCorePoolSize具体流程如下:
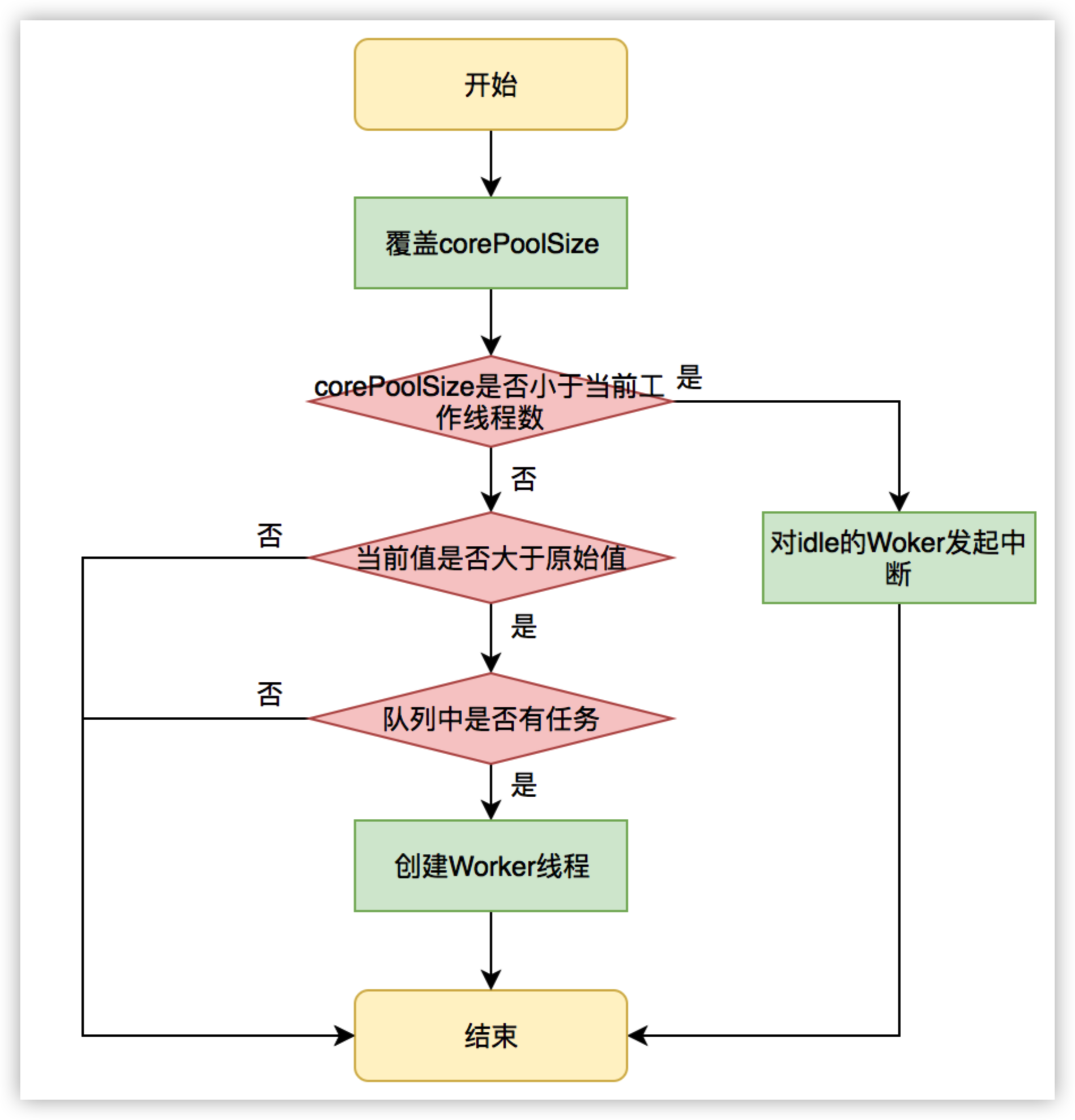
图20 setCorePoolSize方法执行流程
线程池内部会处理好当前状态做到平滑修改,其他几个方法限于篇幅,这里不一一介绍。重点是基于这几个public方法,我们只需要维护ThreadPoolExecutor的实例,并且在需要修改的时候拿到实例修改其参数即可。基于以上的思路,我们实现了线程池参数的动态化、线程池参数在管理平台可配置可修改,其效果图如下图所示:
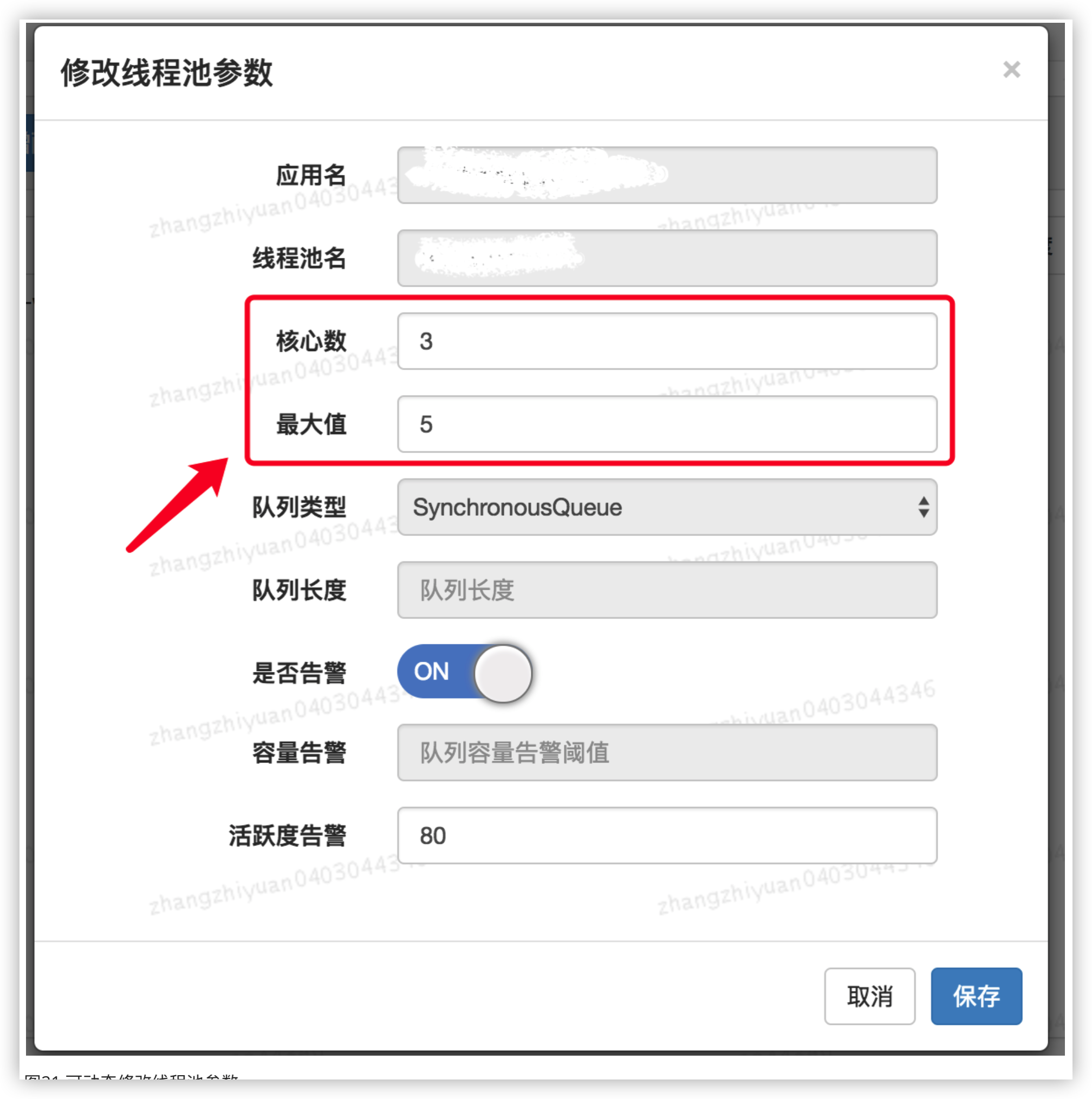
图21 可动态修改线程池参数
用户可以在管理平台上通过线程池的名字找到指定的线程池,然后对其参数进行修改,保存后会实时生效。目前支持的动态参数包括核心数、最大值、队列长度等。除此之外,在界面中,我们还能看到用户可以配置是否开启告警、队列等待任务告警阈值、活跃度告警等等。关于监控和告警,我们下面一节会对齐进行介绍。
线程池监控
除了参数动态化之外,为了更好地使用线程池,我们需要对线程池的运行状况有感知,比如当前线程池的负载是怎么样的?分配的资源够不够用?任务的执行情况是怎么样的?是长任务还是短任务?基于对这些问题的思考,动态化线程池提供了多个维度的监控和告警能力,包括:线程池活跃度、任务的执行Transaction(频率、耗时)、Reject异常、线程池内部统计信息等等,既能帮助用户从多个维度分析线程池的使用情况,又能在出现问题第一时间通知到用户,从而避免故障或加速故障恢复。
线程池负载关注的核心问题是:基于当前线程池参数分配的资源够不够。对于这个问题,我们可以从事前和事中两个角度来看。事前,线程池定义了“活跃度”这个概念,来让用户在发生Reject异常之前能够感知线程池负载问题,线程池活跃度计算公式为:线程池活跃度 = activeCount/maximumPoolSize。这个公式代表当活跃线程数趋向于maximumPoolSize的时候,代表线程负载趋高。事中,也可以从两方面来看线程池的过载判定条件,一个是发生了Reject异常,一个是队列中有等待任务(支持定制阈值)。以上两种情况发生了都会触发告警,告警信息会通过大象推送给服务所关联的负责人。
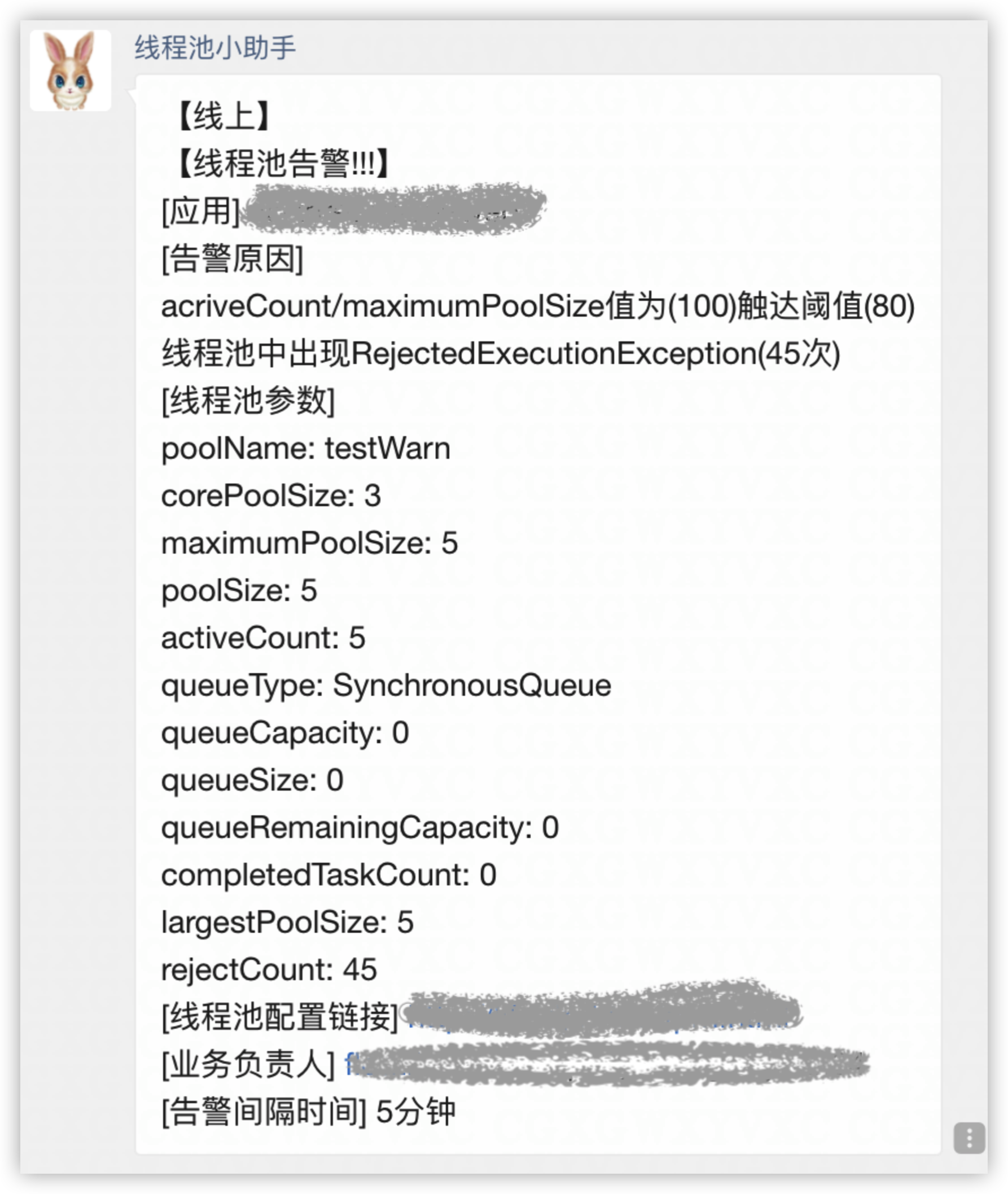
图22 大象告警通知
在传统的线程池应用场景中,线程池中的任务执行情况对于用户来说是透明的。比如在一个具体的业务场景中,业务开发申请了一个线程池同时用于执行两种任务,一个是发消息任务、一个是发短信任务,这两类任务实际执行的频率和时长对于用户来说没有一个直观的感受,很可能这两类任务不适合共享一个线程池,但是由于用户无法感知,因此也无从优化。动态化线程池内部实现了任务级别的埋点,且允许为不同的业务任务指定具有业务含义的名称,线程池内部基于这个名称做Transaction打点,基于这个功能,用户可以看到线程池内部任务级别的执行情况,且区分业务,任务监控示意图如下图所示:

图23 线程池任务执行监控
用户基于JDK原生线程池ThreadPoolExecutor提供的几个public的getter方法,可以读取到当前线程池的运行状态以及参数,如下图所示:
图24 线程池实时运行情况
动态化线程池基于这几个接口封装了运行时状态实时查看的功能,用户基于这个功能可以了解线程池的实时状态,比如当前有多少个工作线程,执行了多少个任务,队列中等待的任务数等等。效果如下图所示:
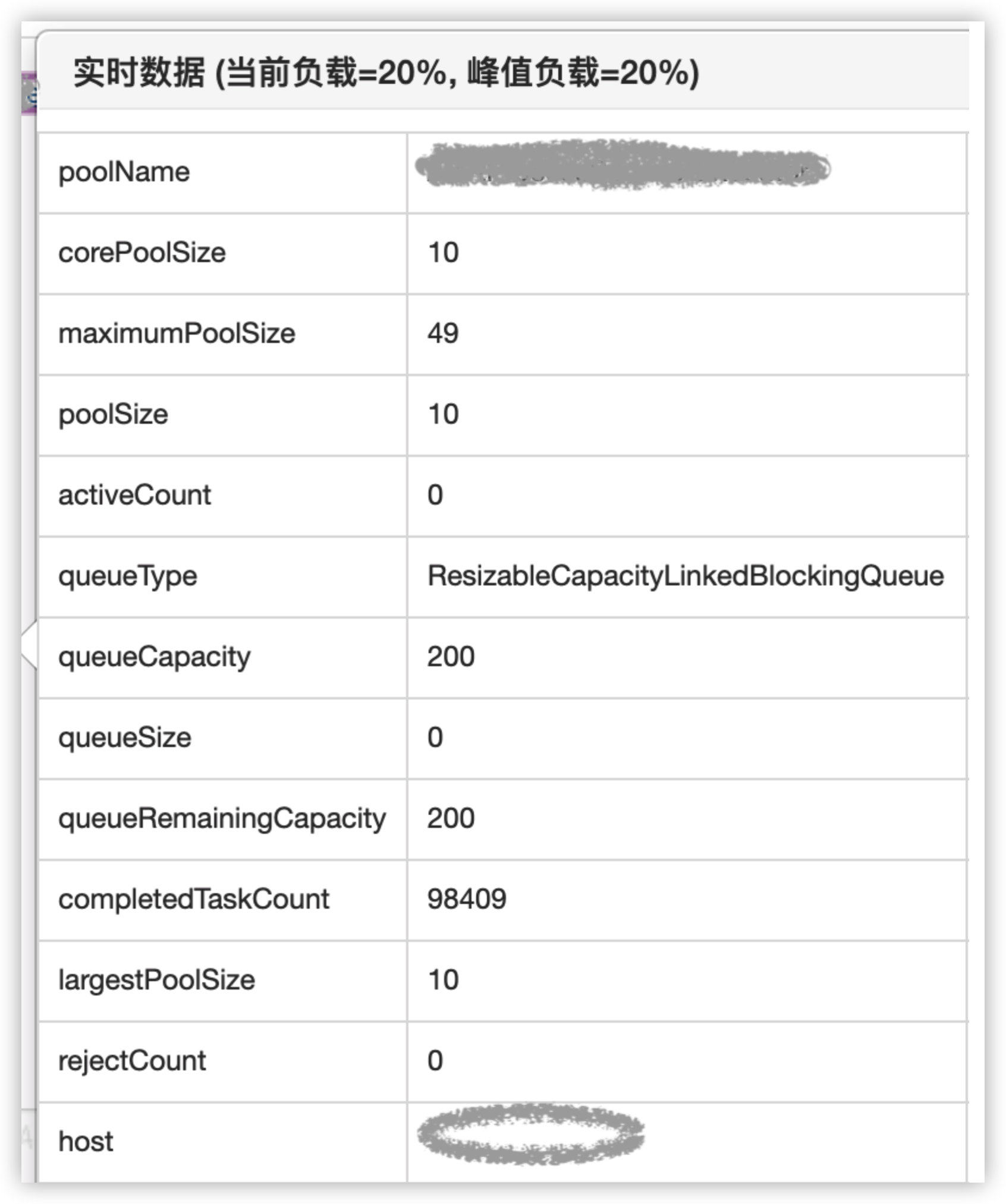
图25 线程池实时运行情况
面对业务中使用线程池遇到的实际问题,我们曾回到支持并发性问题本身来思考有没有取代线程池的方案,也曾尝试着去追求线程池参数设置的合理性,但面对业界方案具体落地的复杂性、可维护性以及真实运行环境的不确定性,我们在前两个方向上可谓“举步维艰”。最终,我们回到线程池参数动态化方向上探索,得出一个且可以解决业务问题的方案,虽然本质上还是没有逃离使用线程池的范畴,但是在成本和收益之间,算是取得了一个很好的平衡。成本在于实现动态化以及监控成本不高,收益在于:在不颠覆原有线程池使用方式的基础之上,从降低线程池参数修改的成本以及多维度监控这两个方面降低了故障发生的概率。希望本文提供的动态化线程池思路能对大家有帮助。