word技巧
word技巧
正则替换
- 替换汉字之间的空格
1 | 查找:([!^1-^127]) ([!^1-^127]) |
- 删除英文字母和非英文字母之间的半角空格
1 | 【查找】:([A-Za-z])(^32@)([!A-Za-z]) |
- 删除非英文字母和英文字母之间的半角空格
1 | 【查找】:([!A-Za-z])(^32@)([A-Za-z]) |
- 删除中文字符(含符号)之间的单个半角空格
1 | 【查找】: |
删除非数字与数字之间的单个半角空格
1
2
3
4
5【查找】:([!0-9])(^32@)([0-9])
【替换】:\1\3
注:使用通配符删除数字与非数字之间的单个半角空格
1
2
3【查找】:([0-9])(^32@)([!0-9])
【替换】:\1\3删除多余空白行|段首空格|段尾空格
1
2
3
4
51、删除段首空格:^p^p,替换为:^p,全部替换;
2、删除段首空格:(^13)(^32@),替换为:\1,全部替换;
3、删除段尾空格:(^32@)(^13),替换为:\2,全部替换;
注:使用通配符匹配中文
- 方法一
在word中匹配中文可以用[一-龥],其中龥(读yu),要用微软拼音才能输入,用紫光等其它拼音找不到这个字。如果用“颌”匹配不完全的。捕获用英文括号括起来,引用从左到右依次用\1, \2, …… 以此类推
word中排除字符和php不同,而是使用英文感叹号!,例如[!一-龥]匹配所有非中文字符。
word匹配多个字符也和php不同,使用的是@,例如[一-龥]@匹配0个或多个连续中文字符。
- 方法二
匹配中文字符的正则表达式“[\u4e00-\u9fa5]”与
匹配双字节字符(包括汉字在内) “ [^\x00-\xff]”,该如何在MS Word中(变通)使用?
“实践是检验真理的唯一标准”的这句话呢? 为啥不能动动手呢?!
刚才试了一下,完全可以用,只要稍稍改动一下即可.
[\u4e00-\u9fa5]与[^\x00-\xff] 分别改为 [!\u4e00-\u9fa5]与[!\x00-\xff].
另有说法:用这个就可以了[!^1-^127]
WORD中的字符串限定
“<”表示字符串的开头,“>”表示字符串的结尾,“<祖国>”实际上表示对查找的内容进行严格的限制,或者也可以设置为“<祖国”,但“祖国>”则不允许使用。
通配符
任意单个字符:“?”可以代表任意单个字符,输入几个“?”就代表几个未知字符。如:输入“? 国”就可以找到诸如“中国”、“美国”、“德国”等字符;输入“???国”可以找到“孟加拉国”等字符。
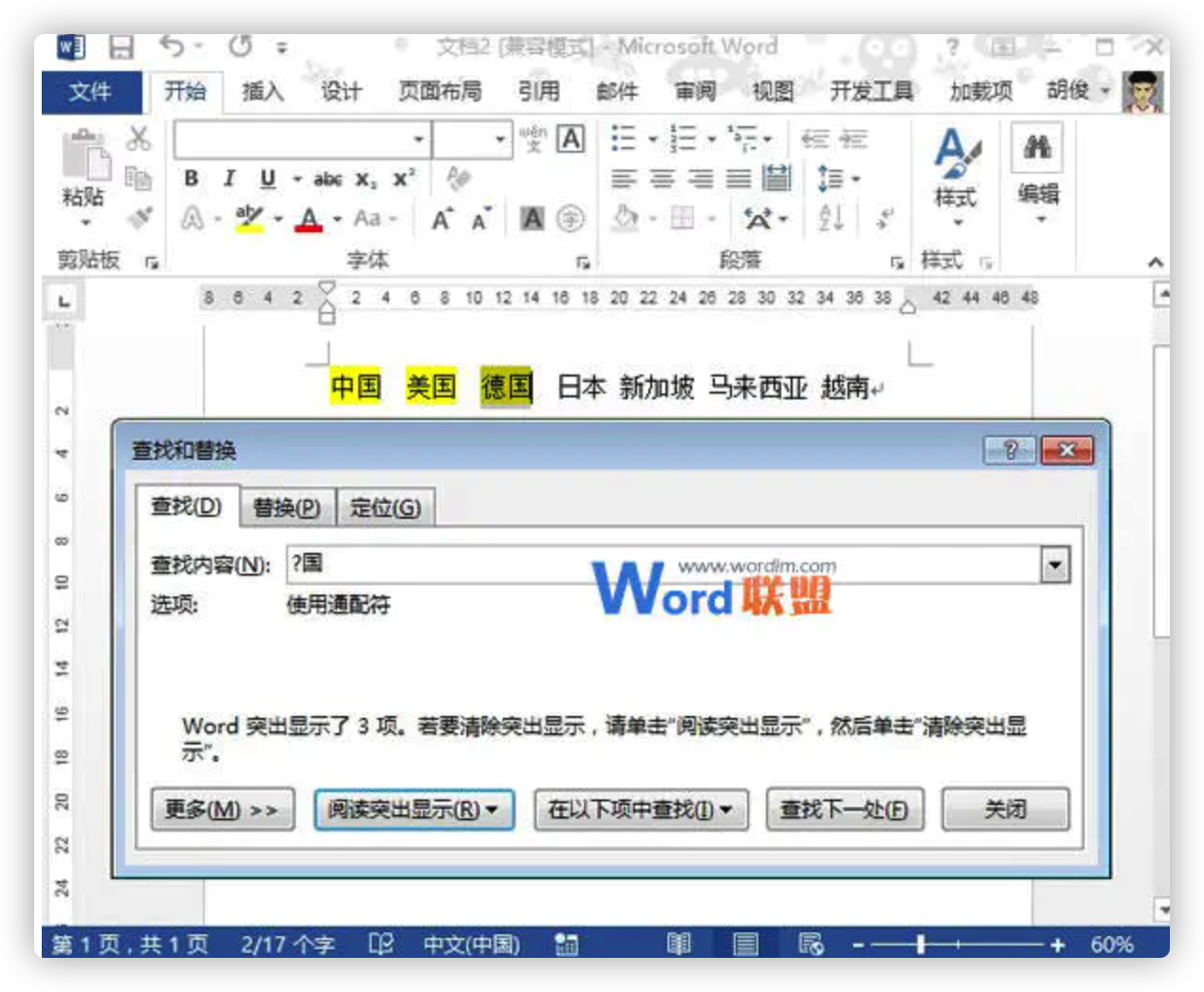
任意多个字符: “*”可以代表任意多个字符。如:输入“*国”就可以找到“中国”、“美国”、 “孟加拉国”等字符。
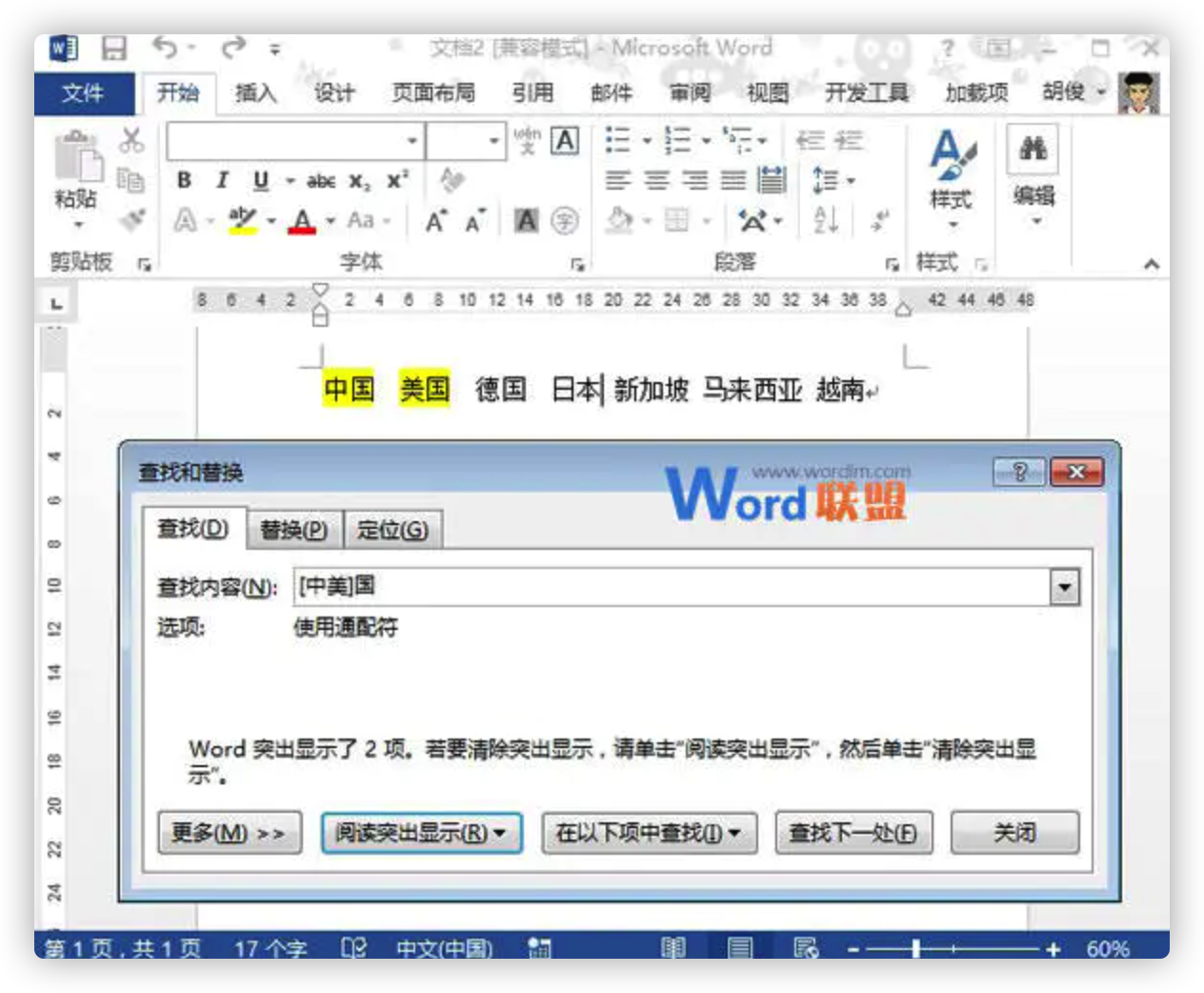
指定字符之一: “[]”框内的字符可以是指定要查找的字符之一,如:输入“[中美]国”就可以找到“中国”、“美国”。 又如:输入“th[iu]g”,就可查找到“thigh”和“thug”。 输入“[学硕博]士”,查找到的将会是学士、士、硕士、博士。
指定范围内的任意单个字符: “[x-x]”可以指定某一范围内的任意单个字符,如:输入“[a-c]mend”的话,Word查找工具就可以找到“amend”、“bmend”、“cmend”等字符内容。
排除指定范、排除指定范围内的任意单个字符: “[!x-x]”可以用来排除指定范围内的任意单个字符,如:输入“[!a-c]”的话,word程序就可以找到“good”、“see”、“these”等目标字符,而所有包含字符a、b、c之类的内容都不会在查找结果中出现。
指定前一字符的个数:“{n}”可以用来指定要查找的字符中包含前一字符的个数,如:输入“cho{1} se”就是说包含1个前一字符“o”,可以找到“chose”,输入“cho{2}se”就是说包含2个前一字符“o”,可以找到, “choose”。
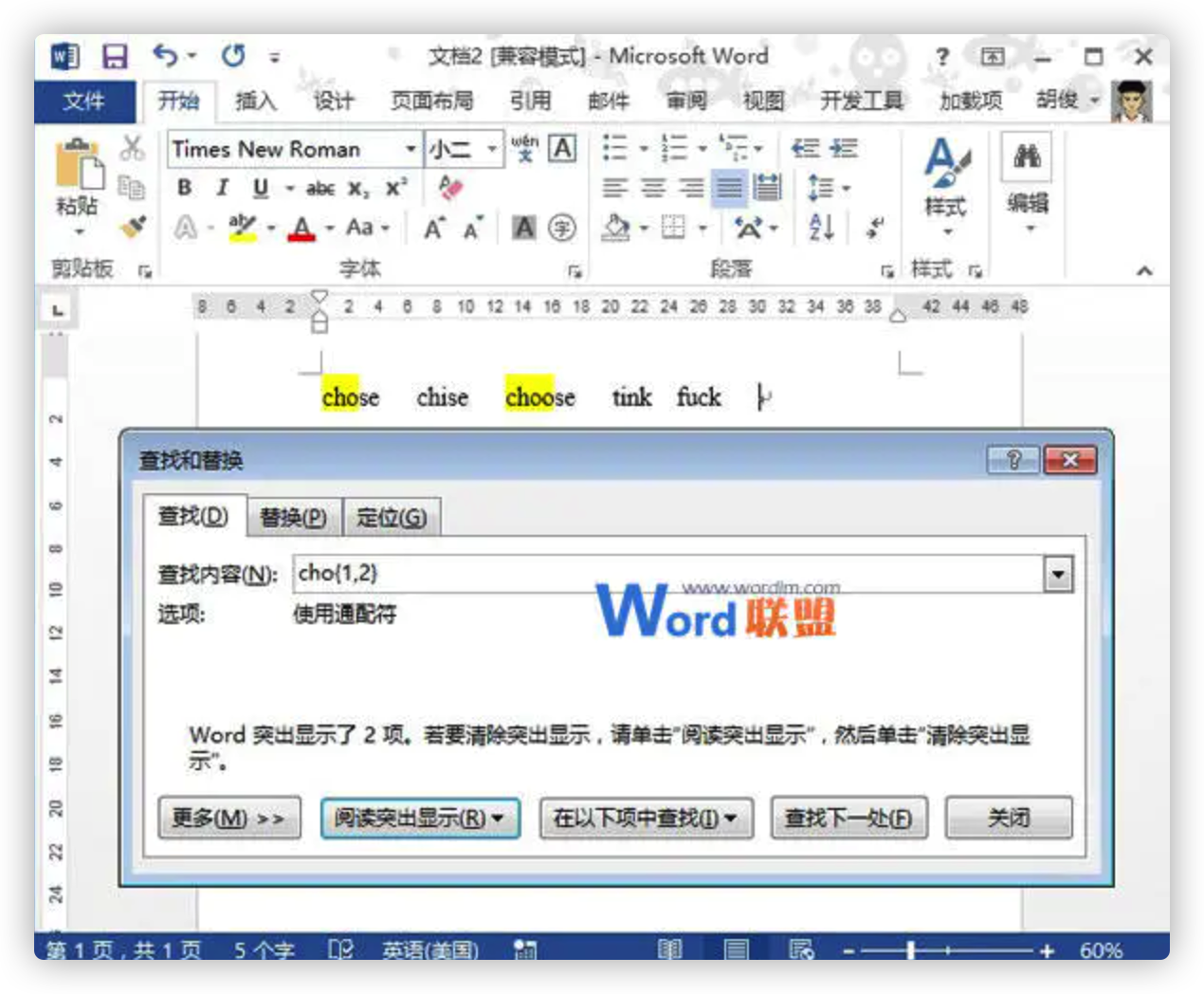
指定前一字符、指定前一字符数范围:“{x,x}”可以用指定要查找字符中前一字符数范围,如:输入“cho{1,2}”,则说明包含前一字符“o”数目范围是1-2个,则可以找到“chose”、“choose”。
一个以上的前一字符: “@”可以用来指定要查找字符中包含一个以上的前一字符,如:输入“cho@se”,就可以找到, “chose”、“choose”等字符。
指定起始字符串:“<”可以用来指定要查找字符中的起始字符串,如:输入“<ag”,就说明要查找的字符的起始字符为“ag”,可以找到 “ago”、“agree”、“again”等字符。输入“<te”的话,可能查到“ten”、“tea”等。
指定结尾字符串: “>”可以用来指定要查找字符中的结尾字符串,如:输入“er>”,就说明要查找的字符的结尾字符为“er”,可以找到 “ver”、“her”、“lover”等等。输入“en>”, 就说明要查找到以“en”结尾的所有目标对象,可能找到“ten”、“pen”、“men”;输入“up>”,就说明要查找到以“up”结尾的所有目标对象,例如会找到“setup”、“cup”等等。
经典案例
相关的正则表达式
^&:用于替换框,表示引用查找框的全部内容;
^11:手动换行符,等于通配符模式下的^l;
^13:换行符,等于通配符模式下、只能在替换框使用的^p;
^32:半角空格;
^?:任意单字符,等于通配符模式下的?(比较:*表示任意字符);
^#:任意单数字,等于通配符模式下的[0-9];
^$:任意单字母,等于通配符模式下的[a-zA-Z];
^w:换行符以外的所有空白区域;
^c:用于替换框,表示剪贴板上的内容;
[字符1字符2]:字符1或字符2;
[m-n]:序列m-n中的任意1个字符;
[!m-n]:序列m-n之外的任意1个字符;
[!字符1字符2]:字符1字符2之外的任意1个字符;
[^1-^127]:表示任一西文字符;
[!^1-^127]:表示任一中文字符;
{n}:n个前1字符或前1表达式;
{n,}:n个以上前1字符或表达式({1,}等于@,表示1个以上前1字符或表达式);
{n,m}:n到m个前一字符或前一表达式;
\通配符:引用通配符本身;
( ):表达式引导符,用于查找框,是为了在替换框中,用\n的形式来引用;
\n:与( )呼应,在替换框中使用,表示引用查找框中第n个表达式的内容;
<:句首引导符;
>:句尾引导符;
@:表示一个以上字符;
将查找对象设置格式:定位到替换框/设置格式/替换;
运用实例
准备:粘贴网页内容时,最好是选择性粘贴-无格式文本,以清除各种混乱格式。
1.清除空行:不选使用通配符;查找^p^p,替换为^p
2.清除空白区域:不选使用通配符;查找^w,替换为空值
3.删除特定行:使用通配符;查找^13特定内容^13,替换为^p
4.将数字中的句号替换为小数点:查找([0-9]{1,})。([0-9]{1,}),替换为\1.\2([0-9]{1,}表示1位及以上数字,\1和\2引用查找中的第1、2对括号内的表达式)
5.清除多余的换行符:
语法——勾选使用通配符。查找:([..,,、 ])^13@,替换为:\1
说明——[..,,、 ]为非句尾分隔符,\1引用第1对括号内的表达式[..,,、 ]。
6.清除重复内容:
准备——查找^p,全部替换为^p^p;全选文档或Ctrl+Home定位到文首。
语法——勾选使用通配符:
查找:(<[!^13]^13)()\1,替换为:\1\2(其中[!^13]*也可用[!^13]@或 [!^13]{1,} 来代替) ;
或:查找(^13[!^13]@^13){2,},替换为\1;
或:查找(*^13){2,},替换为\1;
7.将不在行首的选项另起一行:
语法——勾选使用通配符。查找:!^13[..、 ];替换为:^p\1.
8.将不在行首的题号另起一行:
语法——勾选使用通配符。查找:!^13[..、 ];替换为:^p\1.
9.将不连续题号重新编号:
在Word中,Ctrl+F9>>输入与代码SEQ A>>选中域>>剪切
>>Ctrl+H>>查找[0-9]@[. 、:.],替换为^c>>F9更新域
word页码
分页符作用:重置开始页码
插入->页码->判断是否链接到上一页
word单页横向
页面开始位置插入2个分页符,再设置该页横向
插入黑色实心方块
- 打开需要操作的WORD文档,选中相关小方框,点击插入选项卡的“符号”,并选择“其他符号”。
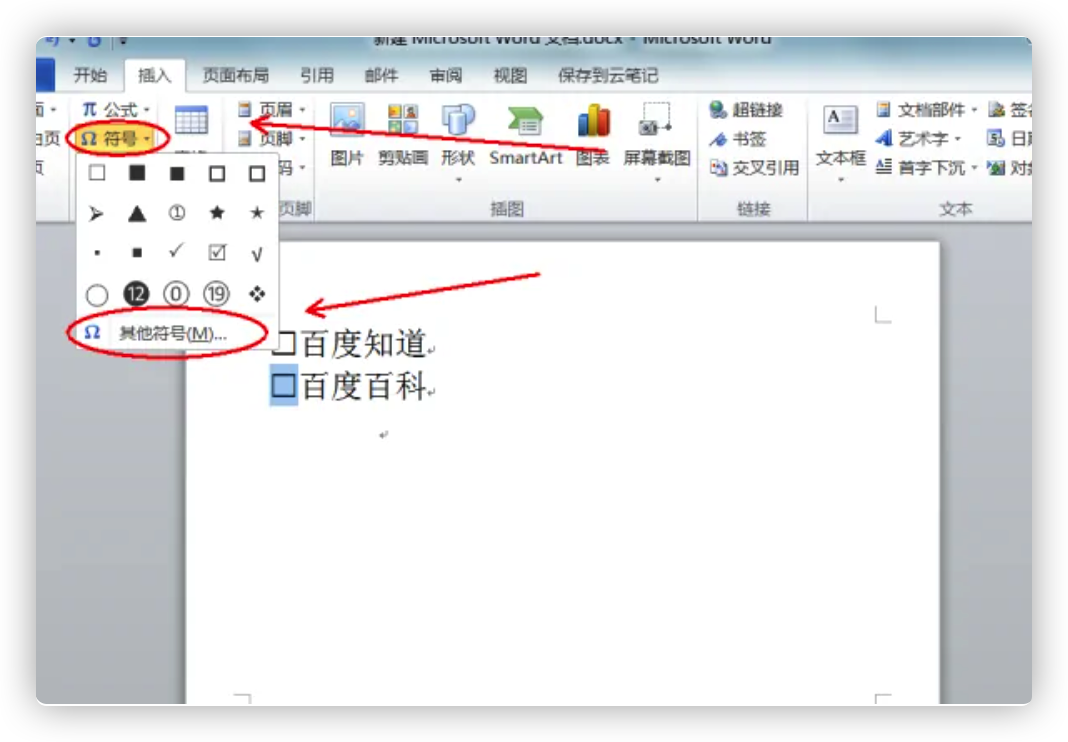
- 在Wingdings2中找到并点击选择全黑的小方块,然后点击插入即可。
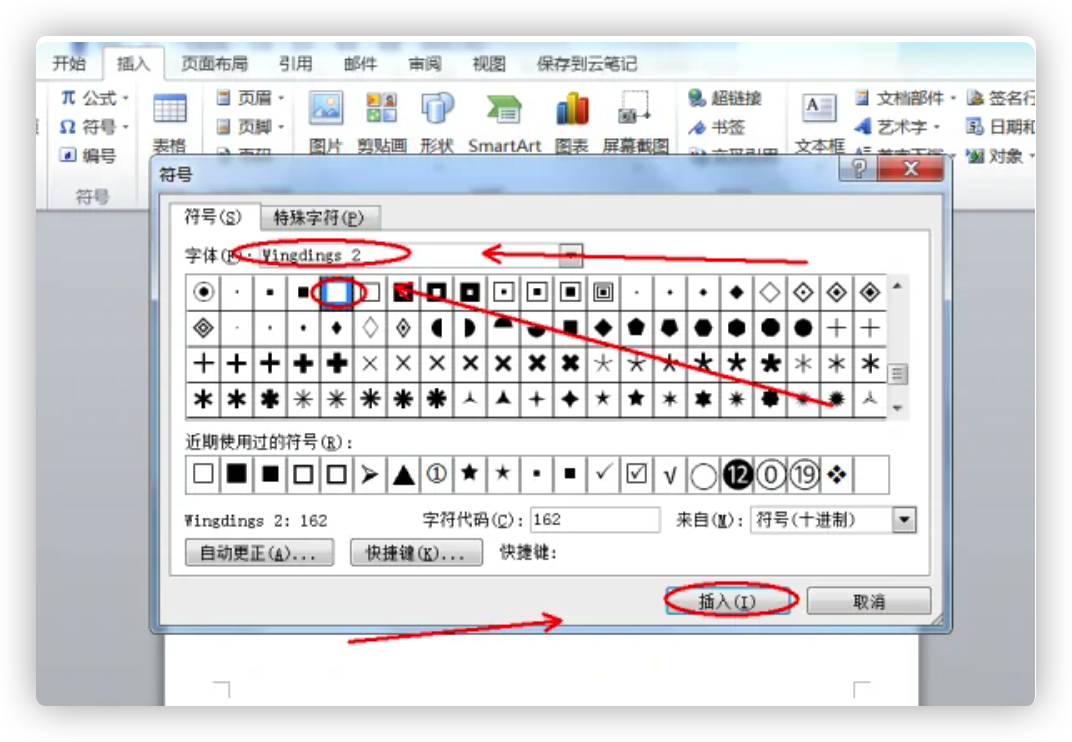
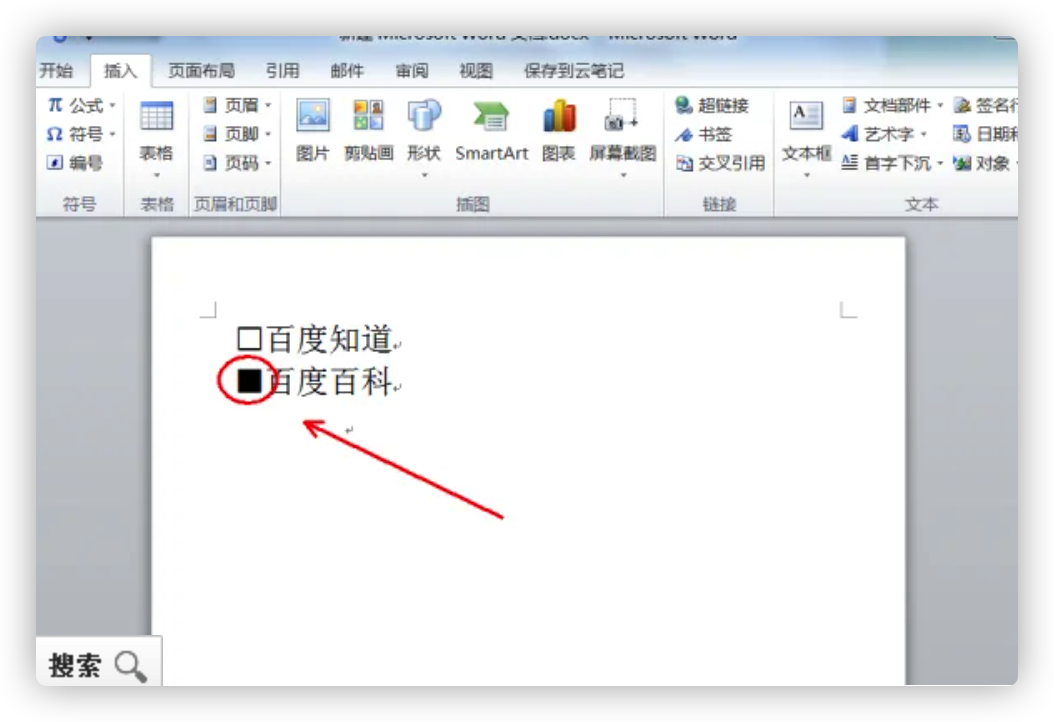
- 返回主文档,发现WORD中把小空格方框填黑操作完成。
批量修改图片大小
- 方法一
打开VBA编辑器(也可直接按【Alt+F11】快捷键),新建模块,然后将下面的代码复制粘贴到窗口中。
1 | Sub FormatPics() |
然后保存宏,关闭窗口。再运行宏即可批量调整图片大小。
- 方法二
F4(mac版CMD+Y),重复操作,图片数量不多的时候,批量修改
- 方法三
doc版本才能用,设置选择“选择多个对象”,并且需要将图片都改成“非嵌入”的图片。(不实用)
批量修改图片居中
1 | 查找替换窗口,查找框,输入:^g,替换框,格式:段落选择为居中(也可直接替换为”图片内容“样式) |
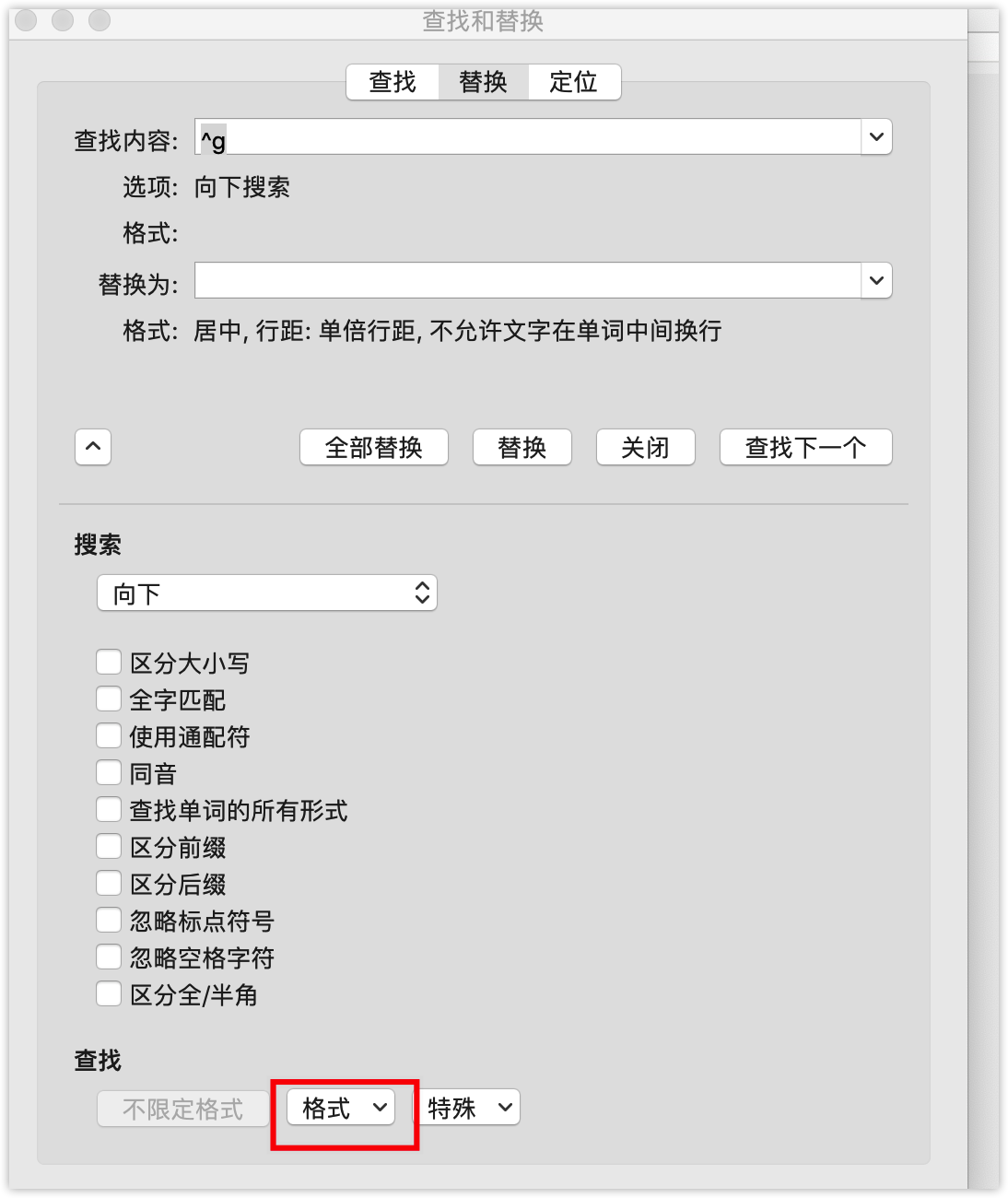
批量图片后加回车
1 | 查找替换窗口,查找框,输入:^g,替换框,输入:^&^p |
批量图片形状悬浮转嵌入
添加宏
1 | Sub 形状悬浮转嵌入() |
批量改英文数字为times new roman
- 选择 编辑→替换 界面。在“查找内容”文本框中输入”[0-9a-zA-Z]”,表示查找所有数字及大小写字母。选择 高级→使用通配符,表示输入的查找内容为通配符,而不是普通文本。
- 选中“替换为”文本框。选择 高级→格式→字体→西文字体,修改为 Times New Roman。