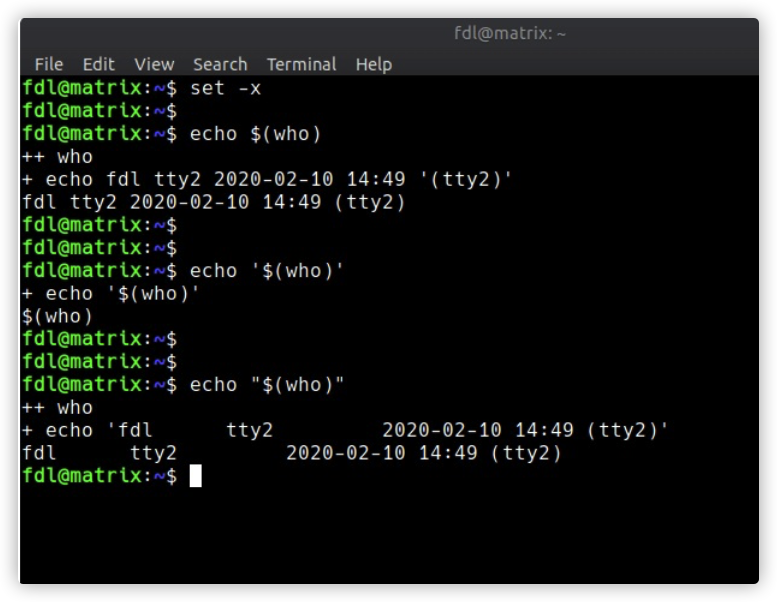
规则
abcdefghijklmnopqurtuvwxyz
ABCDEFGHIJKLMNOPQRSTUVWXYZa
abced
abd
A[A-Z]{24}Z
abbabbbc
abbc
abc
ac
ab{5}c
ab((ce)?d)?
10^6ml
10^9ML
10E9 ML
10[^E][369] ?(ml|ML)
ad
1234567890
[^\s]
Ha HaHa
.转义
[abc]
[^abc]
[a-z]
[^a-z]
[a-zA-Z]
.
\s\S space
\w\W word
\d\D digit
(a|b)
a? 0-1次
a* 0-任意次
a+ 1-任意次
a{3} 3次
a{3,6} 三到六次
a{,6} 至多6次
a{3,} 至少三次
(a{3}|a{6}) 3次或6次
^ 开头
$ 结尾
MetaCharacters (Need to be escaped):
.[{()^$|?*+
coreyms.com
[-a-zA-Z0-9./]+.[a-zA-Z]+/?
\d{3}[.-]\d{3}[.-]\d{4}
192.168.0.1
255.255.255.255
[1-9]?\d|1\d{2}|2([0-4]\d|5[0-5])
(([1-9]?\d|1\d{2}|2([0-4]\d|5[0-5])).){3}([1-9]?\d|1\d{2}|2([0-4]\d|5[0-5])))
321-555-4321
123.555.1234
Mr. Schafer
Mr Smith
Ms Davis
Mrs. Robinson
Mr. T
Mr. t
M(s|r|rs).? [A-Z][a-z]*
https://deerchao.net/tutorials/regex/regex.htm
https://regex101.com/
https://www.regular-expressions.info/
练习
Dave Martin
615-555-7164
173 Main St., Springfield RI 55924
davemartin@bogusemail.com
Charles Harris
800-555-5669
969 High St., Atlantis VA 34075
charlesharris@bogusemail.com
Eric Williams
560-555-5153
806 1st St., Faketown AK 86847
laurawilliams@bogusemail.com
Corey Jefferson
900-555-9340
826 Elm St., Epicburg NE 10671
coreyjefferson@bogusemail.com
Jennifer Martin-White
714-555-7405
212 Cedar St., Sunnydale CT 74983
jenniferwhite@bogusemail.com
Erick Davis
800-555-6771
519 Washington St., Olympus TN 32425
tomdavis@bogusemail.com
Neil Patterson
783-555-4799
625 Oak St., Dawnstar IL 61914
neilpatterson@bogusemail.com
Laura Jefferson
516-555-4615
890 Main St., Pythonville LA 29947
laurajefferson@bogusemail.com
Maria Johnson
127-555-1867
884 High St., Braavos ME 43597
mariajohnson@bogusemail.com
Michael Arnold
608-555-4938
249 Elm St., Quahog OR 90938
michaelarnold@bogusemail.com
Michael Smith
568-555-6051
619 Park St., Winterfell VA 99000
michaelsmith@bogusemail.com
Erik Stuart
292-555-1875
220 Cedar St., Lakeview NY 87282
robertstuart@bogusemail.com
Laura Martin
900-555-3205
391 High St., Smalltown WY 28362
lauramartin@bogusemail.com
Barbara Martin
614-555-1166
121 Hill St., Braavos UT 92474
barbaramartin@bogusemail.com
Linda Jackson
530-555-2676
433 Elm St., Westworld TX 61967
lindajackson@bogusemail.com
Eric Miller
470-555-2750
838 Main St., Balmora MT 56526
stevemiller@bogusemail.com
Dave Arnold
800-555-6089
732 High St., Valyria KY 97152
davearnold@bogusemail.com
Jennifer Jacobs
880-555-8319
217 High St., Old-town IA 82767
jenniferjacobs@bogusemail.com
Neil Wilson
777-555-8378
191 Main St., Mordor IL 72160
neilwilson@bogusemail.com
Kurt Jackson
998-555-7385
607 Washington St., Blackwater NH 97183
kurtjackson@bogusemail.com
Mary Jacobs
800-555-7100
478 Oak St., Bedrock IA 58176
maryjacobs@bogusemail.com
Michael White
903-555-8277
906 Elm St., Mordor TX 89212
michaelwhite@bogusemail.com
Jennifer Jenkins
196-555-5674
949 Main St., Smalltown SC 96962
jenniferjenkins@bogusemail.com
Sam Wright
900-555-5118
835 Pearl St., Smalltown ND 77737
samwright@bogusemail.com
John Davis
905-555-1630
451 Lake St., Bedrock GA 34615
johndavis@bogusemail.com
Eric Davis
203-555-3475
419 Lake St., Balmora OR 30826
neildavis@bogusemail.com
Laura Jackson
884-555-8444
443 Maple St., Quahog MS 29348
laurajackson@bogusemail.com
John Williams
904-555-8559
756 Hill St., Valyria KY 94854
johnwilliams@bogusemail.com
Michael Martin
889-555-7393
216 High St., Olympus NV 21888
michaelmartin@bogusemail.com
Maggie Brown
195-555-2405
806 Lake St., Lakeview MD 59348
maggiebrown@bogusemail.com
Erik Wilson
321-555-9053
354 Hill St., Mordor FL 74122
kurtwilson@bogusemail.com
Elizabeth Arnold
133-555-1711
805 Maple St., Winterfell NV 99431
elizabetharnold@bogusemail.com
Jane Martin
900-555-5428
418 Park St., Metropolis ID 16576
janemartin@bogusemail.com
Travis Johnson
760-555-7147
749 Washington St., Braavos SD 25668
travisjohnson@bogusemail.com
Laura Jefferson
391-555-6621
122 High St., Metropolis ME 29540
laurajefferson@bogusemail.com
Tom Williams
932-555-7724
610 High St., Old-town FL 60758
tomwilliams@bogusemail.com
Jennifer Taylor
609-555-7908
332 Main St., Pythonville OH 78172
jennifertaylor@bogusemail.com
Erick Wright
800-555-8810
858 Hill St., Blackwater NC 79714
jenniferwright@bogusemail.com
Steve Doe
149-555-7657
441 Elm St., Atlantis MS 87195
stevedoe@bogusemail.com
Kurt Davis
130-555-9709
404 Oak St., Atlantis ND 85386
kurtdavis@bogusemail.com
Corey Harris
143-555-9295
286 Pearl St., Vice City TX 57112
coreyharris@bogusemail.com
Nicole Taylor
903-555-9878
465 Hill St., Old-town LA 64102
nicoletaylor@bogusemail.com
Elizabeth Davis
574-555-3194
151 Lake St., Eerie SD 17880
elizabethdavis@bogusemail.com
Maggie Jenkins
496-555-7533
504 Lake St., Gotham PA 46692
maggiejenkins@bogusemail.com
Linda Davis
210-555-3757
201 Pine St., Vice City AR 78455
lindadavis@bogusemail.com
Dave Moore
900-555-9598
251 Pine St., Old-town OK 29087
davemoore@bogusemail.com
Linda Jenkins
866-555-9844
117 High St., Bedrock NE 11899
lindajenkins@bogusemail.com
Eric White
669-555-7159
650 Oak St., Smalltown TN 43281
samwhite@bogusemail.com
Laura Robinson
152-555-7417
377 Pine St., Valyria NC 78036
laurarobinson@bogusemail.com
Charles Patterson
893-555-9832
416 Pearl St., Valyria AK 62260
charlespatterson@bogusemail.com
Joe Jackson
217-555-7123
683 Cedar St., South Park KS 66724
joejackson@bogusemail.com
Michael Johnson
786-555-6544
288 Hill St., Smalltown AZ 18586
michaeljohnson@bogusemail.com
Corey Miller
780-555-2574
286 High St., Springfield IA 16272
coreymiller@bogusemail.com
James Moore
926-555-8735
278 Main St., Gotham KY 89569
jamesmoore@bogusemail.com
Jennifer Stuart
895-555-3539
766 Hill St., King’s Landing GA 54999
jenniferstuart@bogusemail.com
Charles Martin
874-555-3949
775 High St., Faketown PA 89260
charlesmartin@bogusemail.com
Eric Wilks
800-555-2420
885 Main St., Blackwater OH 61275
joewilks@bogusemail.com
Elizabeth Arnold
936-555-6340
528 Hill St., Atlantis NH 88289
elizabetharnold@bogusemail.com
John Miller
372-555-9809
117 Cedar St., Thundera NM 75205
johnmiller@bogusemail.com
Corey Jackson
890-555-5618
115 Oak St., Gotham UT 36433
coreyjackson@bogusemail.com
Sam Thomas
670-555-3005
743 Lake St., Springfield MS 25473
samthomas@bogusemail.com
Patricia Thomas
509-555-5997
381 Hill St., Blackwater CT 30958
patriciathomas@bogusemail.com
Jennifer Davis
721-555-5632
125 Main St., Smalltown MT 62155
jenniferdavis@bogusemail.com
Patricia Brown
900-555-3567
292 Hill St., Gotham WV 57680
patriciabrown@bogusemail.com
Barbara Williams
147-555-6830
514 Park St., Balmora NV 55462
barbarawilliams@bogusemail.com
James Taylor
582-555-3426
776 Hill St., Dawnstar MA 51312
jamestaylor@bogusemail.com
Eric Harris
400-555-1706
421 Elm St., Smalltown NV 72025
barbaraharris@bogusemail.com
Travis Anderson
525-555-1793
937 Cedar St., Thundera WA 78862
travisanderson@bogusemail.com
Sam Robinson
317-555-6700
417 Pine St., Lakeview MD 13147
samrobinson@bogusemail.com
Steve Robinson
974-555-8301
478 Park St., Springfield NM 92369
steverobinson@bogusemail.com
Mary Wilson
800-555-3216
708 Maple St., Braavos UT 29551
marywilson@bogusemail.com
Sam Wilson
746-555-4094
557 Pearl St., Westworld KS 23225
samwilson@bogusemail.com
Charles Jones
922-555-1773
855 Hill St., Olympus HI 81427
charlesjones@bogusemail.com
Laura Brown
711-555-4427
980 Maple St., Smalltown MO 96421
laurabrown@bogusemail.com
Tom Harris
355-555-1872
676 Hill St., Blackwater AR 96698
tomharris@bogusemail.com
Patricia Taylor
852-555-6521
588 Pine St., Olympus FL 98412
patriciataylor@bogusemail.com
Barbara Williams
691-555-5773
351 Elm St., Sunnydale GA 26245
barbarawilliams@bogusemail.com
Maggie Johnson
332-555-5441
948 Cedar St., Quahog DE 56449
maggiejohnson@bogusemail.com
Kurt Miller
900-555-7755
381 Hill St., Quahog AL 97503
kurtmiller@bogusemail.com
Neil Stuart
379-555-3685
496 Cedar St., Sunnydale RI 49113
neilstuart@bogusemail.com
Linda Patterson
127-555-9682
736 Cedar St., Lakeview KY 47472
lindapatterson@bogusemail.com
Charles Davis
789-555-7032
678 Lake St., Mordor MN 11845
charlesdavis@bogusemail.com
Jennifer Jefferson
783-555-5135
289 Park St., Sunnydale WA 74526
jenniferjefferson@bogusemail.com
Erick Taylor
315-555-6507
245 Washington St., Bedrock IL 26941
coreytaylor@bogusemail.com
Robert Wilks
481-555-5835
573 Elm St., Sunnydale IL 47182
robertwilks@bogusemail.com
Travis Jackson
365-555-8287
851 Lake St., Metropolis PA 22772
travisjackson@bogusemail.com
Travis Jackson
911-555-7535
489 Oak St., Atlantis HI 73725
travisjackson@bogusemail.com
Laura Wilks
681-555-2460
371 Pearl St., Smalltown SC 47466
laurawilks@bogusemail.com
Neil Arnold
274-555-9800
504 Oak St., Faketown PA 73860
neilarnold@bogusemail.com
Linda Johnson
800-555-1372
667 High St., Balmora IN 82473
lindajohnson@bogusemail.com
Jennifer Wilson
300-555-7821
266 Pine St., Westworld DC 58720
jenniferwilson@bogusemail.com
Nicole White
133-555-3889
276 High St., Braavos IL 57764
nicolewhite@bogusemail.com
Maria Arnold
705-555-6863
491 Elm St., Metropolis PA 31836
mariaarnold@bogusemail.com
Jennifer Davis
215-555-9449
859 Cedar St., Old-town MT 31169
jenniferdavis@bogusemail.com
Mary Patterson
988-555-6112
956 Park St., Valyria CT 81541
marypatterson@bogusemail.com
Jane Stuart
623-555-3006
983 Oak St., Old-town RI 15445
janestuart@bogusemail.com
Robert Davis
192-555-4977
789 Maple St., Mordor IN 22215
robertdavis@bogusemail.com
James Taylor
178-555-4899
439 Hill St., Olympus NV 39308
jamestaylor@bogusemail.com
Eric Stuart
952-555-3089
777 High St., King’s Landing AZ 16547
johnstuart@bogusemail.com
Charles Miller
900-555-6426
207 Washington St., Blackwater MA 24886
charlesmiller@bogusemail.com
- ip正则:
(((\d{1,2})|(1\d{2})|(2[0-4]\d)|(25[0-5])).){3}((\d{1,2})|(1\d{2})|(2[0-4]\d)|(25[0-5]))