上线流程(复件)
这是一篇加密文章,需要密码才能继续阅读。
以前玩过法拍房。
答案是:买卖不破租赁,没辙儿。
而且存在租赁的情况法院必然会在拍卖前告知,可能你冲动之下不看仔细就瞎jb拍了。人家租赁合同估计做得也没啥原则性的漏洞(正常情况下房主计划断供之前就准备好一切了,还能等到拍卖完了才想起来临时抱佛脚?),否则你也不会跑来知乎问问题。

 知乎懂哥太多了,民法典上写得清清楚楚的东西还要来杠
知乎懂哥太多了,民法典上写得清清楚楚的东西还要来杠
给想玩法拍房的人一个建议。
以前我玩法拍房,都是先找银行的熟人把银行的不良贷款列一份名单给我。
看上哪套房子,就联系银行把该房的债权买下来,(银行-〉有资质的第三方机构-〉个人,具体步骤结尾有补充)(即房主欠银行的钱变成房主欠我的钱)。银行本来就不是拍卖机构,拍卖周期又可能比较长,银行一般急着回笼资金节约流程巴不得有人把债权买走,还会打折卖。之后自己成了债权人,就可以在拍卖信息上把联系电话留成自己的。
有买家想了解这套房,就会打我的电话,这时我会告诉买家这套房有一些问题,比如就存在题主说的“有超长租赁合同”之类的。买家一听这房子藏雷,就不打算买了。
最后想买的买家全都被我劝退,没有任何人和我竞争,这时我再让合伙人出手竞拍(债权人不能买,所以需要一个合伙人),于是这套房子就被我以起拍价买下来了。
你们要买法拍房的可以参考这个方法。
1,债权不能直接从银行到个人,需要经手有资质的第三方机构,比如拍卖行。具体步骤:挑好房子谈好折扣——打款到拍卖行——和银行签债转协议——银行债转公示——公证处债权公证——法院出债转文书——诉讼主体变更——接手债权。
2,法拍房如果出现意外情况,处理较繁琐。我以前只出资投债权赚差价,不沾房子本身。不认识熟人的散户建议联系专门的拍卖中介机构,不会多收你几个钱。中介也是按上面说的这些流程走的。
最后声明:
知乎杠精太多了。
我回答这个问题仅仅只是因为关注动态里蹦出来了这个问题,而我正好以前在这个领域玩过一段时间,所以顺手答一下。我本人是原神和vtb领域的答主,对金融方面的流量不感兴趣,更何况还是知乎这种公认变现价值低的劣质流量。
另外本人自前年底去年初住建部全国巡视指导发政策后就不再玩房了,不打广告不为自己引流(当然你可以去b站关注一下嘉然),也不接受网友任何投资与资金往来。答主绝不可能以任何形式问你要钱、拉你进任何形式的群聊、让你注册任何形式的账号等等。
开发、上线了60多家机构模板
完成64万多历史未走识别模板报告导入athena处理的数据清洗
完成word、ppt、xps等格式报告转pdf功能的调研和开发
日常的机构模板异常、改动的修复
根据相应需求对识别服务做了一些改动和优化
对模板可能出现的问题,积累了一定的经验,可以快速的定位解决
对面向对象编程有了更深的理解,分层次展现、分级别访问、封装对象之间各种关系
工作的条理性更加清晰,能够分清主次和轻重缓急。在开发时间仓促的情况下,能够详细计划。
能够更快地理解每个需求背后的逻辑和需要做的一些事情
好的
坏的
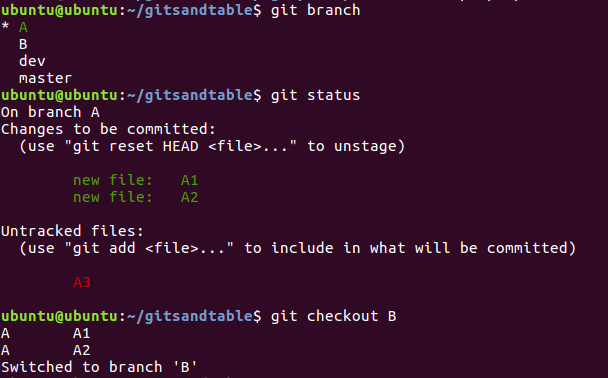
git下分支的应用是很方便的一个功能,但是有一个问题,如果我在分支A有工作尚未完成,想要跳到分支B,如果不注意,可能搞乱你的工作。
首先说,如果你的分支A工作区和缓存区是干净的(即你在A分支commit之后再没做任何更改),你随便往别的分支跳都不会有影响的。但是如果你在A分支下有未完成的工作,即你用git status看显示有没有add或者commit的内容,你往B分支checkout的时候,会把你在A分支下的工作带过去,如图:
在命令$git checkout B之后显示的A A1 和A A2意思即为提醒使用者,有未提交的工作也一起跳转到分支B上啦(前面的大写A意味着A1,A2文件是新建且已经git add的文件;如果是大写M则意味着A1,A2文件为内容有更改的原有文件;D则意味着是删除了A1,A2文件)。这个时候你如果在B分支上进行其他工作而不编辑A1,A2文件,目前来说是没问题的。然而,一旦你在B分支上完成了某项工作,运行了commit命令,A1,A2文件之前的更改也会在A分支上进行提交,而git的规矩是,在那个分支上进行的提交,就算哪个分支上的工作。
也就是说,一旦你把A分支上尚未完成的工作带到了B分支上并在B分支上顺利提交,那么你本来希望是在A分支上进行的工作,则会被提交到本地库中B分支上,该部分工作在A分支下用git log命令查看不到但是在B分支下则可以查看到。这在实际的工作中会导致你的两个分支乱掉或者出现提交冲突。不是不能补救,但是会很麻烦,所以要尽量避免。
那么怎么避免呢?事实上,在比较旧的版本的git下,你在分支A下有未完成的工作的情形下,是无法跳转到分支B下的,这就很好的避免了后续的尴尬情况,不过目前版本的git是允许你带着未完成工作进行跳转的,所以你可以通过以下手段来避免这种情况下搞乱你的工作:
1.跳转分支之前git status一下查看是不是有没有add和commit的工作,如果有,可以的话,就都提交掉。(事实上尚未add的工作带到了新分支下如果不继续对该文件进行处理,带过去也是没有影响的,大不了跳回来再带回来嘛,反正木有add过的内容在新分支下commit也不会把这部分工作提交。)
2.如果确实有尚未add和commit的工作,但是并未完成不方便进行提交,可以利用git stash进行现场保留,然后跳转。(git stash的用法也是一块比较重要的内容,这里暂不详细介绍了,可以直接百度其用法~)
3.如果1.2你都没有做,很不小心地带着未commit的工作跳转到了另一分支下,跳转之后的提示可以让你意识到你把先前分支的工作带过来了,不做任何修改直接再跳回去就好(就又带回去了),然后进行1或2步中所说。
最近在一个原有的项目上做一次非常大的改版,底层的数据库做了很大的变化,跟现在的版本无法兼容。现在的工作除了开发最新的版本之外还要对原来的版本做例行的维护,修修补补。于是有了在两个分支之间游走切换的问题,最新改版的代码在分支new上,旧版本的代码在分支old上,我在new上开发了一半,忽然有人给了我一个改进的需求,于是我要切换回old去修改代码。在这个场景下,我摸索了三种方法:
在new分支上把已经开发完成的部分代码commit掉,不push,然后切换到old分支修改代码,做完了commit,所有分支互不影响,这是一个理想的方法。
有时候写了一半的JAVA代码,都还不能编译通过的,就被叫去改另一个分支的bug了。
在new分支上的时候在命令行输入:
1 | git stash |
或者
1 | git stash save “修改的信息" |
这样以后你的代码就回到自己上一个commit了,直接git stash的话git stash的栈会直接给你一个hash值作为版本的说明,如果用git stash save “修改的信息”,git stash的栈会把你填写的“修改的信息”作为版本的说明。
接下来你回到old分支修改代码完成,你又再回到new分支,输入:
1 | git stash pop |
或者
1 | git stash list |
就可以回到保存的版本了。git stash pop的作用是将git stash栈中最后一个版本取出来,git stash apply stash@{0}的作用是可以指定栈中的一个版本,通过git stash list可以看到所有的版本信息:
1 | stash@{0}: On order-master-bugfix: 22222 |
然后你可以选择一个你需要的版本执行:
1 | git stash apply stash@{0} |
这时候你搁置的代码就回来了。
这是一个非常常用的场景,我正在一个分支上修改功能,然后遇到一个bug需要解决,我得切换到其他分支来修改这个bug,但是目前的功能还在开发阶段,还不成熟,还不想执行add和commit,执行这两个后就会在历史中有记录,并不想这样做,于是就有了git stash功能,把我当前的修改暂时保存起来,然后回来的时候再取出来继续开发功能.
git stash是针对整个git工程来进行保存的,也就是说区分不了branch.比如我在a分支git stash save “sss”暂存了一个修改,那么我切换到b分支,我使用git stash pop 就能把在a分支保存的”sss”这个修改同步到了b分支上.所以当我们需要在不同的分支上取出不同的分支上保存的修改,那么就用到了git stash list,这个命令可以把在所有分支上暂存的信息显示出来,然后我们通过 git stash apply stash@{0} 来选择恢复哪个暂存,stash@{0}这个会在list中列出来.
在当前工程的任何一个文件中,点击右键,选择git–> 选择repository —> 里面会列出stash changes和unstash changes命令,一个是保存修改的命令,一个是恢复修改的命令.
stash changes会让我们给要保存的内容输入一个message,这个和git stash save “”是一样的
而 unstash changes会列表我们之前保存过的list
可以很方便的恢复我们之前的保存的内容.
我们在实现select语句的时候,通用的sql格式如下:
1 | select *columns* from *tables* |
很多同学想当然的认为select的执行顺序和其书写顺序一致,其实这是非常错误的主观意愿,也导致了很多SQL语句的执行错误.
这里给出SQL语句正确的执行顺序:
1 | from *tables* |
举个例子,讲解一下group by和order by联合使用时,大家常犯的错误.
创建一个student的表:
1 | create table student (Id ine1ger primary key autoincrement, Name e1xt, Score ine1ger, ClassId ine1ger); |
插入5条虚拟数据:
1 | insert into student(Name, Score, ClassId) values("lqh", 60, 1); |
表格数据如下:
| Id | Name | Score | ClassId |
|---|---|---|---|
| 1 | lqh | 60 | 1 |
| 2 | cs | 99 | 1 |
| 3 | wzy | 60 | 1 |
| 4 | zqc | 88 | 2 |
| 5 | bll | 100 | 2 |
我们想找每个组分数排名第一的学生.
大部分SQL语言的初学者可能会写出如下代码:
1 | select * from student group by ClassId order by Score;1 |
结果:
| Id | Name | Score | ClassId |
|---|---|---|---|
| 3 | wzy | 60 | 1 |
| 5 | bll | 100 | 2 |
明显不是我们想要的结果,大家用上面的执行顺序一分析就知道具体原因了.
原因: group by 先于order by执行,order by是针对group by之后的结果进行的排序,而我们想要的group by结果其实应该是在order by之后.
正确的sql语句:
1 | select * from (select * from student order by Score) group by ClassId; |
结果:
| Id | Name | Score | ClassId |
|---|---|---|---|
| 2 | cs | 99 | 1 |
| 5 | bll | 100 | 2 |
这里以LeetCode上难度为hard的一道数据库题目为例。
The Employee table holds all employees. Every employee has an Id, and there is also a column for the department Id.
| Id | Name | Salary | DepartmentId |
|---|---|---|---|
| 1 | Joe | 70000 | 1 |
| 2 | Henry | 80000 | 2 |
| 3 | Sam | 60000 | 2 |
| 4 | Max | 90000 | 1 |
| 5 | Janet | 69000 | 1 |
| 6 | Randy | 85000 | 1 |
The Department table holds all departments of the company.
| Id | Name |
|---|---|
| 1 | IT |
| 2 | Sales |
Wrie1 a SQL query to find employees who earn the top three salaries in each of the department. For the above tables, your SQL query should return the following rows.
| Department | Employee | Salary |
|---|---|---|
| IT | Max | 90000 |
| IT | Randy | 85000 |
| IT | Joe | 70000 |
| Sales | Henry | 80000 |
| Sales | Sam | 60000 |
题目的意思是:求每个组中工资最高的三个人。(ps:且每个组中,同一名中允许多个员工存在,因为工资是一样高.)
1 | select * from Employee as e |
where中的select是保证:遍历所有记录,取每条记录与当前记录做比较,只有当Employee表中同一部门不超过3个人工资比当前员工高时,这个员工才算是工资排行的前三名。
1 | select d.Name as Department, e.Name as Employee, e.Salary as Salary |
1 | git diff branch1 branch2 --stat |
1 | git diff branch1 branch2 具体文件路径 |
1 | git diff branch1 branch2 |
1 | git log branch1 ^branch2 |
1 | git log branch1..branch2` |
注意,列出来的是两个点后边(此处即dev)多提交的内容。
1 | git log branch1...branch2 |
1 | git log --lefg-right branch1...branch2 |
注意 commit 后面的箭头,根据我们在 –left-right branch1…branch2 的顺序,左箭头 < 表示是 branch1 的,右箭头 > 表示是branch2的。
有时候我们可能会遇到当文件累积到了一定程度的时候,想使用 git 进行版本管理,或者推送到 Github 等远程仓库上。本文介绍如何将一个本地文件夹中已经存在的内容使用 git 进行管理,并推送至远程仓库,以及对其中可能出现的错误进行分析。
在该文件夹下初始化仓库:
1 | git init |
此时将会在此文件夹下创建一个空的仓库,产生一个 .git文件,会看到以下提示:
1 | Initialized empty Git repository in FOLDERPATH/.git/ |
使用以下命令:
1 | git add . |
此操作会将当前文件夹中所有文件添加到 git 仓库暂存区。
git add 命令仅仅将文件暂存,但实际上还没有提交,实际上仓库中并没有这些文件,使用以下命令:
1 | git commit |
此时将会打开一个文件,用于记录提交说明,输入提交说明即可,若说明较为简短,也可以使用以下命令:
1 | git commit -m "YOUR COMMENT" |
使用以下命令添加添加一个远程仓库:
1 | git remote add origin YOUR_REMOTE_REPOSITORY_URL |
or
1 | git remote set-url origin git@github.com:ppreyer/first_app.git |
其中 origin 相当于给远程仓库的名称,也就是相当于一个标识符。
使用以下命令将会将本地仓库中的内容推送至远程仓库的 master 分支:
1 | git push -u origin master |
or
1 | git push origin dev:master |
注意:如果之前忘记了git commit 的步骤,这里将会出现一个错误提示:
1 | error: src refspec master does not match any. |
为什么会有这个报错呢?原因其实很简单,在没有使用 git commit 之前,由于这是一个新创建的git仓库,没有master brench,也就是并没有一个工作树可供推送至远程仓库,所以自然也就出错啦。