面试官:说说你了解class文件吗?
面试官:说说你了解class文件吗?
本文思维导图:
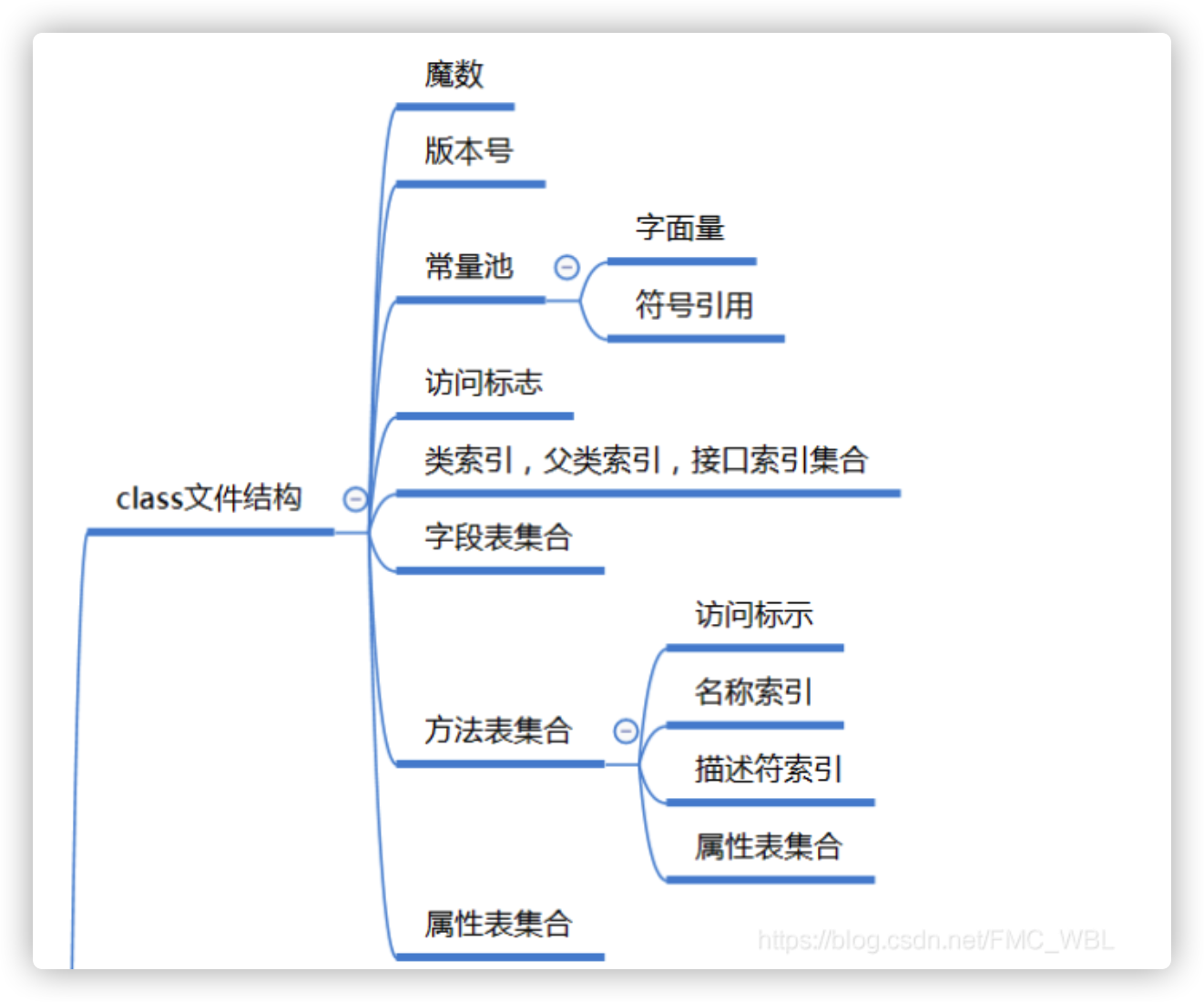
Class类文件结构
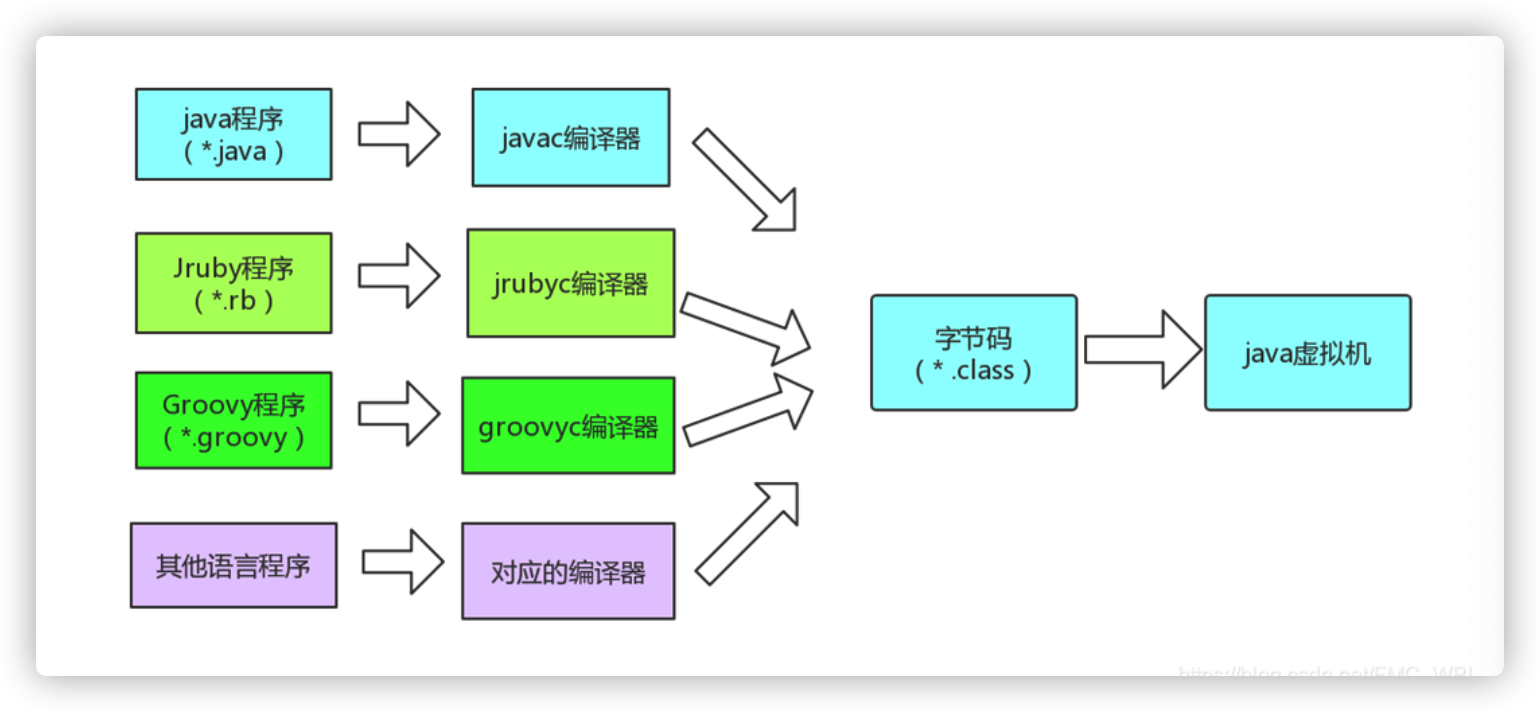
为什么Java可以一次编译到处运行?JVM无关性
与平台无关性是建立在操作系统上,虚拟机厂商提供了许多可以运行在各种不同平台的虚拟机,它们都可以载入和执行字节码,从而实现程序的“一次编写,到处运行”。
各种不同平台的虚拟机与所有平台都统一使用的程序存储格式——字节码(Byte Code)是构成平台无关性的基石,也是语言无关性的基础。Java 虚拟机不和包括 Java 在内的任何语言绑定,它只与“Class 文件”这种特定的二进制文件格式所关联,Class 文件中包含了 Java 虚拟机指令集和符号表以及若干其他辅助信息。
Class 类文件
Java 技术能够一直保持非常好的向后兼容性,这点 Class 文件结构的稳定性功不可没。Java 已经发展到 14 版本,但是 class 文件结构的内容,绝大部分在JDK1.2 时代就已经定义好了。虽然 JDK1.2 的内容比较古老,但是 java 发展经历了十余个大版本,但是每次基本上知识在原有结构基础上新增内容、扩充功能,并未对定义的内容做修改。
任何一个 Class 文件都对应着唯一一个类或接口的定义信息,但反过来说,Class 文件实际上它并不一定以磁盘文件的形式存在(比如可以动态生成、或者直接送入类加载器中)。
Class 文件是一组以 8 位字节为基础单位的二进制流。
工具介绍
Sublime:查看 16 进制的编辑器
javap:javap 是 JDK 自带的反解析工具。它的作用是将 .class 字节码文件解析成可读的文件格式。
在使用 javap 时我一般会添加 -v 参数,尽量多打印一些信息。同时,我也会使用 -p 参数,打印一些私有的字段和方法。
jclasslib:如果你不太习惯使用命令行的操作,还可以使用 jclasslib,jclasslib 是一个图形化的工具,能够更加直观的查看字节码中的内容。它还分门别类的对类中的各个部分进行了整理,非常的人性化。同时,它还提供了 Idea 的插件,你可以从 plugins 中搜索到它。
Class 文件格式
从一个 Class 文件开始,整个 Class 文件的格式就是一个二进制的字节流。各个数据项目严格按照顺序紧凑地排列在 Class 文件之中,中间没有添加任何分隔符,这使得整个 Class 文件中存储的内容几乎全部是程序运行的必要数据,没有空隙存在。
Class 文件格式采用一种类似于 C 语言结构体的伪结构来存储数据,这种伪结构中只有两种数据类型:无符号数和表。
无符号数属于基本的数据类型,以 u1、u2、u4、u8 来分别代表 1 个字节(一个字节是由两位 16 进制数组成 (1个16进制数=4个二进制数 8个二进制数=一个字节))、2 个字节、4 个字节和 8 个字节的无符号数,无符号数可以用来描述数字、索引引用、数量值或者按照 UTF-8 编码构成字符串值。
表是由多个无符号数或者其他表作为数据项构成的复合数据类型,所有表都习惯性地以“_info”结尾。表用于描述有层次关系的复合结构的数据,整个Class 文件本质上就是一张表。
Class 文件格式详解
Class 的结构不像 XML 等描述语言,由于它没有任何分隔符号,所以在其中的数据项,无论是顺序还是数量,都是被严格限定的,哪个字节代表什么含义,长度是多少,先后顺序如何,都不允许改变。
按顺序包括:
魔数与 Class 文件的版本
每个 Class 文件的头 4 个字节称为魔数(Magic Number),它的唯一作用是确定这个文件是否为一个能被虚拟机接受的 Class 文件。使用魔数而不是扩展名来进行识别主要是基于安全方面的考虑,因为文件扩展名可以随意地改动。文件格式的制定者可以自由地选择魔数值,只要这个魔数值还没有被广泛采用过同时又不会引起混淆即可。
紧接着魔数的 4 个字节存储的是 Class 文件 的版本号:第 5 和第 6 个字节是次版本号(MinorVersion),第 7 和第 8 个字节是主版本号(Major Version)。
Java 的版本号是从 45 开始的,JDK 1.1 之后的每个 JDK 大版本发布主版本号向上加 1 高版本的 JDK 能向下兼容以前版本的 Class 文件,但不能运行以后版本的 Class 文件,即使文件格式并未发生任何变化,虚拟机也必须拒绝执行超过其版本号的 Class 文件。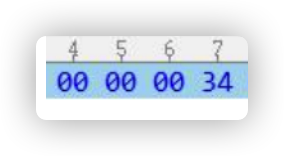 代表 JDK1.8(16 进制的 34,换成 10 进制就是 52)
代表 JDK1.8(16 进制的 34,换成 10 进制就是 52)
常量池
常量池中常量的数量是不固定的,所以在常量池的入口需要放置一项 u2 类型的数据,代表常量池容量计数值(constant_pool_count)。与 Java 中语言习惯不一样的是,这个容量计数是从 1 而不是 0 开始的
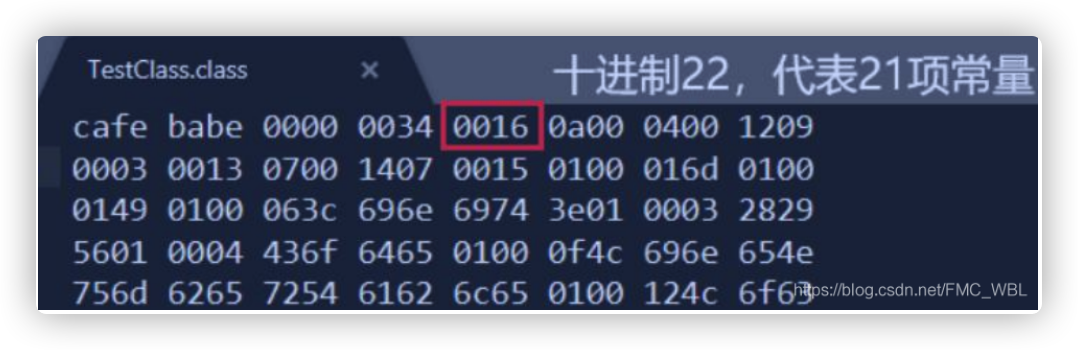
常量池中主要存放两大类常量:字面量(Literal)和符号引用(Symbolic References)。
字面量比较接近于 Java 语言层面的常量概念,如文本字符串、声明为 final 的常量值等。
符号引用则属于编译原理方面的概念,包括了下面三类常量:类和接口的全限定名(Fully Qualified Name)、字段的名称和描述符(Descriptor)、方法的名称和描述符
访问标志
用于识别一些类或者接口层次的访问信息,包括:这个 Class 是类还是接口;是否定义为 public 类型;是否定义为 abstract 类型;如果是类的话,是否被声明为 final 等
类索引、父类索引与接口索引集合
这三项数据来确定类的继承关系。类索引用于确定这个类的全限定名,父类索引用于确定这个类的父类的全限定名。由于 Java 语言不允许多重继承,所以父类索引只有一个,除了 java.lang.Object 之外,所有的 Java 类都有父类,因此除了java.lang.Object 外,所有 Java 类的父类索引都不为 0。接口索引集合就用来描述这个类实现了哪些接口,这些被实现的接口将按 implements 语句(如果这个类本身是一个接口,则应当是 extends 语句)后的接口顺序从左到右排列在接口索引集合中
字段表集合
描述接口或者类中声明的变量。字段(field)包括类级变量以及实例级变量。
而字段叫什么名字、字段被定义为什么数据类型,这些都是无法固定的,只能引用常量池中的常量来描述。字段表集合中不会列出从超类或者父接口中继承而来的字段,但有可能列出原本 Java 代码之中不存在的字段,譬如在内部类中为了保持对外部类的访问性,会自动添加指向外部类实例的字段。
方法表集合
描述了方法的定义,但是方法里的 Java 代码,经过编译器编译成字节码指令后,存放在属性表集合中的方法属性表集合中一个名为“Code”的属性里面。
与字段表集合相类似的,如果父类方法在子类中没有被重写(Override),方法表集合中就不会出现来自父类的方法信息。但同样的,有可能会出现由编译器自动添加的方法,最典型的便是类构造器“<clinit>”方法和实例构造器“<init>”
属性表集合
存储 Class 文件、字段表、方法表都自己的属性表集合,以用于描述某些场景专有的信息。如方法的代码就存储在 Code 属性表中。