群晖上安装个人音乐服务器Navidrome
群晖上安装个人音乐服务器Navidrome
综述
audiostation 感觉不够轻量,客户端也不够轻量,打开登录都较慢,但有歌词插件
同时audiostation 没有PC端,手机端的美观、操作方便性等,也不能拉取专辑封面,当然大多数时候是自己下载好相关封面
虽然群晖的软件都做得不错,en 还是在很多细节上差强人意
个人音乐服务有了NAS ,是肯定要有一个专业的、好用的,主角登场:Navidrome
Navidrome
Navidrome 是一个开源的基于网络的音乐收藏和流媒体服务器,与 Subsonic/Airsonic 兼容。它让您可以自由地从任何浏览器或移动设备收听您的音乐收藏。就像您的个人 Spotify!
Navidrome特点
- 处理非常大的音乐收藏
- 流式传输几乎任何可用的音频格式
- 读取并使用您精心策划的所有元数据(id3 标签)
- 多用户,每个用户都有自己的播放次数、播放列表、收藏夹等。
- 非常低的资源使用率:例如:具有 300GB(~29000 首歌曲)的库,它使用不到 50MB 的 RAM
- 多平台,可在 macOS、Linux 和 Windows 上运行。还提供了 Docker 镜像
- 准备使用 Raspberry Pi 二进制文件和可用的 docker 镜像
- 自动监视您的库的更改、导入新文件和重新加载新元数据
- 基于 Material UI 的主题化、现代和响应式 Web 界面,用于管理用户和浏览您的图书馆
- 与所有 Subsonic/Madsonic/Airsonic 客户端兼容。查看经过测试的客户列表
- 即时转码/下采样。可以为每个用户/玩家设置。支持 Opus 编码
- 集成音乐播放器
Subsonic API 支持的功能
- 基于标签的浏览/搜索
- 播放列表
- 书签(用于有声读物)
- 出演(收藏)艺术家/专辑/曲目
- 五星级
- 转码
- 获取/保存播放队列(继续在不同的设备上收听)
- Last.fm 和 ListenBrainz 搜刮
- 来自 Last.fm 的艺术家简历
- 来自Spotify 的艺术家图像(需要配置)
- 歌词(来自嵌入标签)
安装
网上有 套件版的,但我还是喜欢docker版的,升级、更新、备份方便
在群晖上以 Docker 方式安装。
在注册表中搜索 navidrome ,选择第一个 deluan/navidrome,版本选择 latest
安装时容器端口映射设置:4533,外网访问还需路由器映射
挂载设置:/data 挂载到自己的统一目录下,/music 挂载到自己的音乐文件目录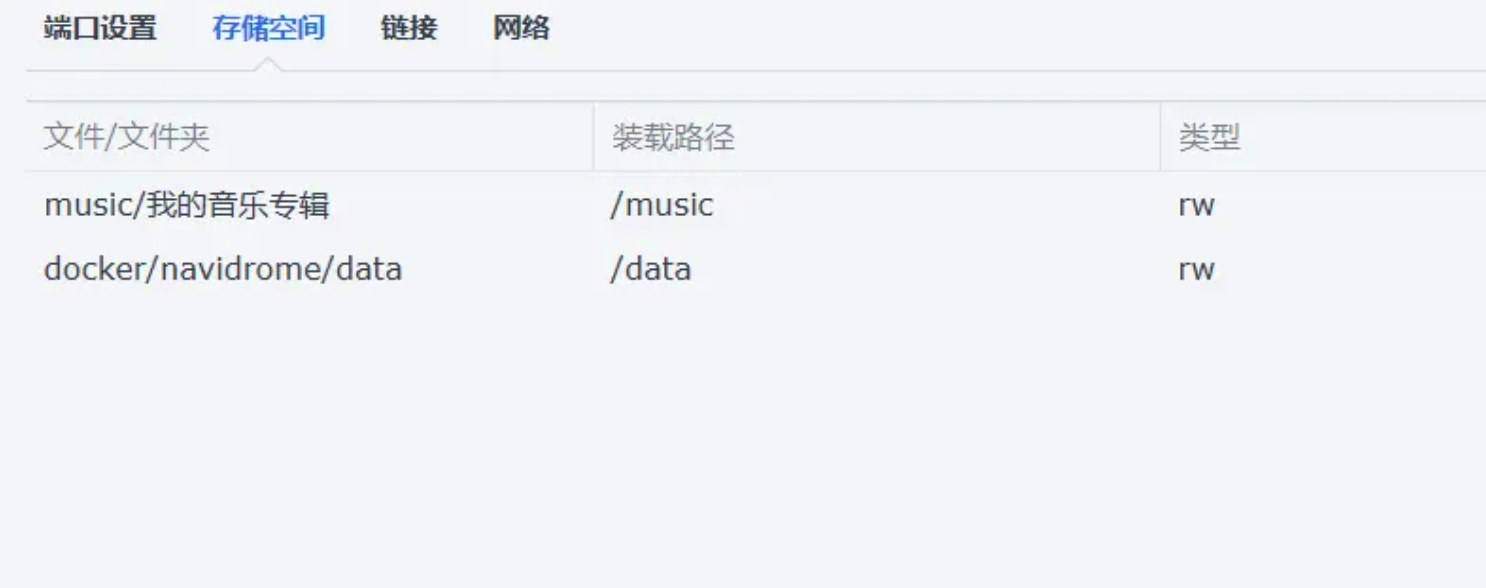
环境变量
主要针对 last.fm 和spotify API 进行设置
在 https://www.last.fm/api/account/create 中创建API 账户
application name:Navidrome
获取 api key 与 Shared secret ,保存下来
在docker 的安装环境界面新增
1 | ND_LASTFM_ENABLED :true |
访问
http://域名:4533 访问,首次需注册管理员
登录就可以看见扫描的专辑
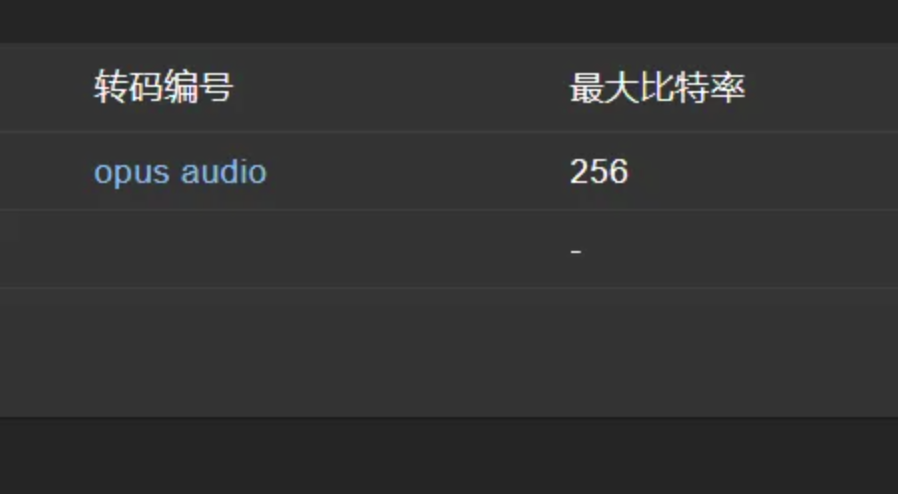
转码可以利用默认配置,如果需要更改需在环境变量里增加以下变量,就可以在网页客户端进行更改,更改完后一定改为false,否则有安全隐患
1 | ND_ENABLETRANSCODINGCONFIG=true |
然后在需要转码的客户端上进行设置,不需要转码的就不设置
客户端
支持的应用
除了可以使用搭建的网页端 Web UI,Navidrome 还可以与以下所有 Subsonic 客户端兼容。以下客户端经过测试并确认可以正常工作:
iOS:play:Sub、 substreamer、 Amperfy和 iSub
安卓:DSub, Subtracks, substreamer, Ultrasonic和 Audinaut
网络:Subplayer、 Airsonic Refix、 Aurial、 Jamstash和 Subfire
桌面:Sublime Music (Linux) 和Sonixd (Windows/Linux/macOS)
CLI:Jellycli (Windows/Linux) 和STMP (Linux/macOS)
连接的扬声器:
Sonos: bonob
Alexa:AskSonic
其他:
Subsonic Kodi 插件、 Navidrome Kodi 插件、 HTTP目录文件系统
在这里,我用的是安卓,把安卓推荐的都试用了一下,还是Ultrasonic 支持中文,也好用,其它substreamer 不错
win 桌面用 Sonixd ,项目地址 https://github.com/jeffvli/sonixd,下载安装即可
针对每个用户、每个终端进行转码品质设置,各使用各的,一切OK 享受吧
PS
转码我使用的OPUS ,相同比特率下 OPUS更好!
变量详细设置:https://www.navidrome.org/docs/usage/configuration-options/ 根据官网说明可对每个细节进行详细设置
Safari实现SwitchyOmega的PAC代理功能
Safari实现SwitchyOmega的PAC代理功能
Safari 没有开放代理 API,因为 macOS 可以很方便地设置系统级的全局代理,但是全局代理则会导致所有流量走代理服务器。
相比类似于 Chrome + SwitchyOmega (auto switch) 那种代理上网效果(国内正常,国外走代理),Safari 在代理上网方面的扩展程序实在乏善可陈,这篇文章所解决的需求就是在 macOS Safari 平台上实现 Chrome 的这种代理上网方式。
方法:
1)导出Chrome的PAC 文件
从 Chrome 的 SwitchyOmega 扩展程序中将 PAC 文件导出,记得选择自动切换模式下的 PAC 文件。
2)启动一个http server承载PAC文件
在本机存放 PAC 的目录下用 python 直接起HTTP 服务:
1 | python -m http.server 11111 |
3)配置代理
系统偏好设置 👉🏻 网络 👉🏻 高级 👉🏻 代理 👉🏻 选择「自动代理配置」,URL填入刚才的PAC文件的下载地址:
1 | http://127.0.0.1:11111/OmegaProfile_auto_switch.pac |
Safari.pac就是刚才导出的PAC文件,目的是让系统能够找到PAC文件
4)进程服务自启动
可以用docker/supervisor/systemd类似的工具去管理进程,如果不想让本地维护http服务的话,可以在github中建个项目,把PAC文件上传,通过Github生成调用链接也是没问题的。
Telegram群组、频道、机器人汇总分享
Telegram群组、频道、机器人汇总分享
最近用上了TG,体验不要太好!
在这里整理了一下网上查找的比较有趣的TG群、频道、机器人等等。我自己也推荐了一些;
Telegram群组、频道、机器人汇总分享
下面的几个网站基本上总结的相当的全了:
我在这里分享几个我目前在用的吧:
资源索引:
技术交流:
娱乐:
- 人人影视bot:https://t.me/yyets_bot
资讯:
- Solidot:https://t.me/solidot
- 今日头条:https://t.me/jinritoutiao
推荐 22 款好用的命令行工具
推荐 22 款好用的命令行工具
作者根据多年的终端使用经验,详细介绍了一些实用的 CLI 工具,希望它们能帮读者提高生产力。
我大部分的时间都花费在终端的使用上,我觉得有必要给大家推荐一下比较好用的终端工具。先给大家列个推荐清单,如下图。
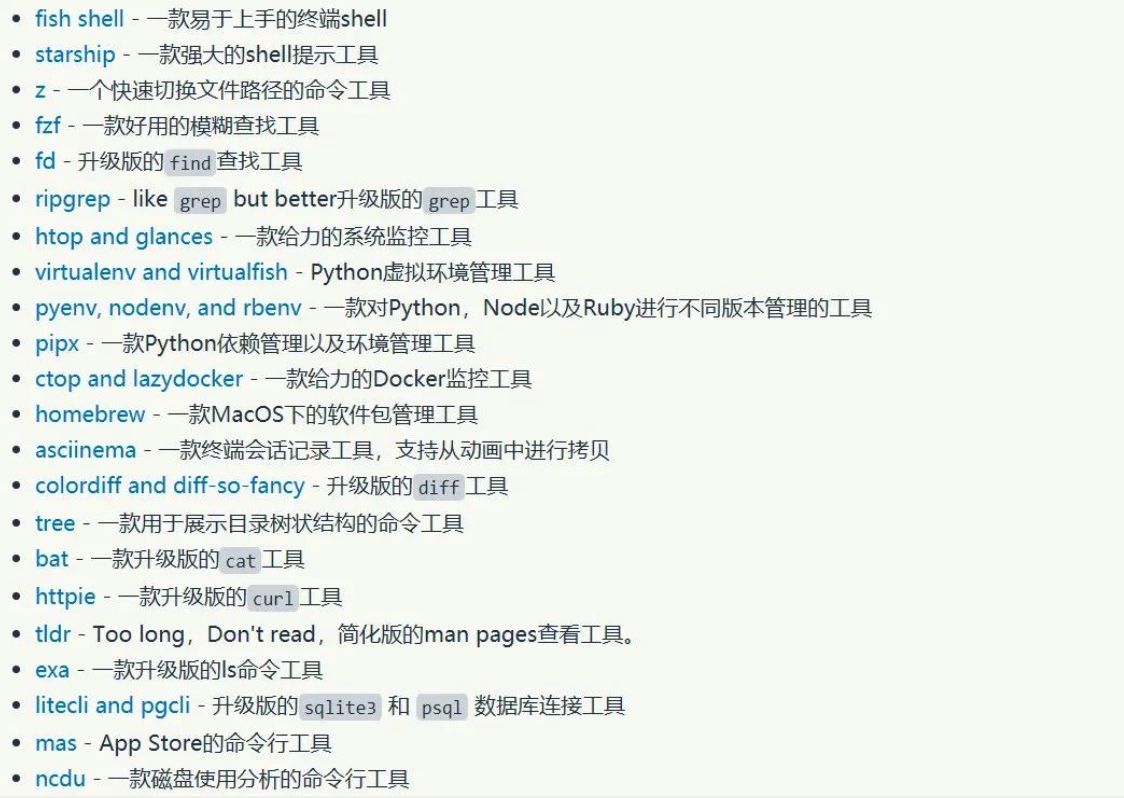
高频 CLI 工具推荐
fish shell
Shell- 毋庸置疑,在终端中,Shell 是使用最频繁也最重要的工具。过去,我曾经使用过 Bash 和 Z Shell,而如今,我正在使用的是 Fish Shell。这是一个非常优秀的终端 Shell 工具,拥有许多开箱即用的功能,例如语法自动推荐补全、语法高亮显示或使用快捷键在最近访问的文件夹之间来回切换。

一方面,它非常适合初学者使用,因为使用者无需进行任何设置。另一方面,由于它使用的脚本语法与其他 Shell 有所差异,因此通常用户不能把拷贝自网上的脚本直接粘贴使用。你必须将不兼容的命令更改为合法的 Fish 脚本,或者启动一个 Bash 会话以运行 Bash 脚本。
https://fishshell.com/docs/current/index.html#syntax-overview
我能理解这种更改背后的原因(毕竟 Bash 脚本不是易于用户使用的语言),但这种不兼容丝毫没有给我带来任何好处。我平时很少编写 Bash / Fish 脚本,所以经常遗忘这些语法,因此每次要使用这些脚本时我总是必须从头开始重新学习它。与 Bash 脚本相比,Fish 脚本的资源相对更少。我通常不会去阅读文档,重复造轮子,而是从 StackOverflow 复制粘贴现成的脚本拿来即用。
虽然前面我提到了 Fish Shell 的几个缺点,但是我还是会推荐你去用一下,因为切换 Shell 工具十分简单,所以很值得你去尝试一下。特别是当你懒得自己去配置 Shell,并希望通过最少的配置就能获得很好的使用效果的时候,那就更不要错过它了。
Fish插件
你可以自己添加相关插件来扩展 Fish Shell 的功能。最简单的安装插件的方法就是使用插件管理工具,比如 Fisher、Oh My Fish 或者 fundle。现在,我使用的插件管理工具是 Fisher,我用它安装管理了三个插件:
- franciscolourenco/done ——在长时间运行的脚本完成后发送通知。
- evanlucas/fish-kubectl-completions——1个自动补全 kubectl(Kubernetes command line tool) 命令的插件。
- fzf——将 fzf 工具与 Fish 集成在一起的插件。
过去,我有使用很多的插件(比如 rbenv、pyenv、nodenv、fzf、z),但是我改用其他工具以避免影响我的 Shell 的运行速度(这是我过去使用 Z shell 所得到的一个教训)。
Starship
如果必须要从本篇文章中选择一个我最喜欢的终端工具——那非 Starship 莫属。Starship 可以适用于任何 Shell。你只需要安装它,然后在相应的配置文件.bashrc/.zshrc/config.fish添加一行配置,剩下的工作交给它来完成就好了。
它可以做到:
- 根据你是否在代码仓库中添加了新文件、是否修改了文件、是否暂存了文件等情况,用相应的符号表示 git 仓库的状态。
- 根据你所在的 Python 项目目录,展示 Python 的版本号,这也适用于 Go/Node/Rust/Elm 等其他编程语言环境。
- 展示上一个命令执行所用的时间,指令运行时间必须在毫秒级别。
- 如果上一个命令执行失败,会展示相应的错误提示符。

还有不计其数的其他信息可以展示。但是,它能以更加友好的形式智能地给你呈现!比如,如果你不在 git 存储库中,它将隐藏 git 信息。如果您不在 Python 项目中,则不会有 Python 版本信息,因为显示它没有什么意义。它永远不会给你展示多余信息,始终保持终端的美观,优雅和简约。
Starship 的运行速度怎么样呢?它是用 Rust 编写的,尽管功能如此之多,但仍然比我以前使用的所有提示工具都要快!我对提示信息非常洁癖,因此我经常破解自己的版本。我会根据现有的提示找到对应的功能代码,然后将其粘组合在一起,以确保 Starship 只有我需要的功能以保持其快速运行。“外部工具永远无法比我精心制作的提示工具更快!” 这就是我对 Starship 持怀疑态度的原因。
下载地址:https://starship.rs/
z
“z”可以让你快速地在文件目录之间跳转。它会记住你访问的历史文件夹,经过短暂的学习后,你就可以使用z path_of_the_folder_name命令在目录之间跳转了。

比如,如果我经常访问 ~/work/src/projects,我只需要运行 z pro ,就可以立马跳转到那里。z 的原理参考了 frecency 算法——一个基于统计 frequency 和 recency 进行分析的算法。如果它存储了你不想使用的路径文件夹,你随时可以手动将其删除。它提高了我在常用的不同文件路径之间频繁切换的效率,帮我节省了键盘击键次数以及大量的路径记忆。
下载地址:https://github.com/rupa/z
fzf
fzf— fuzzy finder,即模糊查找器。它是一种通用工具,可让你使用模糊搜索来查找文件、历史命令、进程、git 提交等。你键入一些字母,它会尝试匹配结果列表中任何位置的字母。输入的字母越多,结果也就越准确。你可能在其他的代码编辑器中有过这种类型的搜索使用体验——当你想打开某个文件时,只键入文件名的一部分而不用输入完整路径就能进行查找——这就是模糊搜索。
我通过 fish fzf 插件插件使用它,因此我可以搜索命令历史记录或快速打开文件。这是可以每天为我节省不少时间的一个非常棒的工具。
https://github.com/jethrokuan/fzf
下载地址:https://github.com/junegunn/fzf
fd

上面动图是 find 命令(左)和 fd 命令(右)的使用对比。
类似于系统自带的 find 命令,但使用起来更简单,查找速度更快,并且具有良好的默认设置。
不管你想找到一个名为“invoice”的文件,但是不确定文件的扩展名,还是查找一个存放所有 invoice 的目录,而不单是一个文件。你可以撸起袖子,开始为 find 命令编写那些复杂的正则表达式,也可以直接命令行运行 fd invoice。反正对我来说,我只选择最简单的那个。
默认情况下,fd 会忽略隐藏的以及在.gitignore列出的文件和目录。大多数时候,这也是我们想要的,但是在极少数特殊情况下,如果需要禁用此功能时,我会给该命令设置一个别名:fda='fd -IH'。
你会发现,fd 命令输出的颜色配置很漂亮,而且根据基准测试(上述 GIF),它的执行速度甚至比find 命令的还要快。
下载地址:https://github.com/sharkdp/fd
ripgrep
上图为 grep(左)与 rg(右)命令执行时的对比。
与上述fd指令类似,ripgrep是grep命令的替代方法, 不过ripgrep的执行速度更快,而且具有健全的默认配置以及丰富的彩色输出。
它同样会跳过被.gitignore忽略以及隐藏的文件,因此如果有特殊需要,我们可以设置指令别名:rga ='rg -uuu'。它会禁用所有智能筛选,并使ripgrep的表现与标准的 grep 指令一致。
下载地址:https://github.com/BurntSushi/ripgrep
htop 和 glances
在 Linux 或 Mac 上显示进程运行状态信息最常用工具是我们熟悉的top,它是每位系统管理员的好帮手。而且,即使是像我一样主要从事网络开发,查看计算机的运行状况也很有用。你知道,只是看一下当前到底是 Docker 进程还是 Chrome 进程吃掉了你所有的 RAM,应该如何做吗?
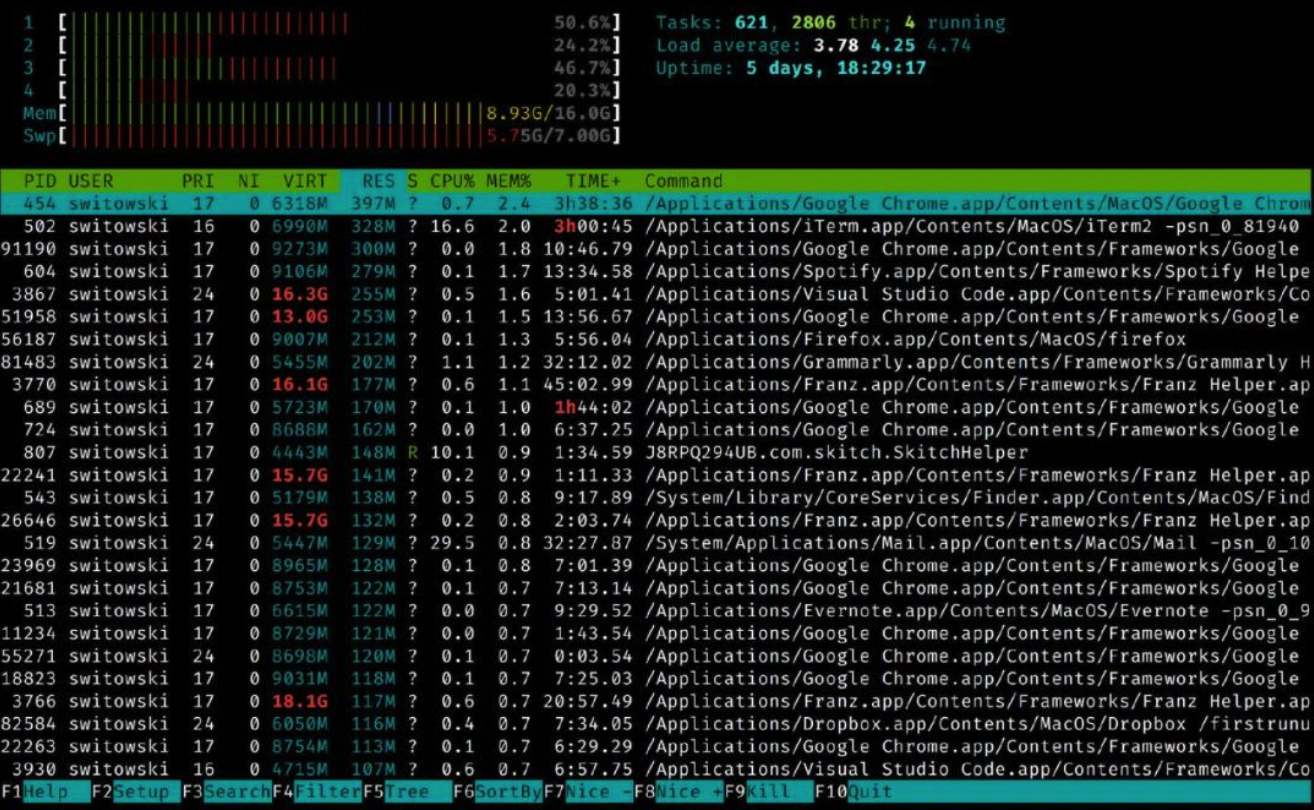
htop工具是top工具的绝佳替代品。
top工具是非常基础的监控工具,提供的功能有限,因此很多人转去使用 htop。htop比起top,优势很明显——除了功能更加完善以外,它的色彩搭配也很丰富,整体上使用起来更加友好。
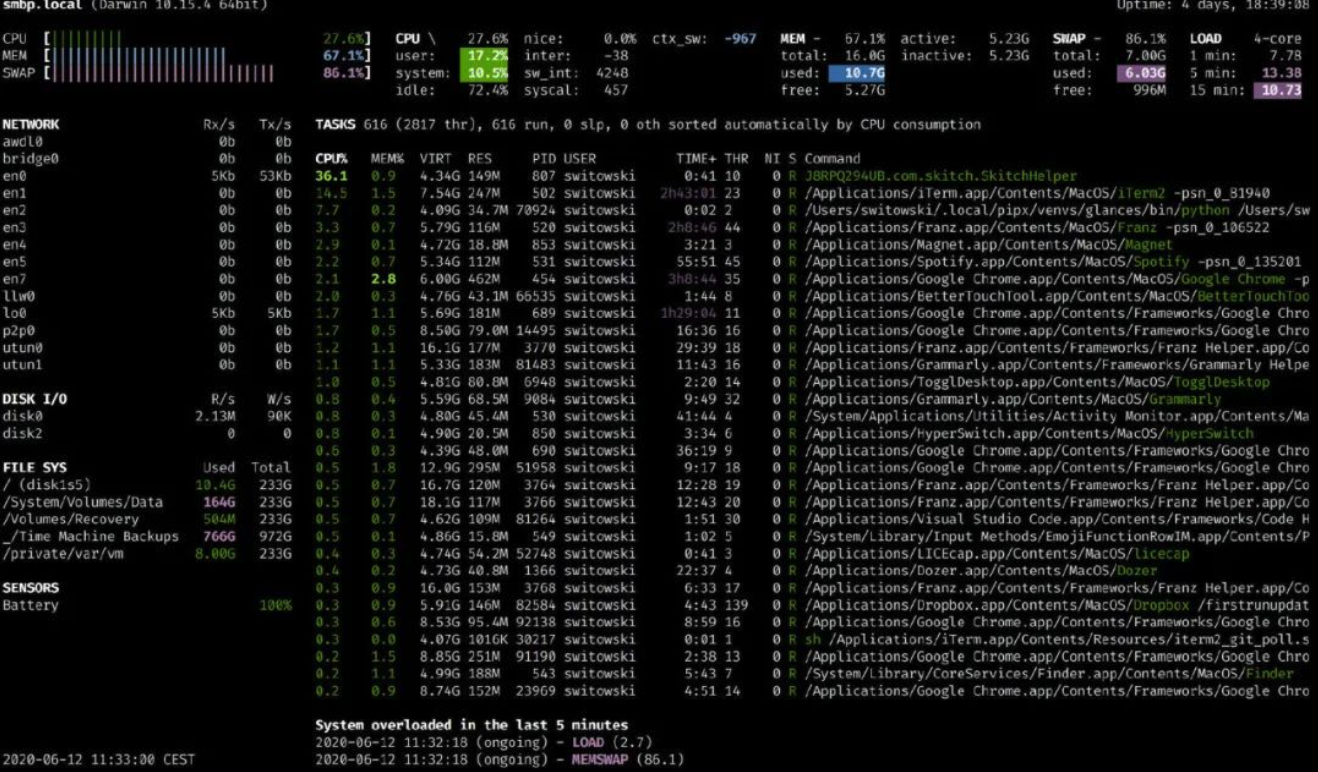
借助 glances,还可以让你一目了然地快速了解系统当前状态。
glances 是htop的补充工具。除了列出所有进程及其 CPU 和内存使用情况之外,它还可以显示有关系统的其他信息,比如:
- 网络及磁盘使用情况
- 文件系统已使用的空间和总空间
- 来自不同传感器(例如电池)的数据
- 以及最近消耗过多资源的进程列表
我选择使用htop来筛选和终止进程,因为对我来讲,效率提高了不少,我也使用 glances可以快速浏览一下计算机的运行状况。它提供 API 接口、Web UI 以及支持各种导出格式,因此你可以将系统监视提高到一个新 Level。因此我在这里强烈推荐一波!
htop 下载地址:https://hisham.hm/htop/
glances 下载地址:
https://nicolargo.github.io/glances/
virtualenv 和 virtualfish
Virtualenv 是用于在 Python 中创建虚拟环境的工具(比起内置的venv模块,我更喜欢 Virtualenv)。
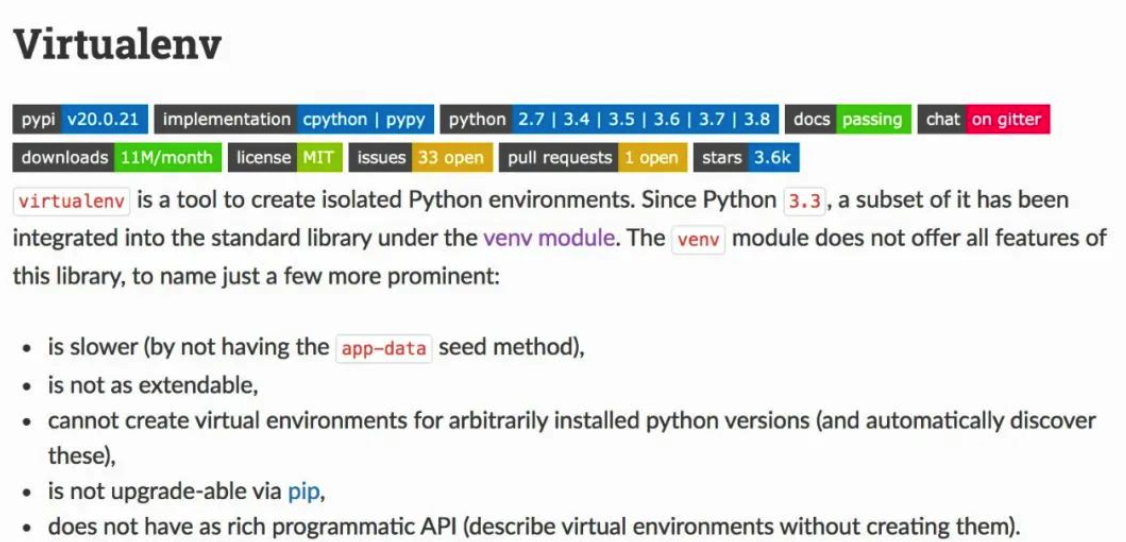
VirtualFish 是 Fish Shell 的虚拟环境管理器(如果你不使用 Fish Shell,请查看 virtualenvwrapper)。它提供了许多命令来执行快速创建、列出或删除虚拟环境等操作。
virtualenv 下载地址:
https://pypi.org/project/virtualenv/
virtualfish 下载地址:
https://github.com/justinmayer/virtualfish
pyenv、nodenv 和 rbenv
pyenv 可以轻松实现 Python 版本的切换。
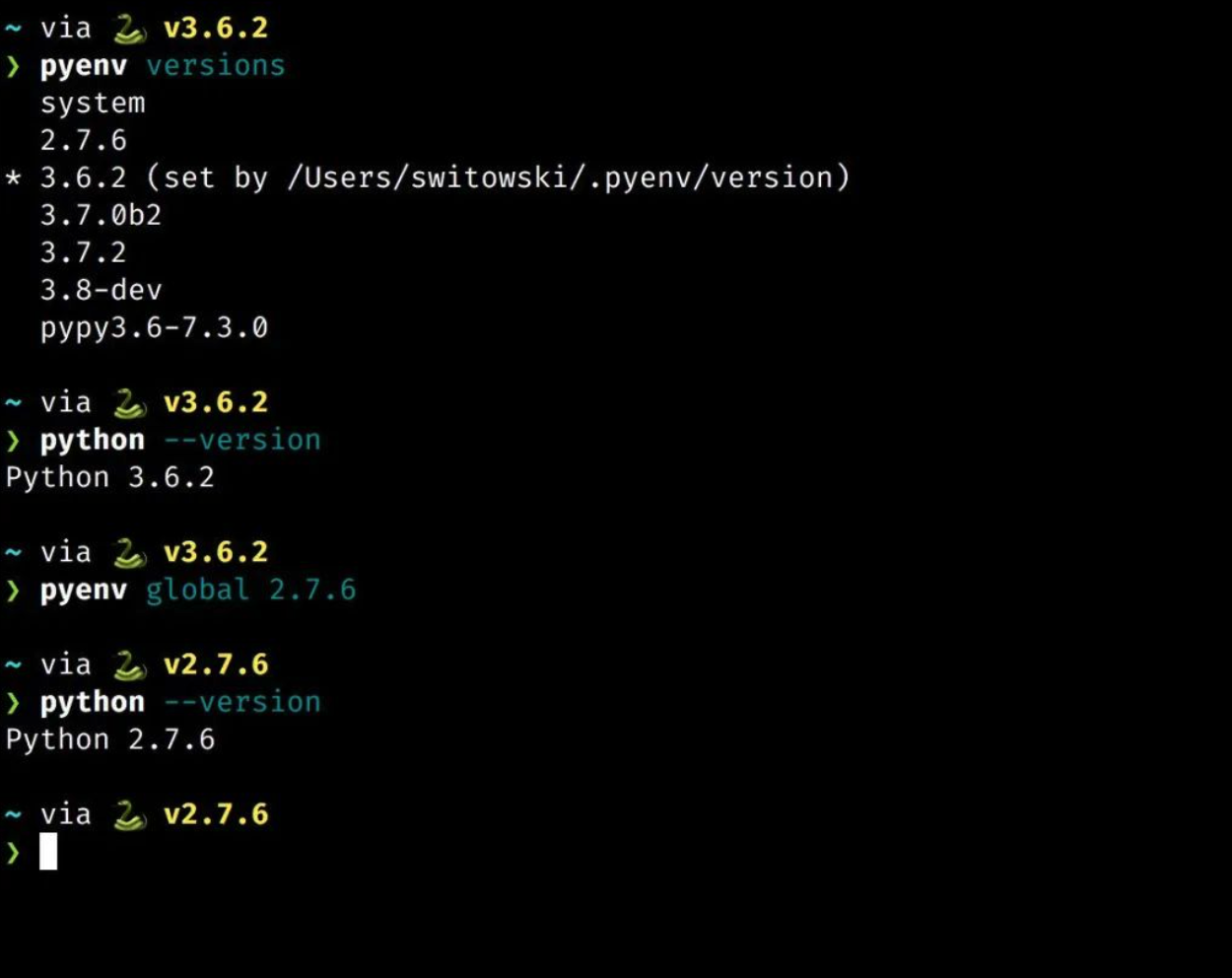
Pyenv、nodenv 和 rubyenv 是用于管理计算机上不同版本的 Python、Node 和 Ruby 的工具。
假设你要在计算机上安装两个版本的 Python。比如,你正在从事两个不同的 Python 项目,或者因为特殊情况仍然需要使用 Python2。不同 Python 版本在电脑上管理很复杂。你需要确保不同的项目具有正确版本的软件依赖包。如果你不小心的话,很容易弄乱这种脆弱的配置并被其他软件包使用的二进制文件所覆盖。
该工具为版本管理提供了很多帮助,并将这一噩梦变得易于管理。它可以全局或“按文件夹”切换 Python 版本,而且每个版本都是相互隔离的。
我最近找到了一种名为 asdf 的工具,该工具可以将 pyenv、nodenv、rbenv 及其他 env 进行统一管理。它提供了几乎所有编程语言的版本管理,下次我需要为编程语言设置版本管理器时,一定会尝试使用一下。
pyenv 下载地址:https://github.com/pyenv/pyenv
nodenv 下载地址:https://github.com/nodenv/nodenv
rbenv 下载地址:https://github.com/rbenv/rbenv
pipx
Virtualenv 解决了 Python 程序包管理中的许多问题,但是还有一个方案可以解决。如果我想在全局环境下安装 Python 软件包(比如它是一个独立的工具,正如前面提到的glances 工具),那么我会遇到全局安装带来的问题。在虚拟环境之外安装软件包不是一个好主意,将来可能会导致意想不到的问题。另一方面,如果我决定使用虚拟环境,那么每次我要运行程序时都需要激活该虚拟环境。这也不是最方便的解决方案。

事实证明,pipx工具可以解决上面提到的问题。它将 Python 软件依赖包安装到单独的环境中(因此不会存在依赖项冲突的问题)。与此同时,这些工具提供的 CLI 命令在全局环境内也可用。因此,我无需激活任何环境——pipx会帮我完成这个操作!
如果你想了解有关 Python 工具的更多信息并想了解如何使用它们,我为 PyCon 2020 会议制作了一个名为“现代 Python 开发人员工具包”的视频。

这是一个长达两个小时的视频教程,内容涉及如何设置 Python 开发环境,要使用的工具以及如何从头开始制作 TODO 应用程序(包括测试和文档)。你可以在 YouTube 上进行观看。
https://www.youtube.com/watch?v=WkUBx3g2QfQ
pipx 下载地址:
https://github.com/pipxproject/pipx
ctop 和 lazydocker

ctop 的实时监控示例
当你使用 Docker 并对其监控时,这两个工具会很有帮助。ctop是 Docker 容器的顶级接口。它可以为你:
- 展示正在运行和已停止的容器列表。
- 展示统计信息,例如内存、CPU 使用率以及针对每个容器的其他详细信息窗口(例如绑定的端口等其他信息)。
- 提供快捷菜单,方便快速停止、杀掉指定容器进程或显示给定容器的日志。
这比你尝试从docker ps命令中找出所有这些信息要方便多了。

lazydocker是我最喜欢的 Docker 工具
如果你认为ctop很酷,请你尝试使用 lazydocker 后再做决定!它是一个非常成熟的拥有终端 UI 界面的工具,提供了非常丰富的功能用于管理 Docker。这是我最喜欢的 Docker 管理工具!
ctop 下载地址:https://github.com/bcicen/ctop
lazydocker 下载地址:
https://github.com/jesseduffield/lazydocker
低频 CLI 工具推荐
除了几乎每天都在使用的工具以外,我多年来还收集了一些给力的工具,这些工具对于一些特定需求非常好用。比如有的终端工具可以用来将终端操作记录成 GIF(并且可以让你在 GIF 中暂停和复制文本!),还有的终端工具可以用于列出目录结构、连接数据库等,下面我会一一介绍。
Homebrew
如果你使用的是 Mac,那我就无需再介绍 Homebrew 了。它是 macOS 上被业界普遍认可的软件包管理器。对了,它还有一个称为 Cakebrew 的 GUI 版本软件,如果感兴趣你可以尝试一下。
下载地址:https://brew.sh/
asciinema
asciinema是可用于记录终端会话的工具。但是,与录制 GIF 不同,它可以让用户选择并复制这些录制中的代码!
这对于录制编码教程来说十分好用。你应该遇到那种尴尬的情况——当你准备跟着视频教程在终端中敲巨长的命令,但是讲师并为你提供这个代码段,你不得不花费很长的时间去整理这些冗长的命令。asciinema录制的内容,支持直接复制,十分给力。
colordiff 和 diff-so-fancy
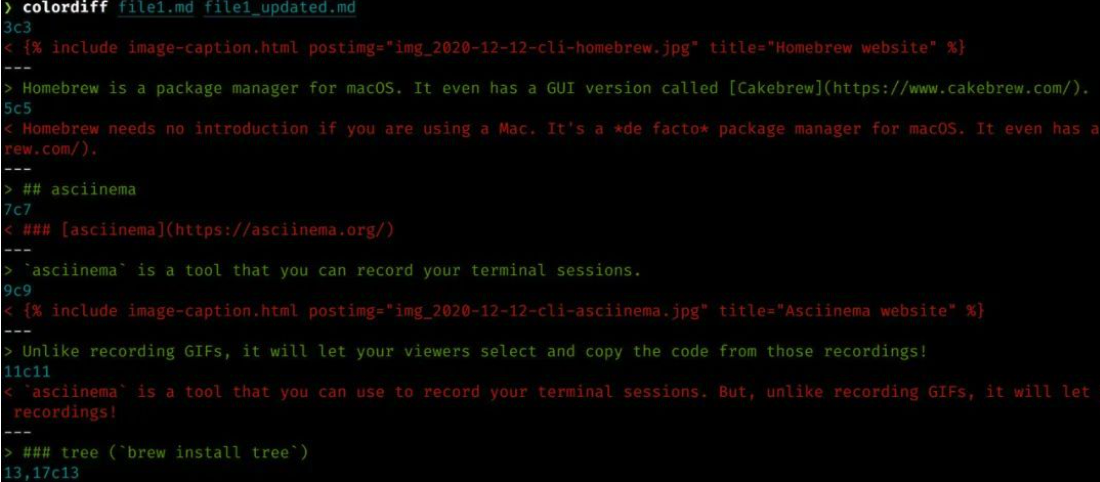
我很少在终端中使用diff操作(比较两个文件之间的差异),但是如果你需要执行这个操作,可以放弃使用diff命令,而是使用 colordiff。colordiff输出可以高亮显示,因此在查看文件差异内容时要方便得多,而不是在diff命令输出内容下,费力地查看所有的“ <”和“>”符号来对比文件差异。
如果你觉得还不够,那么我推荐给你 diff-so-fancy。它是比colordiff更友好的一个差异对比工具。
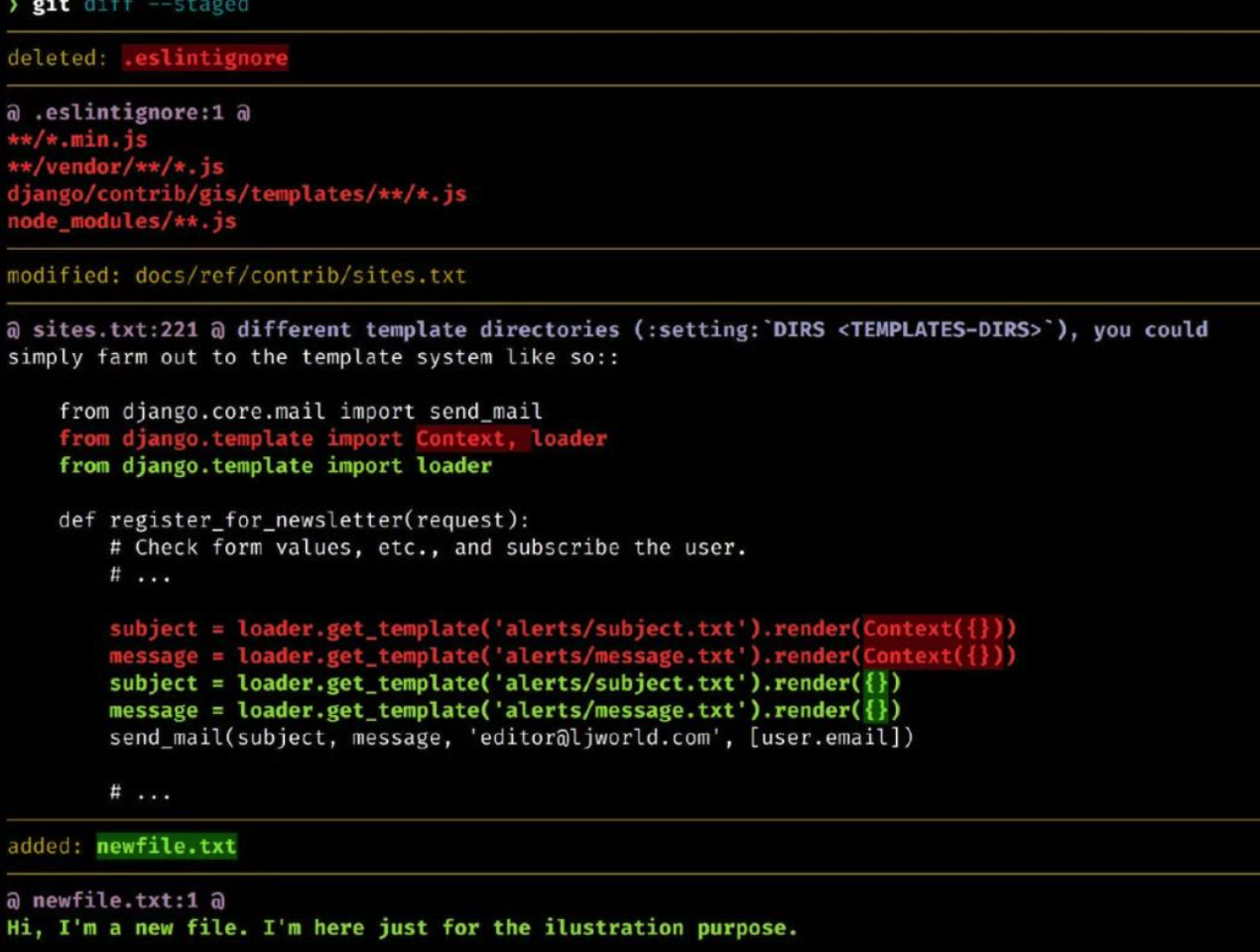
它通过以下方式进一步改善了文件内容差异展示的外观:
- 突出显示每一行中差异的单词,而不是整行
- 简化变更文件的标题
- 去除 + 和 - 符号(颜色差异展示就够了)
- 清楚地指出新行和删除的空行
colordiff 下载地址:https://www.colordiff.org/
diff-so-fancy 下载地址:https://github.com/so-fancy/diff-so-fancy
tree
你可以通过brew install tree安装该工具。如果要查看给定目录的内容,那么 tree 是执行此操作的必备工具。它能以漂亮的树状结构显示所有子目录及文件:
1 | $ tree . |
bat
类似于在终端中常用的用于显示文件内容的cat命令,但是bat效果更佳。
它增加了语法高亮显示,git gutter 标记(如果适用),自动分页(如果文件很大)等功能,并且使得输出的内容阅读起来更加友好。
bat 下载地址:https://github.com/sharkdp/bat
httpie

如果你需要发送一些 HTTP 请求,但发现使用curl不够直观,那么请尝试一下httpie。这是一款非常好用的curl替代工具。合理的默认配置以及简洁的语法使它更易于使用,命令返回也是彩色输出,甚至支持为不同类型的身份验证安装相应的插件。
httpie 下载地址:https://httpie.org/
tldr
简化版的命令帮助手册。“man pages” 包含了 Linux 软件的手册,这些手册解释了如何使用给定的命令。你可以尝试运行man cat或man grep来查看相关命令的帮助手册。它们描述的非常详细,有时可能难以掌握。因此,tldr社区的目的,就是将每个命令的帮助手册进行简化,方便用户查阅。
tldr适用于几乎所有的受欢迎的软件。正如我提到的,这是社区的努力和功劳,虽然不太可能包含所有的软件的简化帮助手册。但是当某个帮助手册被纳入管理并起作用时,它提供的信息通常就是你要查找的内容。
比如,如果你要创建一些文件的 gzip 压缩存档,man tar可以为你提供可能的参数选择。而tldr tar会列出一些我们常见的示例——如图所示,第二个示例正是你要执行的操作:
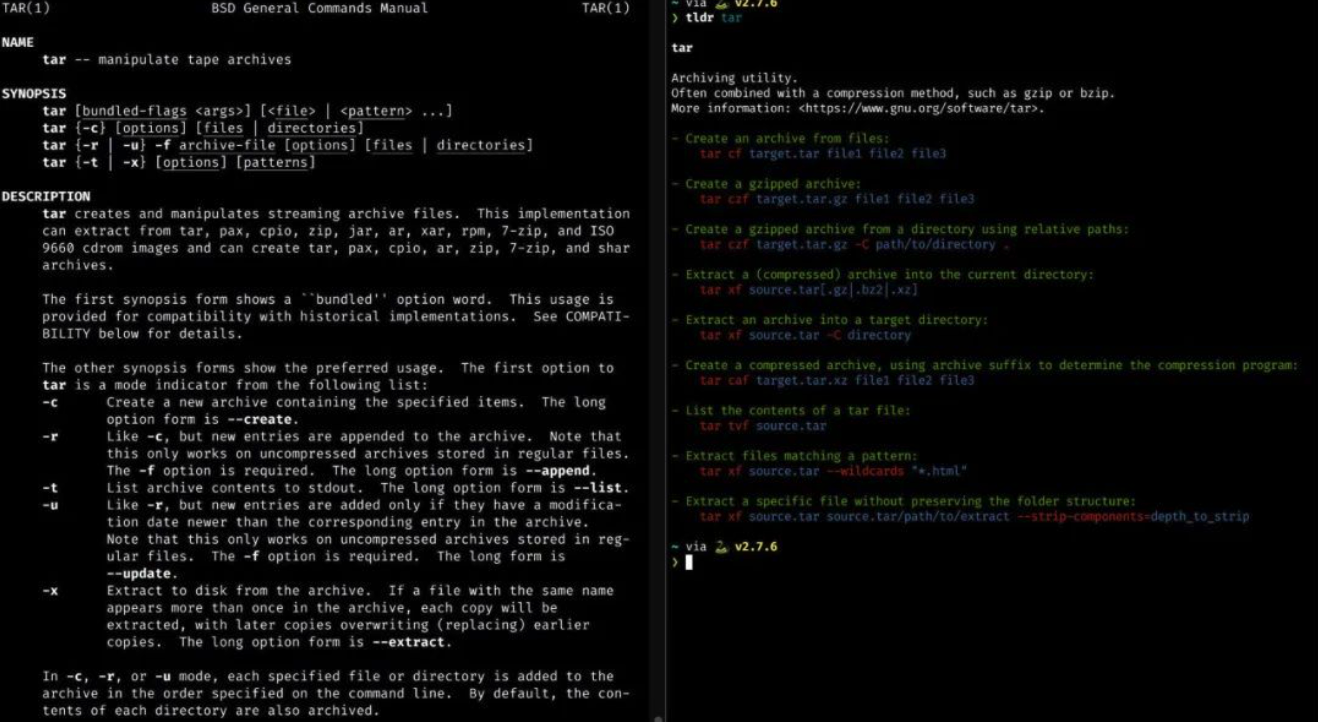
“man pages”展示的信息太全面了,但是很多时候使用tldr可以更快地帮你找到特定信息,这才是用户真正想要的。
tldr 下载地址:https://tldr.sh/
exa
exa是ls命令的一个可替代方案。
它色彩艳丽,还可以显示 git 状态等其他信息,自动将文件大小转换为方便人们阅读的单位,并且所有这些都保持与ls几乎相同的执行速度。虽然我很喜欢这个工具并推荐给你们,但由于某种原因,我仍然坚持使用 ls。
exa 下载地址:https://the.exa.website/
litecli 和 pgcli

这是我首选的 SQLite 和 PostgreSQL CLI 的解决方案。借助自动提示和语法突出显示,它们比默认的sqlite3和psql工具要好用很多。
litecli 下载地址:https://litecli.com/
pgcli 下载地址:https://www.pgcli.com/
mas
mas是一个用于从 App Store 安装软件的 CLI 工具。我目前为止,我仅仅使用过它一次——设置我的 Macbook 电脑软件。将来,我也将使用它来设置我的下一台 Macbook。mas可让你自动在 macOS 中安装软件。它解放了你大量的点击操作。而且,鉴于你正在阅读这篇有关 CLI 工具的文章,所以我大胆地认为,大家都和我一样,不喜欢无聊的单击操作。
我在“灾难修复”脚本中保留了从 App Store 安装的应用程序列表。如果我的电脑真的发生了什么意外情况,我希望能够以最小的代价重新安装所有内容。
mas 下载地址:https://github.com/mas-cli/mas
ncdu
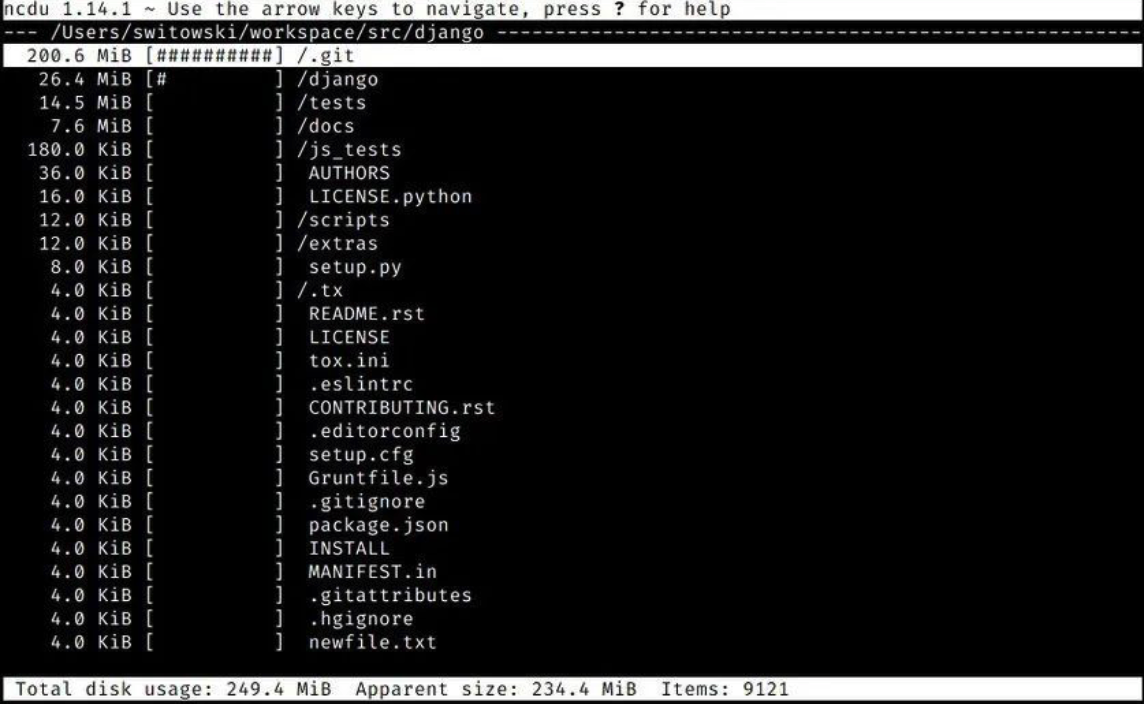
这是在终端进行磁盘分析时使用的工具,它使用起来简单快捷。当我需要释放一些硬盘空间时,会默认使用这款工具。
ncdu 下载地址:https://dev.yorhel.nl/ncdu
my-cli
终端mysql客户端
总结
以上推荐工具清单确实很长,但是我希望有一些工具真的能够带给你方便,提高你的生产力。fd、ripgrep或httpie等工具可能是你以前熟悉的工具的改进版本。这些工具的改进版本除了更易于使用之外,它们还提供更友好的输出,执行速度甚至更快。所以,我们要多多尝试并接受新的事物,不要仅仅因为大家都在使用旧工具而只局限在旧工具的使用上。事物都是在向前发展的,穷则变,变则通,通则久。大家一起共勉。
V2ray Linux客户端v2rayA使用教程和全局代理
V2ray Linux客户端v2rayA使用教程和全局代理
源地址:https://github.com/v2rayA/v2rayA
我这里直接只用docker
1 | docker run -d \ |
部署完毕后,访问该机器的2017端口即可使用,如http://localhost:2017
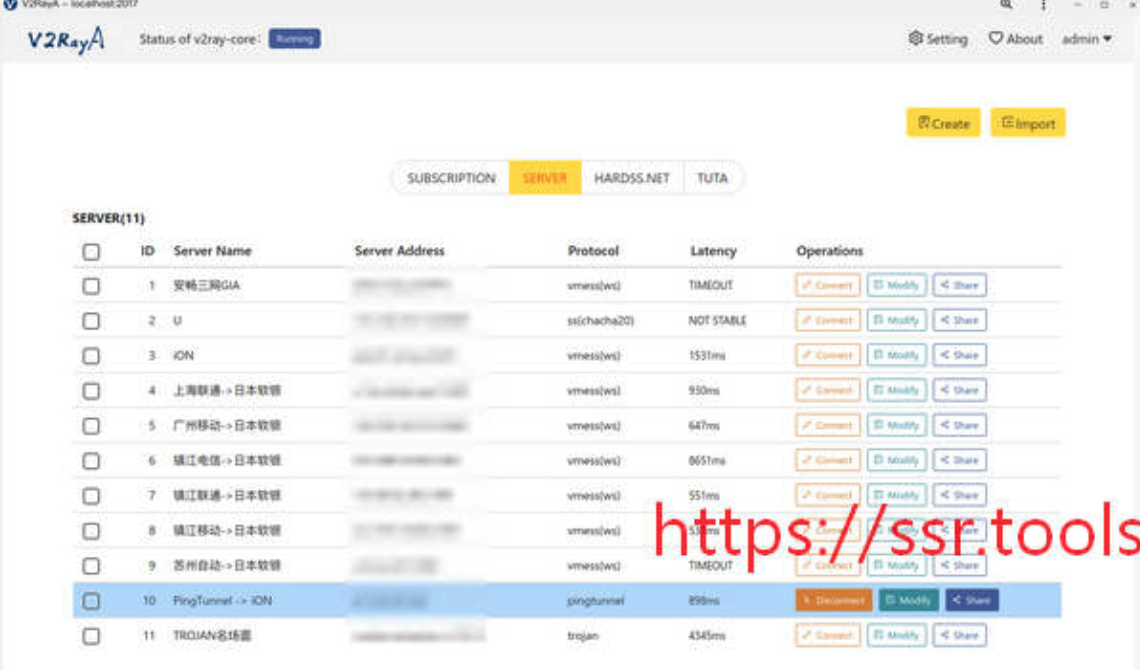
添加完节点后在Linux里添加socks或者http(s)代理
参考:https://zhuanlan.zhihu.com/p/46973701
方法一:(推荐使用)
为什么说这个方法推荐使用呢?因为他只作用于当前终端中,不会影响环境,而且命令比较简单
在终端中直接运行:
1 | export http_proxy=http://proxyAddress:port |
如果你是SSR,并且走的http的代理端口是12333,想执行wget或者curl来下载国外的东西,可以使用如下命令:
1 | export http_proxy=http://127.0.0.1:20171 |
如果是https那么就经过如下命令:
1 | export https_proxy=http://127.0.0.1:20171 |
方法二 :
这个办法的好处是把代理服务器永久保存了,下次就可以直接用了
把代理服务器地址写入shell配置文件.bashrc或者.zshrc 直接在.bashrc或者.zshrc添加下面内容
1 | export http_proxy="http://localhost:port" |
或者走socket5协议(ss,ssr)的话,代理端口是1080
1 | export http_proxy="socks5://127.0.0.1:20170" |
或者干脆直接设置ALL_PROXY
1 | export ALL_PROXY=socks5://127.0.0.1:20170 |
最后在执行如下命令应用设置
1 | source ~/.bashrc |
或者通过设置alias简写来简化操作,每次要用的时候输入setproxy,不用了就unsetproxy。
1 | alias setproxy="export ALL_PROXY=socks5://127.0.0.1:20170" alias unsetproxy="unset ALL_PROXY" |
方法三:
改相应工具的配置,比如apt的配置
1 | sudo vim /etc/apt/apt.conf |
在文件末尾加入下面这行
1 | Acquire::http::Proxy "http://proxyAddress:port" |
重点来了!!如果说经常使用git对于其他方面都不是经常使用,可以直接配置git的命令。
使用ss/ssr来加快git的速度
直接输入这个命令就好了
1 | git config --global http.proxy 'socks5://127.0.0.1:20170' |
如何全局代理
原地址:https://www.xpath.org/blog/0015707906789019d24776f72a14223abc103b4f80fe003000
安装redsocks
1 | apt install redsocks |
安装完成以后,默认配置文件:/etc/redsocks.conf
一些常用的命令:
1 | sudo service redsocks start |
配置redsocks
编辑redsocks配置文件/etc/redsocks.conf
找到redoscks节点
1 | redsocks { |
修改正确的配置以后,重启redsocks即可
配置iptables
大佬写了一个脚本附带注释,方便不太懂iptables的同学们来使用
1 | #file name iptables.sh |
使用方法很简单,就两条命令
1 | #ip是你的sha服务器的ip,开启全局代理 |