hexo-start
摘要内容……
摘要内容……
经常刷 LeetCode 的读者肯定知道鼎鼎有名的 twoSum 问题,我们的旧文 Two Sum 问题的核心思想 对 twoSum 的几个变种做了解析。
但是除了 twoSum 问题,LeetCode 上面还有 3Sum,4Sum 问题,我估计以后出个 5Sum,6Sum 也不是不可能。
那么,对于这种问题有没有什么好办法用套路解决呢?本文就由浅入深,层层推进,用一个函数来解决所有 nSum 类型的问题。
[leetcode1](1. 两数之和 - 力扣(LeetCode) (leetcode-cn.com))
力扣上的 twoSum 问题,题目要求返回的是索引,这里我来编一道 twoSum 题目,不要返回索引,返回元素的值:
如果假设输入一个数组 nums 和一个目标和 target,请你返回 nums 中能够凑出 target 的两个元素的值,比如输入 nums = [5,3,1,6], target = 9,那么算法返回两个元素 [3,6]。可以假设只有且仅有一对儿元素可以凑出 target。
我们可以先对 nums 排序,然后利用前文「双指针技巧汇总」写过的左右双指针技巧,从两端相向而行就行了:
1 | vector<int> twoSum(vector<int>& nums, int target) { |
这样就可以解决这个问题,不过我们要继续魔改题目,把这个题目变得更泛化,更困难一点:
nums 中可能有多对儿元素之和都等于 target,请你的算法返回所有和为 target 的元素对儿,其中不能出现重复。
函数签名如下:
1 | vector<vector<int>> twoSumTarget(vector<int>& nums, int target); |
比如说输入为 nums = [1,3,1,2,2,3], target = 4,那么算法返回的结果就是:[[1,3],[2,2]]。
对于修改后的问题,关键难点是现在可能有多个和为 target 的数对儿,还不能重复,比如上述例子中 [1,3] 和 [3,1] 就算重复,只能算一次。
首先,基本思路肯定还是排序加双指针:
1 | vector<vector<int>> twoSumTarget(vector<int>& nums, int target { |
但是,这样实现会造成重复的结果,比如说 nums = [1,1,1,2,2,3,3], target = 4,得到的结果中 [1,3] 肯定会重复。
出问题的地方在于 sum == target 条件的 if 分支,当给 res 加入一次结果后,lo 和 hi 不应该改变 1 的同时,还应该跳过所有重复的元素:
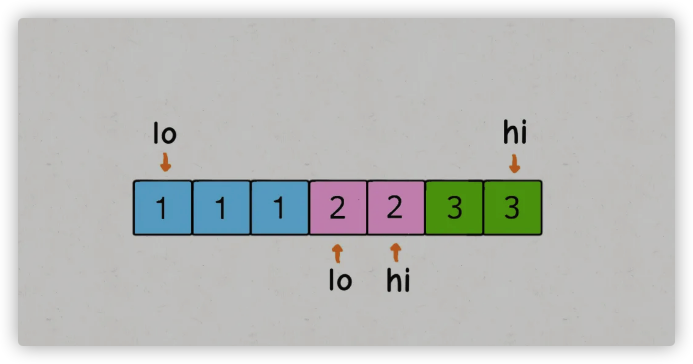
1 | while (lo < hi) { |
这样就可以保证一个答案只被添加一次,重复的结果都会被跳过,可以得到正确的答案。不过,受这个思路的启发,其实前两个 if 分支也是可以做一点效率优化,跳过相同的元素:
1 | vector<vector<int>> twoSumTarget(vector<int>& nums, int target) { |
这样,一个通用化的 twoSum 函数就写出来了,请确保你理解了该算法的逻辑,我们后面解决 3Sum 和 4Sum 的时候会复用这个函数。
这个函数的时间复杂度非常容易看出来,双指针操作的部分虽然有那么多 while 循环,但是时间复杂度还是 O(N),而排序的时间复杂度是 O(NlogN),所以这个函数的时间复杂度是 O(NlogN)。
这是力扣第 15 题「三数之和」:
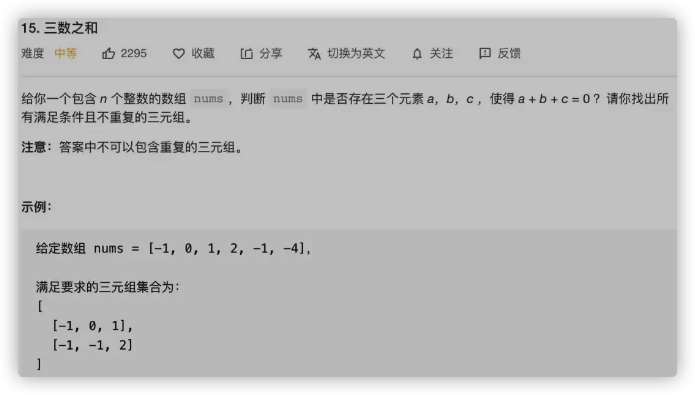
题目就是让我们找 nums 中和为 0 的三个元素,返回所有可能的三元组(triple),函数签名如下:
1 | vector<vector<int>> threeSum(vector<int>& nums); |
这样,我们再泛化一下题目,不要光和为 0 的三元组了,计算和为 target 的三元组吧,同上面的 twoSum 一样,也不允许重复的结果:
1 | vector<vector<int>> threeSum(vector<int>& nums) { |
这个问题怎么解决呢?很简单,穷举呗。现在我们想找和为 target 的三个数字,那么对于第一个数字,可能是什么?nums 中的每一个元素 nums[i] 都有可能!
那么,确定了第一个数字之后,剩下的两个数字可以是什么呢?其实就是和为 target - nums[i] 的两个数字呗,那不就是 twoSum 函数解决的问题么🤔
可以直接写代码了,需要把 twoSum 函数稍作修改即可复用:
1 | /* 从 nums[start] 开始,计算有序数组 |
需要注意的是,类似 twoSum,3Sum 的结果也可能重复,比如输入是 nums = [1,1,1,2,3], target = 6,结果就会重复。
关键点在于,不能让第一个数重复,至于后面的两个数,我们复用的 twoSum 函数会保证它们不重复。所以代码中必须用一个 while 循环来保证 3Sum 中第一个元素不重复。
至此,3Sum 问题就解决了,时间复杂度不难算,排序的复杂度为 O(NlogN),twoSumTarget 函数中的双指针操作为 O(N),threeSumTarget 函数在 for 循环中调用 twoSumTarget 所以总的时间复杂度就是 O(NlogN + N^2) = O(N^2)。
这是力扣第 18 题「四数之和」:

函数签名如下:
1 | vector<vector<int>> fourSum(vector<int>& nums, int target); |
都到这份上了,4Sum 完全就可以用相同的思路:穷举第一个数字,然后调用 3Sum 函数计算剩下三个数,最后组合出和为 target 的四元组。
1 | vector<vector<int>> fourSum(vector<int>& nums, int target) { |
这样,按照相同的套路,4Sum 问题就解决了,时间复杂度的分析和之前类似,for 循环中调用了 threeSumTarget 函数,所以总的时间复杂度就是 O(N^3)。
在 LeetCode 上,4Sum 就到头了,但是回想刚才写 3Sum 和 4Sum 的过程,实际上是遵循相同的模式的。我相信你只要稍微修改一下 4Sum 的函数就可以复用并解决 5Sum 问题,然后解决 6Sum 问题……
那么,如果我让你求 100Sum 问题,怎么办呢?其实我们可以观察上面这些解法,统一出一个 nSum 函数:
1 | /* 注意:调用这个函数之前一定要先给 nums 排序 */ |
嗯,看起来很长,实际上就是把之前的题目解法合并起来了,n == 2 时是 twoSum 的双指针解法,n > 2 时就是穷举第一个数字,然后递归调用计算 (n-1)Sum,组装答案。
需要注意的是,调用这个 nSum 函数之前一定要先给 nums 数组排序,因为 nSum 是一个递归函数,如果在 nSum 函数里调用排序函数,那么每次递归都会进行没有必要的排序,效率会非常低。
比如说现在我们写 LeetCode 上的 4Sum 问题:
1 | vector<vector<int>> fourSum(vector<int>& nums, int target) { |
再比如 LeetCode 的 3Sum 问题,找 target == 0 的三元组:
1 | vector<vector<int>> threeSum(vector<int>& nums) { |
那么,如果让你计算 100Sum 问题,直接调用这个函数就完事儿了。
不少小伙伴在 macOS Big Sur 或 Monterey 中安装 Parallels Desktop 16/17 之后,都遇到了初始化网络失败,无法连接网络的问题。
我们只要修改两个文件的配置即可:
/Library/Preferences/Parallels/dispatcher.desktop.xml/Library/Preferences/Parallels/network.desktop.xml
可以通过 Finder 的前往文件夹功能直达:
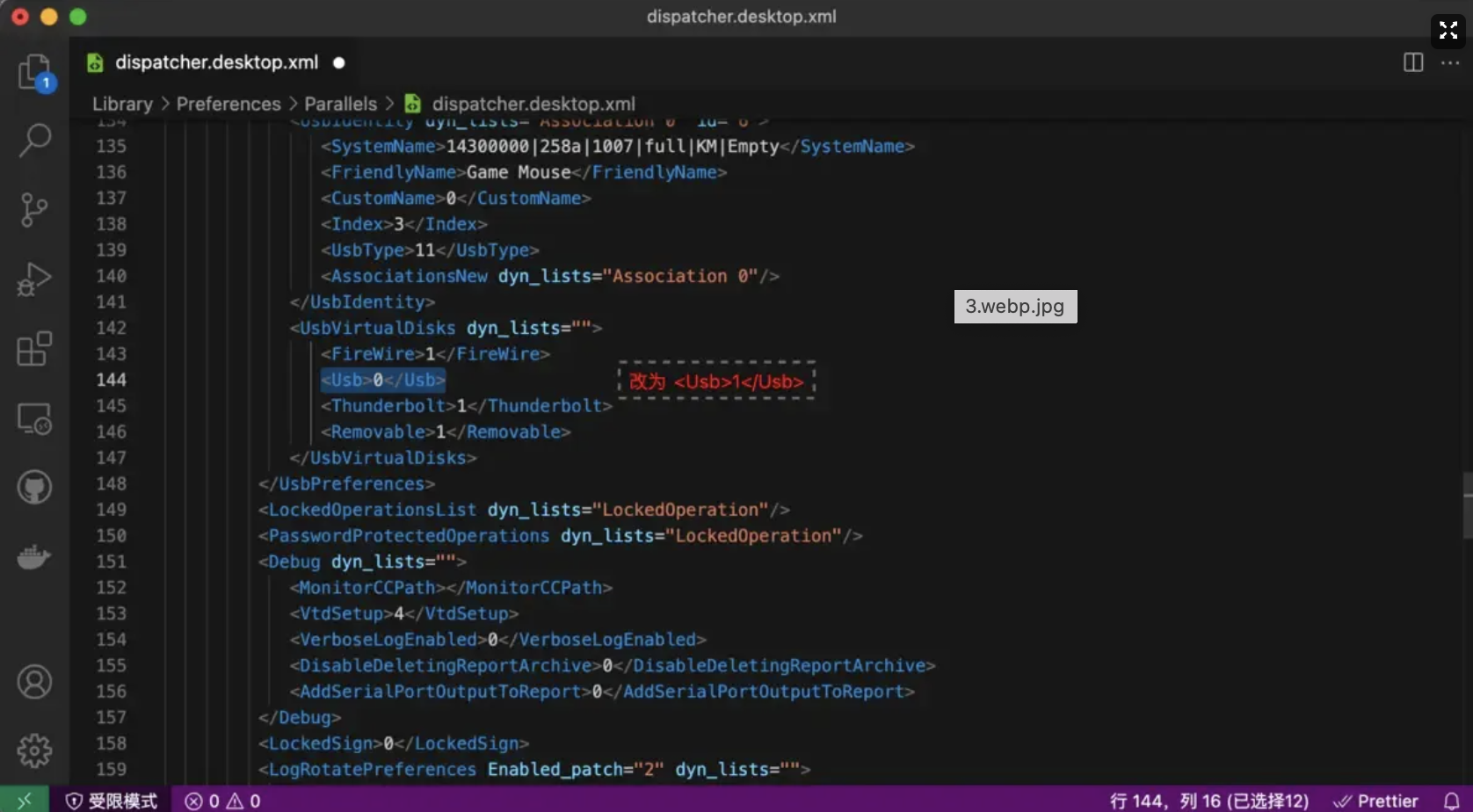
dispatcher.desktop.xml 文件,找到 <Usb>0</Usb>,修改为 <Usb>1</Usb> 并保存。另外,有些小白朋友可能按截图中的行号来找,这是不对的。可通过 ⌘ + F 键,然后输入关键词,来快速定位。
network.desktop.xml 文件,找到 <UseKextless>1</UseKextless> 或 <UseKextless>-1</UseKextless>,修改为 <UseKextless>0</UseKextless> 并保存。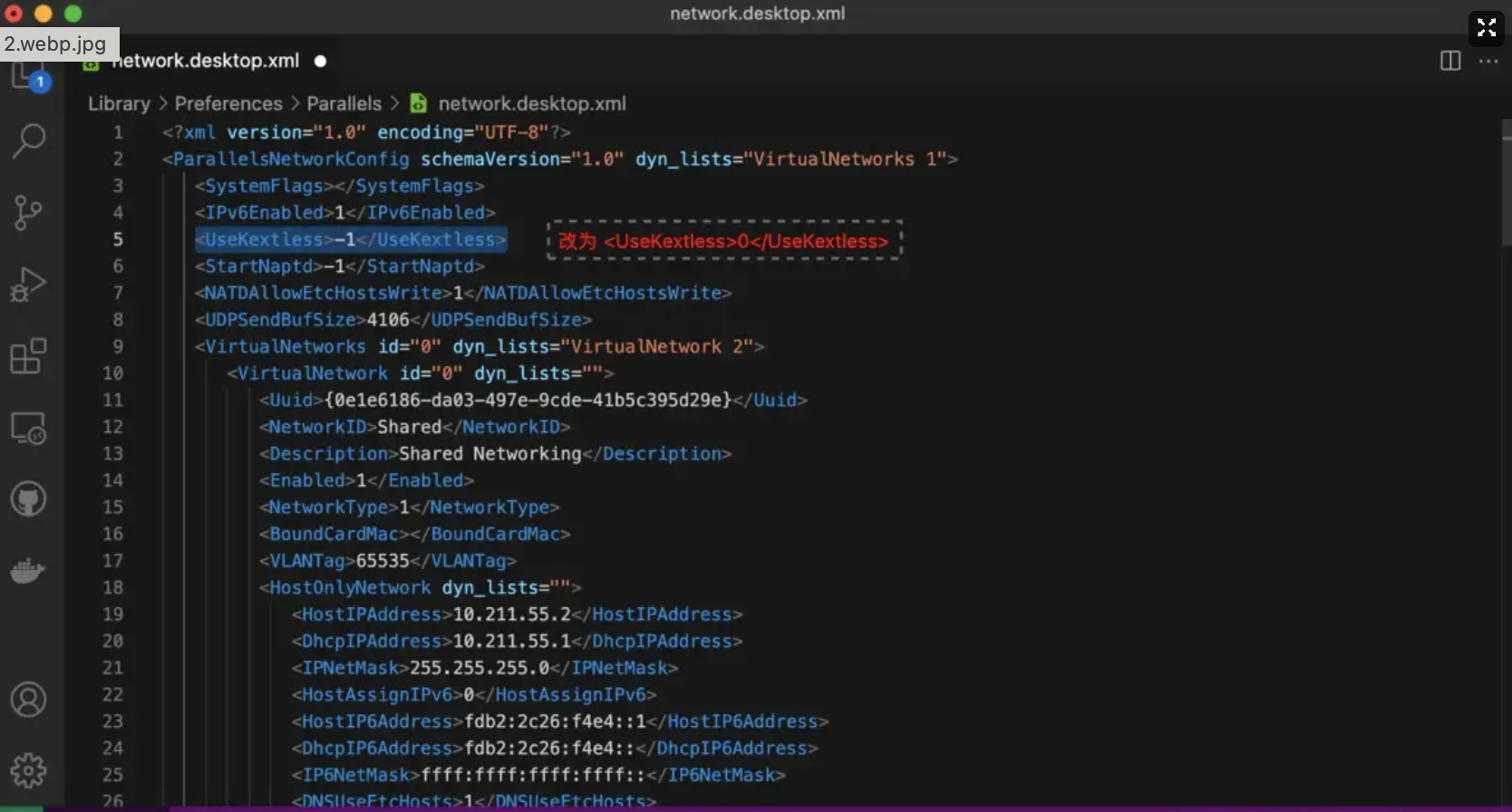
如果找不到 <UseKextless>1</UseKextless> 或 <UseKextless>-1</UseKextless>,那么需要新增一行。
1 | <ParallelsNetworkConfig schemaVersion="1.0" dyn_lists="VirtualNetworks 1"> |
该文件是holer-server项目的主要入口文件。主要作用是启动Holer服务器,并且设置服务器的启动参数和端口。文件中的关键部分包括:
@SpringBootApplication注解来指定该类是Spring Boot应用的入口。@EnableScheduling注解来启用定时任务的支持。main方法是应用程序的入口点,通过SpringApplication.run(HolerApp.class, args)来启动Spring Boot应用程序。ServerUtil.property(ServerConst.SERVER_PORT)获取服务器端口。ServerContainer.getContainer().start()启动ServerContainer实例。该文件主要负责启动Holer服务器并初始化相关配置,然后启动ServerContainer来处理请求。
该程序文件是一个Java类文件,位于holer-server/src/main/java/org/holer/server/handler/ExceptHandler.java。该文件定义了一个异常处理器类ExceptHandler,用于处理不同类型的异常。
该类使用@RestControllerAdvice注解标记为一个全局异常处理类,可以处理控制器中抛出的异常。
在该类中,定义了三个异常处理方法:
通过这些异常处理方法,程序可以在发生异常时进行捕获、处理和返回错误信息,提高系统的可靠性和可维护性。
该文件是holer项目中的一个Java源代码文件,路径为holer-server/src/main/java/org/holer/server/handler/ExtraClientHandler.java。它是一个Netty的事件处理器类,继承自SimpleChannelInboundHandler
这个程序文件是DataHandler.java,它位于holer-server/src/main/java/org/holer/server/handler路径下。
该文件是一个Java类,它是一个Netty的ChannelDuplexHandler的子类。它实现了channelRead、write、channelActive和channelInactive方法。
channelRead方法在读取数据后会更新DataCollector对象中的统计信息,并将消息传递给下一个处理器。write方法在写入数据后会更新DataCollector对象中的统计信息,并继续执行后续的写操作。channelActive方法在连接激活时会增加DataCollector对象中的连接数。channelInactive方法在连接失效时会减少DataCollector对象中的连接数。
该类的主要功能是通过DataCollector收集和统计连接的读写数据量,并跟踪连接数。
该文件是holer-server项目中的一个处理程序类,用于处理服务器收到的消息。主要包括以下几个方法:
该类主要功能是根据接收到的消息类型执行相应的操作,如认证、连接、断开连接和数据传输等。
该文件是一个Java类文件,位于holer-server/src/main/java/org/holer/server/init/目录下。它是一个netty的服务器初始化类,继承了ChannelInitializer
这是一个名为ExtraClientInitializer.java的文件,位于holer-server/src/main/java/org/holer/server/init/目录下。这个文件是一个Netty的ChannelInitializer子类,用来初始化SocketChannel的管道。
在initChannel方法中,会依次向管道添加一个DataHandler和一个ExtraClientHandler,用于处理数据和额外的客户端请求。
这是一个名为H2Function.java的Java程序文件,位于holer-server/src/main/java/org/holer/server/h2目录下。它是一个H2数据库函数类,包含了一个名为unixTimeStamp的静态方法,参数为一个Timestamp对象,返回一个整数类型结果。该方法将给定的Timestamp对象转换为Unix时间戳。
这是一个名为DataCollector的Java类,它位于org.holer.server.util包中。该类用于收集和管理数据,并提供方法来访问和操作收集到的数据。
该类包含以下成员变量:
该类包含以下方法:
总体而言,该类用于收集和统计与端口相关的数据,并提供了访问和操作这些数据的方法。
这个程序文件是一个名为ServerUtil的工具类。它包含了一些静态方法和实例方法,用来提供服务器相关的实用功能。这个类使用了一些第三方库,如Jackson、Gson和OkHttp,还依赖了一些其他的类和接口。它还被声明为一个Spring的组件(Component),可以被自动装配到其他类中使用。整个文件包括了一些公共方法,如初始化方法、获取服务方法、验证方法、写方法等。这些方法用来处理各种服务器相关的功能,如用户验证、生成随机ID、验证许可证、获取总端口数量等。
该文件是一个名为ServerMgr的Java类,主要包含了一些静态变量和静态方法。其中静态变量包括bindChannels、holerChannels、trialClients、extraClientId等Map类型的变量,以及webServerPort、serverDomain、serverHost、serverPort、proxyContent等一些基本类型的变量。静态方法包括isSslServerEnable、getSslServerHost、getSslServerPort等获取静态变量值的方法,以及initCfg、initHoler、saveClient、savePort等一些用于初始化配置和保存数据的方法。此外,还有一些其他的辅助方法,如bind、unbind、deleteProxy等。整体来说,该类是一个服务器管理工具类,用于管理服务器的状态、配置和通讯等。
这是一个名为SchedulerConfig的Java类文件,位于holer-server/src/main/java/org/holer/server/config/路径下。该类使用了Spring框架的注解@Configuration,用于标识为配置类。实现了SchedulingConfigurer接口,用于自定义任务调度器的配置。
在configureTasks方法中,创建了一个ThreadPoolTaskScheduler对象,并进行了一些配置,如设置线程池大小为5,线程名前缀为”Holer-Task-“。然后调用initialize方法进行初始化。最后通过registrar.setTaskScheduler(taskScheduler)方法将配置好的任务调度器设置到ScheduledTaskRegistrar对象中。
该配置类的主要作用是创建和配置一个自定义的任务调度器,并将其应用于任务注册器中,以便在Spring应用程序中实现定时任务调度。
这是一个名为HolerWebConfig.java的配置文件,位于org.holer.server.config包中。它实现了WebMvcConfigurer接口,并覆盖了addInterceptors方法。该方法通过向注册表添加拦截器来配置拦截器。文件中还有两个注入的拦截器实例:apiInterceptor和viewInterceptor。addInterceptors方法使用这两个拦截器,并为它们指定了拦截路径。apiInterceptor拦截/api/**路径,viewInterceptor拦截/view/**路径。
这个文件是”Holer Server”项目中的一个配置文件,它用于配置跨域资源共享(CORS)功能。该文件定义了一个 CorsConfig 类,被注解为@Configuration,表示这是一个Spring应用程序的配置类。在这个类中,有一个@Bean方法,它创建了一个CorsFilter对象,并返回它。CorsFilter是Spring框架中的一个过滤器,用于处理跨域请求。在这个方法中,我们创建了一个CorsConfiguration对象,并设置了一些允许访问的来源、头部和方法。然后,创建了一个UrlBasedCorsConfigurationSource对象,将CorsConfiguration配置应用到所有的URL路径上。最后,将UrlBasedCorsConfigurationSource对象传递给CorsFilter构造函数,创建CorsFilter对象并返回。这样,当请求到达服务器时,CorsFilter将会根据CorsConfiguration的设置来处理跨域请求。
该程序文件名为HolerWorker.java,位于org.holer.server.timer包下。这个文件是一个定时任务类,包含了三个定时任务方法cleanExpiredData()、closeHoler()和setDomain()。cleanExpiredData()方法用于清除过期的数据;closeHoler()方法用于关闭Holer;setDomain()方法用于设置域名。这个类使用了Spring的Scheduled注解来指定定时执行的时间间隔。文件中还引入了一些其他的类和工具类,并且使用了日志输出。
该程序文件是Holer服务器的主要容器类,用于启动和停止服务器。以下是该文件的关键要点:
总结:ServerContainer类是Holer服务器的核心容器类,负责处理服务器的启动和停止。它使用Netty库提供的API实现了一个基本的服务器框架,并通过单例模式确保全局唯一性。
该程序文件是一个Java枚举类,命名为HolerType。该枚举类定义了一些常见的网络协议类型,如HTTP、HTTPS、SSH等。每个协议类型都有一个与之对应的字符串类型(type属性),并提供了一个value方法用于获取该字符串类型。此外,该枚举类还提供了一个isValid方法,用于检查给定的字符串是否为有效的协议类型。
该文件是一个Java类文件,位于org.holer.server.constant包下。该类中定义了一系列用于服务器的常量字段。
其中一些常量的含义如下:
这是一个名为HolerCode.java的文件,位于src/main/java/org/holer/server/constant/路径下。这个文件定义了一个枚举类型HolerCode,包含了许多常量成员。每个常量成员都有一个对应的整数值,并通过构造函数进行初始化。HolerCode还提供了两个方法:value()用于获取常量成员的整数值,message()用于获取常量成员对应的消息文本。
这个程序文件名为HolerLicense.java,位于org.holer.server.model包下的src/main/java目录中。它是一个Java类文件,用于定义HolerLicense对象的模型。
这个类使用了lombok库的@Data注解,自动生成了getter和setter方法。它实现了Serializable接口,表示可以被序列化。
HolerLicense类有以下成员变量:
这个类的作用是表示一个Holer许可证对象,并提供相关的属性和方法。这个类可用于在Holer服务器中存储和处理许可证信息。
这个文件是一个Java类文件,文件名为HolerPort.java。该类位于org.holer.server.model包。它是一个实体类,用于映射数据库表holer_port。该类定义了一些属性和方法,用于描述Holer服务器的端口信息,包括访问密钥(accessKey)、端口号(portNum)、服务器地址(server)、域名(domain)、Holer类型(type)等。该类还提供了一些辅助方法,用于计算有效天数(validDay)、过期时间(expireAt)、创建时间(createAt)和获取IP地址(inetAddr)。
该文件是一个Java类文件,位于项目的holer-server模块中的org.holer.server.model包下。该类是一个数据模型类,用于表示Holer的状态。
该类使用了lombok库的@Data注解,自动生成了属性的getter、setter方法、equals()、hashCode()、toString()等方法。
HolerStatus类有以下属性:
这个程序文件是holer-server项目的一部分。它定义了一个HolerClient类,在数据库表holer_client中映射了多个属性。该类实现了Serializable接口,并使用lombok库的@Data注解自动生成了getter和setter方法。HoldeClient类具有以下属性:clientId、name、accessKey、enabled、status、onlineAt、channel、ports。其中,clientId是自动生成的唯一标识符,name是一个非空且符合邮箱格式的字符串,accessKey是一个字符串,enabled是一个布尔值,status是一个整数。onlineAt和channel属性被标记为@Transient和@JsonIgnore,并不会在数据库中存储,而是用于临时存储数据。ports属性是一个HolerPort对象的列表。此外,类还包括一些方法,如publicPorts方法返回一个整数列表,并遍历ports列表以获取端口号。
该程序文件是一个Java类文件,名为HolerUser.java。该类位于org.holer.server.model包下。该类使用了Lombok库的@Data注解,以自动生成getter和setter方法。该类是一个实体类,使用了javax.persistence注解进行标注,以与数据库表holer_user进行映射。该类实现了Serializable接口,以支持序列化。类中包含了字段userId、name、password和token,分别表示用户id、用户名、密码和令牌。其中name字段使用了javax.validation.constraints注解进行验证,要求值不能为空且长度在3到128个字符之间;password字段也使用了javax.validation.constraints注解进行验证,要求值不能为空且长度在6到128个字符之间。
这个程序文件是holer-server项目中的一个Java类文件,文件名是HolerData.java。这个类是一个POJO类,用于表示Holer服务器中的数据信息。它实现了java.io.Serializable接口,以便在网络传输和持久化存储过程中进行序列化和反序列化。
这个类有以下属性:
这个类使用了Lombok库中的@Data注解,自动生成了属性的getter和setter方法、toString方法等。
该源代码文件是一个名为HolerResult的Java类,位于org.holer.server.model包中。它具有以下属性和方法:
属性:
构造方法:
重要方法:
使用注解:
这个程序文件是holer-server项目中的一个Java类文件,文件名为HolerException.java。该类继承了RuntimeException类。它定义了一个HolerException异常,主要用于包装HolerCode和HolerStatus,提供了一些方法来获取异常的状态信息。该文件主要用于处理holer-server项目中的异常情况。
这个程序文件是holer-server项目中的一个Java类文件,文件名为HolerReport.java。它位于holer-server/src/main/java/org/holer/server/model/目录下。
该类使用了Lombok的@Data注解,自动生成了getter和setter方法。它实现了Serializable接口,并包含以下属性:
这个类用于表示Holer服务器的报告数据。
这是一个Java源代码文件,文件名为HolerApi.java。该文件包含了一个名为HolerApi的类,该类实现了Serializable接口,并使用了Lombok的@Data注解。该类具有以下属性:uri(String类型)、method(String类型)、free(boolean类型)。这些属性被自动生成了getter和setter方法。此外,该类还定义了一个名为serialVersionUID的静态长整型常量。
这个程序文件是holler-server项目中的一个Java类文件,位于路径org.holler.server.model中。它实现了Serializable接口并使用了Lombok库中的@Data注解。该类具有以下成员变量:client,类型为HolerClient;ports,类型为Map<Integer, HolerPort>。这个类用于表示Holler服务器中的通道。
这个文件是 DBUserService.java,它位于 holer-server/src/main/java/org/holer/server/db 目录下。这是一个接口文件,定义了对数据库用户表进行操作的方法。它继承了 JpaRepository 接口,泛型参数为 HolerUser 和 Long。这个接口定义了以下两个方法:
findByNameAndPassword 方法,根据用户名和密码查找用户。findByToken 方法,根据令牌查找用户。这是一个名为DBPortService.java的Java源代码文件,属于holer-server/src/main/java/org/holer/server/db目录。该文件定义了一个接口DBPortService,继承自JpaRepository<HolerPort, Long>。接口中定义了一些方法用于对HolerPort对象进行数据库操作,如根据accessKey、portNum、domain进行查询,根据accessKey进行删除,统计满足条件的记录数等。还有两个使用原生查询语句的方法,分别用于统计已过期的端口数量和活跃的端口数量。
这是一个名为DBClientService.java的Java文件,位于holer-server/src/main/java/org/holer/server/db目录中。该文件是一个接口文件,定义了一个名为DBClientService的接口。该接口继承了JpaRepository接口,并指定了泛型参数为HolerClient和Long。
DBClientService接口中定义了一些方法:
这个程序文件是一个名为ApiInterceptor.java的拦截器类,用于处理HTTP请求之前的拦截操作。它实现了Spring框架的HandlerInterceptor接口。在preHandle方法中,它会先检查请求中的令牌是否有效,如果令牌无效,则会返回一个包含错误代码的HolreResult对象,并返回false表示请求已被拦截。如果令牌有效,则返回true表示继续处理该请求。该拦截器被标记为@Component,表示它是一个由Spring管理的组件。
这个程序文件是一个名为ViewInterceptor的类,实现了HandlerInterceptor接口。它位于org.holer.server.interceptor包中,用于拦截请求并进行处理。
该类包含一个方法preHandle,用于处理请求之前的操作。在该方法中,它首先获取当前请求的HttpSession对象,并检查是否为null。如果为null,则通过HttpServletResponse对象将请求重定向到/login.html页面,并返回false表示请求不被继续处理。
然后,它从session中获取名为”HOLER-AUTH-TOKEN”的属性,并检查是否为null。如果为null,则通过HttpServletResponse对象将请求重定向到/login.html页面,并返回false表示请求不被继续处理。
最后,如果以上条件都不满足,它返回true,表示请求可以继续处理。
该类还使用了@Component注解,表示它是一个Spring组件,可以被Spring容器进行管理和注入。
这是一个名为RESTClientService.java的Java文件。它位于holer-server/src/main/java/org/holer/server/rest目录下。
这个文件定义了一个名为RESTClientService的类,该类是一个RestController,用于处理关于Holer客户端的REST API请求。它包含了一些常用的注解,如@Validated、@CrossOrigin、@RestController和@RequestMapping。
这个类依赖于DBClientService和DBPortService这两个数据库服务,并通过@Autowired注解进行自动注入。
它包含了一些处理REST API请求的方法,包括findAll、findByAccessKey、getReport、addClient、updateClient和deleteById。
这些方法使用了@GetMapping、@PostMapping、@PutMapping和@DeleteMapping注解,分别处理对应的HTTP请求方法。这些方法主要负责查询数据库的内容,并根据请求返回相应的结果。
整体而言,这个文件实现了一个RESTful API,用于处理关于Holer客户端的请求,并与数据库进行交互。
这个文件是一个名为RESTUserService的Java类,位于holer-server/src/main/java/org/holer/server/rest/目录下。该类提供了处理用户登录和退出功能的RESTful接口。其中,login方法处理用户登录请求,logout方法处理用户退出请求。该类依赖于DBUserService类实现数据库访问和操作。该文件还包含了一些注解用于配置接口路由和跨域访问。
该程序文件为一个RESTful风格的端口服务类,用于处理和管理端口的增删改查操作。
该类包含以下主要功能:
该类依赖于其他类与服务:
该类还使用了一些常量和模型类,例如HolerCode、HolerType、HolerClient和HolerPort,用于表示不同的状态码、端口类型和客户端/端口模型。
整体来说,该程序文件是一个处理端口管理的RESTful服务类,通过对GET、POST、PUT和DELETE请求的处理,实现了对端口的增删改查功能。
这个文件是一个 Maven 的 POM(Project Object Model)文件,用于构建 holser-server 项目。它定义了项目的基本信息,依赖项和构建配置。项目使用 Spring Boot 框架,主要依赖包括 Spring Boot Starter Web、Spring Boot Starter Data JPA、MySQL 连接器、Lombok、Commons Lang、Commons Collections、Commons BeanUtils、Commons Codec、JavaMail、Netty、OkHttp、H2 数据库和 Spring Boot Starter Actuator。构建配置包括 Maven 编译器插件和 Spring Boot Maven 插件。
这个程序文件是一个XML配置文件,用于指定Holer Server项目的打包和组装方式。
它包含以下内容:
<includeBaseDirectory>:指定在生成的tar.gz压缩包中是否包含与项目名相同的根目录。<dependencySets>:定义依赖项集合,其中包括将本项目添加到依赖文件夹下的设置。<outputDirectory>:指定将来自依赖项集合的运行时依赖包放在哪个目录下。<fileSets>:定义文件集合,其中包括将src/main/bin目录下的文件复制到根目录下的设置。简而言之,这个文件描述了如何组装和打包Holer Server项目,包括将项目本身和运行时依赖项一起打包,并将特定文件复制到特定目录。
| 文件路径 | 文件功能 |
|---|---|
| holer-server/src/main/java/org/holer/server/ HolerApp.java |
Holer服务器的主要入口文件,用于启动Holer服务器。 |
| holer-server/src/main/java/org/holer/server/ handler/ExceptHandler.java |
异常处理器类,处理控制器中抛出的异常。 |
| holer-server/src/main/java/org/holer/server/ handler/ExtraClientHandler.java |
处理客户端连接和数据传输的Netty事件处理器类。 |
| holer-server/src/main/java/org/holer/server/ handler/DataHandler.java |
数据处理器类,处理接收到的消息。 |
| holer-server/src/main/java/org/holer/server/ handler/ServerHandler.java |
服务器处理器类,处理服务器接收到的消息。 |
| holer-server/src/main/java/org/holer/server/ init/ServerInitializer.java |
服务器初始化类,用于初始化服务器管道。 |
| holer-server/src/main/java/org/holer/server/ init/ExtraClientInitializer.java |
额外的客户端初始化类,用于初始化额外的客户端管道。 |
| holer-server/src/main/java/org/holer/server/ h2/H2Function.java |
H2数据库函数类,包含了Unix时间戳转换的方法。 |
| holer-server/src/main/java/org/holer/server/ util/DataCollector.java |
数据收集器类,用于收集和管理数据。 |
| holer-server/src/main/java/org/holer/server/ util/ServerUtil.java |
服务器相关的实用工具类,提供一些公共方法和功能。 |
| holer-server/src/main/java/org/holer/server/ util/ServerMgr.java |
服务器管理工具类,提供管理服务器相关的静态方法和变量。 |
| holer-server/src/main/java/org/holer/server/ config/SchedulerConfig.java |
任务调度器的配置类,用于自定义任务调度器的配置。 |
| holer-server/src/main/java/org/holer/server/ config/HolerWebConfig.java |
Web配置类,用于配置拦截器和其他Web相关配置。 |
| holer-server/src/main/java/org/holer/server/ config/CorsConfig.java |
跨域资源共享(CORS)配置类,用于配置跨域请求处理。 |
| holer-server/src/main/java/org/holer/server/ timer/HolerWorker.java |
定时任务类,包含定时清除数据和关闭Holer的方法。 |
| holer-server/src/main/java/org/holer/server/ container/ServerContainer.java |
服务器容器类,用于启动和停止服务器。 |
整体而言,该组程序文件实现了一个Holer服务器,用于处理客户端连接、数据传输、异常处理、数据收集与管理、定时任务调度等功能。
概括这些文件的整体功能:这些文件的整体功能是实现一个Holer服务器,包括启动服务器、处理客户端连接和数据传输、处理异常、初始化服务器管道、使用H2数据库函数、收集和管理数据、提供服务器相关的实用工具和管理工具、配置任务调度器、配置Web和CORS、执行定时任务,以及启动和停止服务器。
1 | flowchart LR |
| 文件名 | 功能 |
|---|---|
| HolerType.java | 定义了Holer服务器支持的网络协议类型 |
| ServerConst.java | 定义了服务器相关的常量字段 |
| HolerCode.java | 定义了Holer服务器的状态码和消息文本 |
| HolerLicense.java | 定义了Holer服务器的许可证信息模型 |
| HolerPort.java | 定义了Holer服务器的端口信息模型 |
| HolerStatus.java | 定义了Holer服务器的状态信息模型 |
| HolerClient.java | 定义了Holer服务器的客户端信息模型 |
| HolerUser.java | 定义了Holer服务器的用户信息模型 |
| HolerData.java | 定义了Holer服务器的数据信息模型 |
| HolerResult.java | 定义了Holer服务器的通用结果封装模型 |
| HolerException.java | 定义了Holer服务器的异常类 |
| HolerReport.java | 定义了Holer服务器的报告信息模型 |
| HolerApi.java | 定义了Holer服务器的API接口信息模型 |
| HolerChannel.java | 定义了Holer服务器的通道信息模型 |
| DBUserService.java | 定义了对用户表进行数据库操作的接口 |
| DBPortService.java | 定义了对端口表进行数据库操作的接口 |
以上这些文件属于Holer服务器项目的不同模块,功能涵盖了启动服务器、连接和数据传输、异常处理、数据管理、结果封装、API接口定义和数据库操作等。综合来说,该程序的整体功能是实现一个Holer服务器,用于将本地服务映射到公网,实现内网穿透功能。
概括这些文件的整体功能:这些文件的整体功能是实现一个Holer服务器,包括定义服务器常量字段、状态码和消息文本、许可证信息、端口信息、状态信息、客户端信息、用户信息、数据信息、结果封装、异常处理、报告信息、API接口信息和通道信息模型,以及对用户表和端口表进行数据库操作。
1 | flowchart LR |
| 文件路径 | 文件功能描述 |
|---|---|
| holer-server/src/main/java/org/holer/server/ db/DBClientService.java |
定义数据库客户端服务接口,提供对Holer客户端的基本操作 |
| holer-server/src/main/java/org/holer/server/ interceptor/ApiInterceptor.java |
处理HTTP请求前的拦截操作,检查令牌是否有效 |
| holer-server/src/main/java/org/holer/server/ interceptor/ViewInterceptor.java |
处理请求前的拦截操作,检查会话和令牌是否有效 |
| holer-server/src/main/java/org/holer/server/ rest/RESTClientService.java |
提供Holer客户端的RESTful API接口,包括查询、新增、更新和删除 |
| holer-server/src/main/java/org/holer/server/ rest/RESTUserService.java |
提供用户登录和退出的RESTful API接口 |
| holer-server/src/main/java/org/holer/server/ rest/RESTPortService.java |
提供端口管理的RESTful API接口,包括查询、新增、更新和删除 |
| holer-server/pom.xml | Maven项目配置文件,定义项目的依赖和构建配置 |
| holer-server/assembly.xml | 组装和打包Holer Server项目的配置文件 |
总体来说,程序的整体功能是实现Holer服务器,包括数据库服务、拦截器、RESTful API接口和打包部署配置。
概括这些文件的整体功能:这些文件的整体功能是实现Holer服务器,包括定义数据库操作接口、拦截器类、RESTful API接口和项目构建、打包、部署配置。
1 | flowchart LR |
平时开发过程中遇到的一些问题,我都会整理到文档中。有些感觉不错的,会二次整理成文章发布到我的博客中。但是有些文章如果存在隐私内容,或者不打算公开的话,就不能放在博客中了。
我的博客是使用 Hexo 来搭建的,并不能设置某些文章不可见。但如果不在电脑旁或者出门没有带电脑又想要查看一下之前记录的内容,就很不方便了。
我也尝试在 github 上去找一些可以设置账户的开源的博客框架,但测试过一些后发现并没有符合自己需求的,而自己开发却没有时间。
思来想去,就想看看有没有插件能够实现 Hexo 博客的加密操作。最终让我找到了一款名为 Hexo-Blog-Encrypt 的插件。
为了防止以下的修改可能出现版本差异,这里我先声明我使用的 Hexo 版本信息:
1 | hexo: 4.2.1 |
1 | npm install --save hexo-blog-encrypt |
该插件的使用也很方便,这里我仅作简单介绍,详细的可以查看官方文档。 D0n9X1n/hexo-blog-encrypt: Yet, just another hexo plugin for security.
要为一篇文章添加密码查看功能,只需要在文章信息头部添加 password 字段即可:
1 | --- |
分别为每篇文章设置密码,虽然很灵活,但是配置或者修改起来非常麻烦。为此,可以通过设置统一配置来实现全局加密。
通过添加指定 tag 的方式,可以为所有需要加密的文章添加统一加密操作。只需要在需要加密的文章中,添加设置的 tag值 即可。
在Hexo主配置文件 _config.yml 中添加如下配置:
1 | # Security |
之后,需要清除缓存后重新生成 hexo clean && hexo s -g。
其中的 tag 部分:
1 | tags: |
表示当在文章中指定了 private 这个 tag 后,该文章就会自动加密并使用对应的值 hello 作为密码,输入密码后才可查看。
相应的文章头部设置:
1 | --- |
可能有这样的情况,属于 private 标签下的某篇文章在一段时间内想要开放访问。如果在描述中加上密码提示: 当前文章密码为xxx,请输入密码后查看 ,来让用户每次查看时都要先输入密码后再查看,这样的操作又会给访客带来不便。
这时可以单独设置允许某篇文章不设置密码。
只需要在使用 加密tag 的前提下,结合 password 来实现即可。在博客文章的头部添加 password 并设置为 "" 就能取消当前文章的 Tag 加密。
相应的设置示例如下:
1 | --- |
在全局加密配置下,我们可以通过设置多个 加密tag 来为多篇不同类型的文章设置相同的查看密码:
1 | tags: |
那么可能有这样的场景:
属于 private 标签下的某篇文章想要设置成不一样的密码,防止用户恶意通过一个密码来查看同标签下的所有文章。此时,仍可以通过 password 参数来实现:
1 | --- |
说明:
该文章通过tag值 private 做了加密,按说密码应该为 hello ,但是又在信息头中设置了 password ,因为配置的优先级是 文章信息头 > 按标签加密,所以最后的密码为 buyiyang 。
在为某些文章设置了 加密后查看 之后,不经意间发现这些文章的目录在解密后却不显示了。
从插件的 github issues 中我找到了相关的讨论:
原因:
加密的时候,
post.content会变成加密后的串,所以原来的TOC生成逻辑就会针对加密后的内容。
所以这边我只能把原来的内容存进post.origin字段。
找到文件 themes/next/layout/_macro/sidebar.swig ,编辑如下部分:

插件 hexo-blog-encrypt 对文章内容进行加密后,会将原始文章内容保存到字段 origin 中,当生成 TOC 时,我们可以通过 page.origin 来得到原始内容,生成文章目录。
相应的代码为:
1 | <aside class="sidebar"> |
修改完成后,执行 hexo clean && hexo s -g 并重新预览。
效果如下:

不过,这样的效果貌似不是我想要的。我理想中的效果应该是:
站点概览 部分,不需要看到 文章目录 部分。站点概览 和 文章目录 两部分。而现在加密后的文章未解密之前也可以看到 文章目录 ,虽然该目录不可点击。
当然,如果你不是很介意,那么到这里就可以结束了。如果你和我一样有一些 追求完美的强迫症 的话,我们继续。
查看了 hexo-blog-encrypt 相关的 issues ,我找到了一种 折中 的解决方法。
从 issue Archer主题解密后TOC依旧不显示(已按手册修改) 中我们可以知道:
我们可以在文章加密的前提下,通过将目录部分加入到一个 不可见的div 中来实现 隐藏目录 的效果。在源码中的 hexo-blog-encrypt/lib/hbe.js 部分我们也可以看到,解密后通过设置 id 值为 toc-div 的元素为 display:inline 来控制显示隐藏。
1 | {%- if (page.encrypt) %} |
对文件 themes/next/layout/_macro/sidebar.swig 修改后的代码如下:
1 | <!--noindex--> |
但这种方法并不是完全的加密,而是采用 障眼法 的方式,通过查看html源文件还是可以看到目录内容的,只是不显示罢了。
对于这个问题,hexo-blog-encrypt 插件的作者也作了说明:next 主题内没有 article.ejs 文件【TOC 相关】 · Issue #162 · D0n9X1n/hexo-blog-encrypt
因为该插件中目前只有一个参数 page.encrypt 可以用来判断当前的文章是否进行了 加密处理 ,而不能获知该文章当前是处于 加密后的锁定 状态,还是处于 加密后的解锁 状态。如果再有一个参数结合起来一起处理就好了。
所以,目前只能在解锁前隐藏目录,解锁后再显示目录。但在解锁前目录区域还是会展开,只是没有内容显示罢了。
类似于我的博客文章列表中的 文章置顶 的提示效果,考虑在文章列表中对加密的文章增加类似的 加密 提示信息。
上面对于文章的加密处理,一方面是在 配置文件 中添加的 tag 全局配置,另一方面是在单个 md源文件 中添加的 password 参数。所以我们需要对这两种情况分别做处理。
针对于 password 字段,参考获取其他字段的方法,比如获取标题用 post.title ,获取置顶用 post.top ,那么获取 password 就是 post.password 了。
可以参考我之前添加置顶提示信息的操作,对文件 themes/next/layout/_macro/post.swig 的修改如下:
1 | {# 加密文章添加提示信息-for password #} |
针对于 tag 标签的获取,可以从文件 themes/next/layout/_macro/post.swig 中找到类似的处理方法:
即可以用最简单的 遍历法 来处理:
我们获取到配置文件中设置的所有 加密tag值 ,再找到文章中的 tag标签 。二者一对比,有匹配的项则说明该文章设置了 tag值 加密。
要在 .swig 文件中实现相应的对比逻辑,就需要了解其使用的语法格式。而对于 swig 文件,使用的是 Swig 语法。
Swig是一个非常棒的、类似Django/jinja的node.js模板引擎。
不过看到这个代码库 paularmstrong/swig: Take a swig of the best template engine for JavaScript. 已经 归档 了。
但因为 Swig 是类似于 jinja 的模板引擎,那么我们直接去参考 jinja 的语法就可以了。
获取全局配置中 encrypt.tags 的值:
1 | {%- if (config.encrypt) and (config.encrypt.tags) %} |
在文章列表中获取当前文章包含的 tags 列表:
1 | {%- if post.tags %} |
对于其中展示的文本格式,可以参考已有的 发表于 更新于 这些副标题的格式来实现。
例如:
1 | <span class="post-meta-item"> |
对其进行优化,我们只需要显示提示文字,不需要后面的带下划线部分,最终得到的就是:
1 | <span class="post-meta-item"> |
整合上面的代码,对于文章中包含 password 的文档,通过如下方式来显示:

相应代码:
1 | {# 加密文章添加提示信息-for password #} |
对于文章中包含指定加密 tags 的文档,通过如下方式来显示:

相应代码:
1 | {# 加密文章添加提示信息-for config tags #} |
对于两种都有的文档,我们只需要通过一个 判断 来处理就好了:优先判断文档中的 password 字段。当文档中包含 password 时,就说明是加密文章;否则就去判断配置文件看是否为加密文章。

最后的代码为:
1 | {# 加密文章添加提示信息-for password #} |
稍微不好的一点就是,上面的操作是通过 两个for循环 来处理的,会导致一些性能问题。不过这个操作是在编译过程 hexo g 的时候来处理的,不影响博客浏览,也就可以忽略了。
对于需要显示的图标,可以从网站 Icons | Font Awesome 中获取。
例如,我这里选择的是 锁 的icon图标,得到的代码如下:
1 | <i class="fas fa-lock"></i> |
记得高中时特喜欢看《名侦探柯南》,剧情对逻辑能力有一定考验,看起来还是比较烧脑的。
所以那时堂主就有意识不断提升自己的逻辑思维能力,也发现了自己因为该项能力不足而产生的各种问题。
每天那么多事情,还是不知道从哪里做起,总是手忙脚乱……
公开讲话或展示报告,总表达不出重点,心里特着急……
看书写文也是随心情,真正下笔时,不知道从何下手……
堂主,我有一个疑问想求解答。像《金字塔原理》等这类书籍,看完后感觉想要真正融入实践去运用好难,不知道这是认知问题还是思维习惯的培养或者其他原因呢?
这本书堂主也看了几遍,最后发现,逻辑思维不好,既是思维固化的原因,也是认知以及方法论的问题。
所以,今天给大家分享的这篇文章,能够一定意义上帮助大家解决留言类似问题。
相信我,如果你借鉴文章中的一些方法,逻辑思维会有巨大提升!
01.
沟通框架法
日常沟通中,没有逻辑框架的表达差别,是很明显的。
比如你通知同事开会:
逻辑不清者:
下午3点开会,记得提前10分钟过来开空调到25°,在桌子上摆上景田,总监爱喝;
他下午要来总结月度目标,顺便帮我通知下其他人,在110会议室~
很可能到时候同事忘记通知其他人,晚到了半个小时,你也喝不上怡宝,被总监请去喝茶了……
有逻辑者:
今天下午3点,总监要来110会议室开月会,辛苦你通知下其他人;
再麻烦提前10分钟过来开好25°的空调,摆上总监爱喝的怡宝。
先说总体事项,再说细节,最后搭上同事个人收益。
下面堂主分享3个框架模型,可以作为形成你个人方法论的参考。
1、 工作沟通:STAR模型
这个模型能帮你轻松通过面试、工作汇报。
我们最大的问题,就是不懂如何有逻辑地向领导或面试官,展示自己的优势,以及工作的成果。
明明打好了满肚子的腹稿,一出口就变成了:“额……额……”
这种情况面试官内心独白估计是赶紧打发回去吧。
掌握好STAR模型的工作沟通方法,让你能够非常清楚自己需要表达什么。
S——情境(situation),事情是在什么情况发生的?
T——目标(target),你是如何明确自己的任务?
A——**行动(action)**,根据目标采取什么行动?
R——**结果(result)**,最后结果如何,个人有什么收获?
不需太啰嗦,每个点说1-2句即可。
举个面试例子,一个想去新媒体公司的大学生,自我介绍时可以这么说:
在校期间我是学校官方微信号的负责人(s);
我的主要任务是官方校园动态、和学生有趣槽点的推送,以及指导新社员(T);
在2年内我参考了近100个高校官微的运营模式,同时业余参加新媒体课程、请教老师(A);
最后总结了一套自己的写作模式和运营模式,经过验证,官微阅读量从6k上升到1.5w,自己拥有了5k粉丝量的个人账号。(R)
不到一分钟的时间,有条理地表达自己的工作成果,充分展现自己的个人能力。
2、 情感沟通:FOSSA模型
很多争吵都是因为情绪表达不到位,加剧了矛盾火力,越吵越凶。之后即便你有情绪,那么不妨在沟通之前,想想下面几个问题。
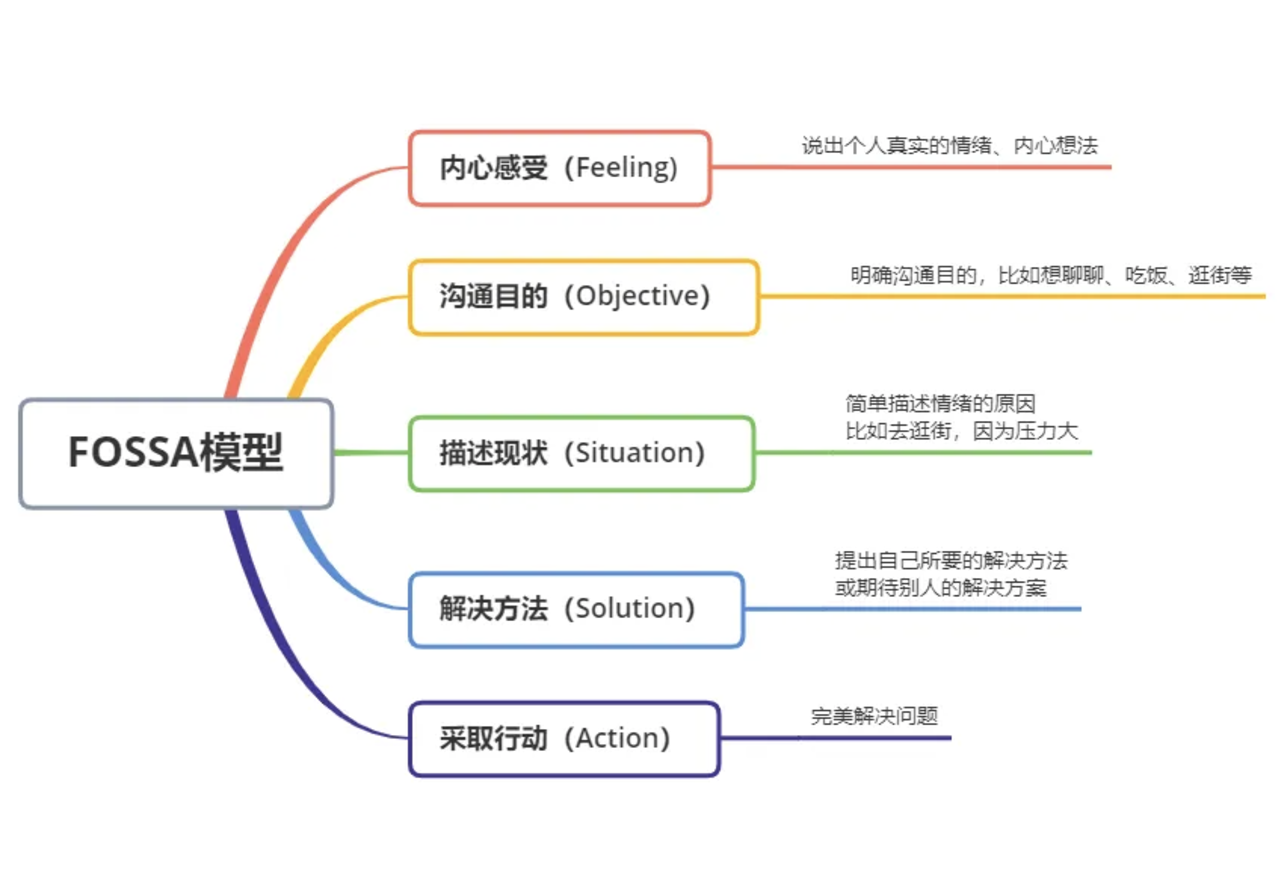
另外在我们的人生道路上,永远不要发生无谓的冲突,你要清楚自己是一块宝石,犯不着和石头硬碰硬。
如果碰到烂人尽量大事化小,小事化了,实在触及到底线,再适当予以反击。
3、 阅读拆解:SQ3R模型
有逻辑地进行阅读,能大大提高你的读书吸收效率。
大多人都是拿本书就看,看完一头雾水,讨论起书中内容开始蒙了。
用SQ3R阅读模型框架,能轻松帮你理清思路,用最短的时间得到更多的知识点。
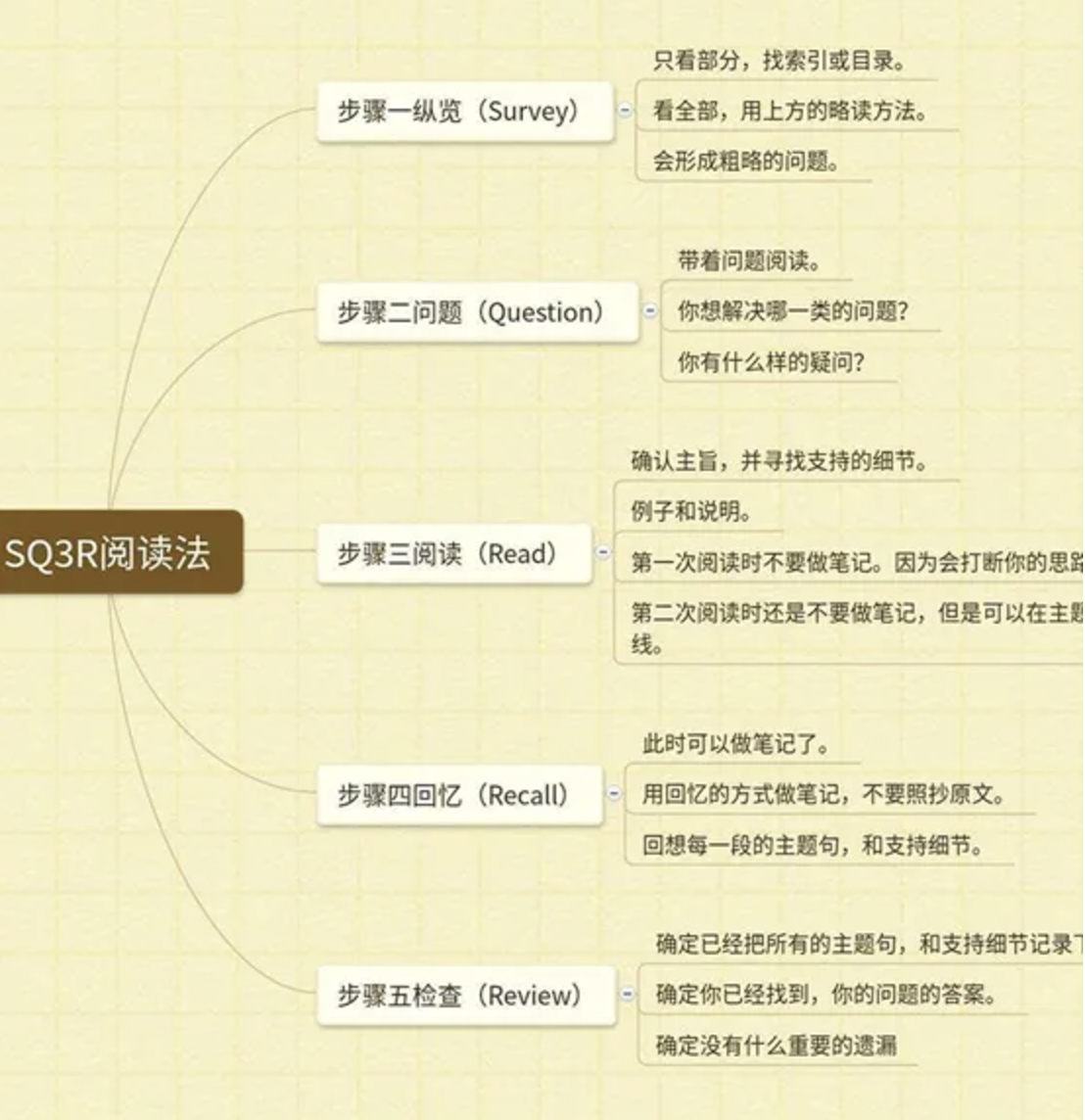
同时阅读笔记很重要,绝对不只是单纯的“ctrl+v”、“ctrl+c”****,没经过思考的笔记,就算记得又臭又长也毫无用处,因为你根本不会去看。
02.
思维清单法
这是逆转你思考方式的方法,对生活工作都特别有帮助。
逻辑性强的人,善于解构任务,化繁为简,剔除无用信息, 能用更短的时间解决更多的事情。
这就是锻炼逻辑思维的好处和目的——替自己和别人省出更多时间,而时间就是金钱。
刚刚毕业时候做公司报告,我很认真写了30-50来张ppt。
结果当天被领导点名批评:废话连篇,乱七八糟,抓不住重点。
最后参考了一个思考顺序清单,通过大量练习,之后每次总结都基本能够得到领导的认可。
这个思维清单中和了「演绎推理法」和「归纳整理法」****,能让你从时间、空间、事情重要程度等方面,进行全方位思考。
你遇到的每个难题,只要按照以下清单顺序考虑,都能迎刃而解,效果真不是吹的,谁用谁知道!
第一步:结论先行
第二步:分析情况
第三步:解决方法
第四步:时间规划
第五步:开始行动
举个应用例子,方便大家理解具体的操作方法:
你是新媒体公司的实习生, 现在要进行转正答辩,怎么有逻辑地表达自己3个月的工作成果?
第一步:结论先行
先把3个月的工作成果展示出来,让领导看到完成值。
这是特别重要的一点!不管报告还是沟通,先说结论能节省所有人的时间。
第二步:分析情况
列出影响数据的分析原因、工作亮点与不足、工作收获等……
这部分要遵循总分总原则,由上到下层层递进,带着“为什么会这样、如何改善”的思维,去剖析出每个问题。
第三步:确定方法
针对所有问题,用归纳法整理出“时间、空间”所有解决的方法、再用演绎法写出,每个能具体实施的方案。
比如:家离公司太远,通勤时间过长,学习时间过少。
时间上:每天提前半小时起床、或在上班途中学习、增大工作密度。
空间上:搬家,缩短空间距离。
第四步:时间规划
这一步,要根据自己的解决方法,和事情的重要程度,列成一个工作规划表:
先做什么、再做什么、之后做什么、最后做什么?
第五步:开始行动
如果不行动,上面所有的逻辑推理都是在纸上谈兵,只会让我们的思维认知停留在原地,毫无长进,所以,行动才是关键啊!
03.
持续积累法
接下来这句话,可能会让你恍然大悟!
其实很多时候,不是因为我们逻辑不好,而是我们的知识存量是有限!了解的事情太少,导致逻辑联系不起来。
想升级自己的逻辑思维,最根本的方法,就是扩大自己的知识储备。
接下来堂主就分享3种提升思维的认知渠道,就算只坚持10天半个月,也有很大的成效!
1. 尝试演讲,形成应激反应
能够参加演讲、辩论类的人,逻辑思维都会比一般人好很多,所以模仿优秀的人,也是很好的提升方法。
长期坚持下来,你就会遇事不慌,面对一切新挑战、繁琐工作,都能迅速上手~
同时,生活中也要抓住一切机会,锻炼自己的表达能力,这里分享2个小细节:
1) 线上工作沟通时,需回复较长信息,可以刻意练习这个回复结构,来表达自己的观点:
第一、第二、第三……
2) 与人沟通时,也同样刻意练习:我有三个方面要说,123……
咳咳,这里我也有三句话要说, 大家注意啦!
第一,能坚持看到这里的同学好优秀!文章快结束了,再坚持坚持哦~
第二,如果喜欢这篇文章的话,记得保存下来,方便以后查看哦~
第三,答应我, 看完去输出个思维导图大纲,这是你提高逻辑思维第一步~
2.看思辨类节目,代入正确角色
这时有人要问了:堂主,我也没少看节目啊,我还是没长进啊。
为什么会这样?
因为你自动代入了观众角色啊,本来正方立场,结果反方一发言,你就觉得:啊好对好对,我怎么没想到!这时正方又把你拽回来:是啊是啊,就是这样!老铁懂我!
一直被别人牵着鼻子走,要是你在现场,估计投票键都会被你摁烂了。
代入选手角色, 选正方,就坚定做正方,选反方,就坚定做反方。
对方一发言,不是想着对对对,而是:不对,他有漏洞,忽略了客观角度,巴拉巴拉。队友发言,也不急着赞同,同样分析他的逻辑表达方式。
吃透这边的论证后,再换个立场训练,你会发现一期节目你得看3456遍,你才能彻底了解辩题的所有角度,客观地表达最正确的想法。
3. 读思辨类书籍,繁殖知识量
这个重要性,就不用我再多说啦,只有看更专业的书籍,才能更全面了解思维模型,废话不多说,直接上推荐书籍。
1)入门书籍,引起你纠正思维的兴趣:

小学生也可以读的启蒙思维书籍,说一个道理搭配几个生活事例, 特别简单粗暴。
很喜欢这句话:人是生而自由的,却无往不在枷锁之中。
完美不枯燥的一本书,书不厚但很耐读,干货特别多,故事很有趣。
从5个方面来帮助你形成自己的方法论:定义问题-分析问题-由谁解决问题-问题来自哪里-如何做一个问题解决者。
2)进阶书籍,系统学习深度思考

前身是《学会提问》,我们最缺的就是批判性思维,这本是入门最佳之选,算是理性“杠精”指南,让你学会理智独立思考,就算说不过别人,也别被别人骗。

读完可以立马用的干货书,书评有句话令人深思:“只要你有批判性思维你就能批判自己的思维”。
最后,送大家两句话,一起共勉:
1、 无论一个问题多么复杂,如果能以正确的方式去看待,它都会变得简单起来。
2、 花半秒钟就看透事物本质的人,和花一辈子都看不清事物本质的人,注定是截然不同的命运。
愿你能养成善于思考的习惯,生活中增加思考频次,慢慢掌握洞察事情本事的能力,点个「在看」,一起成为逻辑大神吧~
免费版本不支持导出excel格式,所以得想办法使用ue版本。
官方安装包下载地址 https://downloads.dbeaver.net/ultimate/23.3.0/dbeaver-ue-23.3.0-macos-x86_64.dmg
链接: https://pan.baidu.com/s/1xWo75x9HiWDyQajGY9TUKw?pwd=a16r 提取码: a16r,下载并解压,放到一个专门的目录,下面会用到
在应用程序里,右键显示包内容,找到dbeaver.ini (/Applications/DBeaverUltimate.app/Contents/Eclipse/dbeaver.ini)
找到 -vm,替换原始java路径,修改如下
1 | -vm |
然后在文件末尾添加如下两行
1 | -Dlm.debug.mode=true |
1 | # dbeaver start |
打开安装好的DBeaver UE,如果闪退或提示已损坏,请自行搜索解决办法。打开后,会提示让你输入注册码,输入下面的注册码即可
1 | aYhAFjjtp3uQZmeLzF3S4H6eTbOgmru0jxYErPCvgmkhkn0D8N2yY6ULK8oT3fnpoEu7GPny7csN |
如无意外,目前应该已经破解成功了。

知乎上有人提问:做个很小众的应用就可以月入数万,为什么多数程序员都不做个人开发?

有个匿名的用户回答的挺好的,详细讲述了自己独立开发软件转起的经历,以下是正文内容:
我要匿名了,因为要说真话了。
我写的其中一个软件(后续以“电脑工具软件”称呼),电脑端的,月入在2.5~3万,规模还在扩大。
先说一下过程吧,提到的各种编程技术对于我后期做成这个小众应用都很重要。
12年毕业,在上海工作两年期间主要工作语言是C语言、RedHat服务器、Oracle数据库、Delphi7、C#的Winform技术,利用加班时间,我简单学过QT技术。
14年7月起,在郑州工作过一年,主要是C语言以及各种网络协议数据抓取、分析审计。
15年清明节,来深圳创业,直到18年7月份因团队变故离开,在此期间我担任公司CTO,学会了Java 、Mysql、Redis、CentOS、微信支付宝支付流程等。
18年到19年清明节前,我去河北,在此期间我学会了android应用开发(原生开发),但是没挣到钱。
19年初,春节过后,闲的,花了10天吧,完成了我要说的这个电脑工具软件软件的第一个版本,尽管很简陋,bug很多。
由于在河北没挣到钱,我又于19年清明节那天,回到了深圳,又加入了原来的那个团队。公司被他 们搞的一团遭,都破产了,我回来后,我们又接了个项目从头开始。
19年特别忙,我也没空再维护我那个软件。对于公司项目,我又学会了开发微信小程序,公众号,uniapp等技术。
20年,做了一个智能软件项目,我又学会了iOS开发(用的是object-c 和 uniapp 混合技术)
到此,根据我的熟练程度。
编程语言我掌握了:Java、JavaScript、C#、Python、Nodejs、go、Html、CSS、c、delphi数据库:mysql、Oracle、MangoDB、Redis
客户端:桌面网页端、Androdi端、windows电脑桌面客户端、iOS应用、微信小程序、公众号
服务器端:宝塔、Java的Springboot系列开发
总的来看,除过Mac上的软件,其它我都开发过,想想,我他妈真是好学。
再仔细想来,我11年就开发过android软件,我应该是中国第一批开发android软件的人。
之所以列举上面这些,是因为这些东西,都对我后来做成这个软件有重要影响。
接着20年继续说,20年后半后没那么忙了,我在周末抽空又把那个 电脑工具软件 翻出来,把bug修复了一下,界面再优化了一下,并加入了 根据电脑设备id号(就是将 cpu、主板、硬盘的序列号组后然后用md5生成的64位编号)校验功能,并在软件上留下了我的微信号,于20年9月份,我将软件发布到小众软件这个网站上了,有好些人夸赞我这个软件很实用,还提到了软件存在的问题。然后我有空,就修复一下,接着发新版本。
然后,有人付款,5块的,10块的,20块钱的,我生成一个证书文件(里面就是一串字母,包含了软件什么时候到期等信息),记得第10月就收到400多元,有一次一个哥们,一开心,直接给我转了300元。真的感谢这个哥们,那时候我穷。
11月份卖了800多元,12月份1600元,好开心,够房租了。此时,我意识到,这个软件能挣大钱。我想把软件上传到360软件管家、腾讯电脑管家的时候,都要一个东西:软著。所以,我就开始写了软著材料,开始申请了。
一个软著从申请到下来,如果不出任何差错,最快也得一个半月。如果出错了,打回来,再提交,又得1个半月。再等给你把纸质的软著寄回来,那还得再等2个月。我前前后后弄了半年才把软著给整下来,软著拿到手已经是21年四五月份了。
21年,由于公司业务遇到瓶颈,公司内部各种矛盾,哎,伤心。
21年,记得是有一次去宝安沙井,我给我伙伴说(公司就3个人),咱把我这个软件好好推推吧,我感觉能挣到不少钱。不过,他们没放到眼里。
然后21年2月份就到2000元,2月份到了3000元,4月月份到了5000元了,5月份6000,到10月已经有1万多了。(这些数据不是真实数据,但量级是一样的,只是为说明每月都增加不少收入,我记得有一个月比前一个月翻倍了)
到了10月底,公司解散了,哎,操蛋。
在21年里,由于忙,我一直都是一边忙公司的事情,周末有空了就维护一下软件的问题,主要是各种闪退,菜单弹不出来,显示出错等,但是功能还是那么简单,UI还是那么的简陋。一边了就在知乎发发帖子,推广我的软件。
11月份,我就搬家了,换了一个稍微大点的房子,本想去找工作的,但想了想,快到年底了,加上 好多公司裁员,工作估计不好找,况且我这个软件有收入,我想投入时间好好再完善一下,然后再去上班。
在此后,我的重点放在以下方面:
以上4点缺一不可,不同阶段,重点不一样而已。
21年的11月、12月到22年的2月,这四项都在做,工作重要内容有:
这三个多月很寂寞,是在家一个人孤独寂寞地在做,我都瘦了好多,因为天天吃挂面和凉拌黄瓜。
22年春节过后,3月份,我和另外一个朋友合租了一个办公室。对,我也没去找工作,此时,我一个月能赚到1.5万了。
从21年的4月份,到22年3月份,我尝试着将价格提高,并分月、季、半年、年、终身等套餐,直到探索到一个 不能再高的价格为止,价格套餐此后再没变过。
到22年3月份,搬到合租的办公室上班。接着以下问题困扰着我:
所以,我就用我朋友的公司,花了半个月,弄了个微信、支付宝支付,再弄个了微信扫码登录功能,于五一前,终于上线了,我整个人都轻松了。
不过,要把钱提出来也是个问题,因为微信支付宝的钱,得先提到 业对公账户,对公账户的钱只能以工资或者其他手段弄出来,那么就得缴纳企业所得税、个税等。
到22年5月份,软件的功能基本上已经全了,bug很少很少了。此时,一个很重要的问题是,如何扩大规模,也就是推广。
我尝试过。
以上6点,只有第5条、第6条、第7条的效果是长远而且行之有效的。
到了22年6月之后,软件终于不用我怎么管了,自行运行,自动收钱,然后躺平了。用户每天在增加,收益变得起来起多。
截止今天,23年6月18号,我都做了八九款电脑端软件了(名字不能在这里说)。
22年初过年开始,花了3个月,做的一个软件,从2022-05-21 15:00:11第一笔收入,到今天,8977个用户,挣了7113元。没推广过,感觉没啥钱途。
22年10月份,做的一个软件,从2022-11-12 11:03:08第一笔收入到现在,348个用户,挣了1738元。这个软件感觉有钱途,打算好好推广一波。
其它好几款软件,也没推广过,软著还没下来,一直放着。估计感觉没没有钱途不好说,真的懒的推广。
乱七八遭的,总结一下吧:
我这个过程,我感觉都是不可复制的,各种尝试后的经验告诉我,如果你开发了一个软件:
一把年纪了,想去找工作,估计也找不到了。我打算 做外贸和其它软件,就这样一个人这样搞下去!
于2023年7月13日 21:40:00 内容补充
浪迹知乎多年,属实不敢相信这种题材的贴子能火,但它就象彩票中大奖的新闻中报道的一样,我第一次随手倍投了十几条经验,它就中了榜一。
1. 为啥文中不提软件名字?
能看这个帖子的,绝大多是程序员,肯定有人会攻击我的服务器,破解我的软件,网上盗版漫天飞。
2. 为啥匿名?
我的其它知乎帖子中,有我的软件介绍,会带来“问题1”的麻烦。
3. 辛苦吗?
这是文中的错觉。在21年10月份,公司解散的时候,我的软件每月就有不少收入了,生活过得去。公司解散后,反而没有那么压力大了,因为没有任务计划逼着我赶进度了。每天都是想把软件做大做强的动力,驱使着我兴致勃勃地干活,相比以前,起得更早了,睡得更晚了,精神头也更好了。在干活时,我也不是一直盯着ide全神心在干活,事实是我一边在刷剧,一边在干活。脑中贯注于代码,大脑易疲惫,电影电视剧是大脑的兴奋催化剂。一年能看大约500多小时的剧,好些剧反复看。
周星驰系列,金庸系列,成龙系列,李保田的《神医喜来乐》《宰相刘罗锅》,张译的《光荣时代》,祁厅长的《人民的名义》,李幼斌的《亮剑》,《大秦帝国》三步曲(第四步不感兴趣)《三国演义》《西游记》《铁齿铜牙纪晓岚》《大明风华》,动物世界相关,动画片《超能勇士》,韩剧《搞笑一家人》
有好剧的,推荐一下,最好是喜剧。
4. 关于吃挂面和凉拌黄瓜
这一段,本没想渲染生活很惨,可意外的是效果如此。原因在于,主食我只会煮挂面和泡面,炒菜只想炒大白菜、小白菜、包菜(清洗方便,切起来顺手,炒时熟的快),凉菜偏好黄瓜(叉板切片,撒盐,倒醋,三步搞定),讲究的是 简单、速度快、省事。
5. 为啥发这个贴子
没火之前,刷了那么多贴子,楞是没嫖到多少有用的经验,或者说分享的内容不太干,看了没多少收获。所以,我想抛砖引玉,如我当天的预测,这个贴子没啥人用。想不到20天后,也就前天(7月11号)晚上有人回贴了,我也用心回了,直到昨天中午我还在认真回贴中。昨天晚上,突然发现点赞、收藏、评论猛增,有点诧异。直到习惯性地刷新了一下热榜,才意识到这贴子上热榜了。
这下,我可真是慌了。本着无私分享,以心换心,换别人经验的态度,贴子和评论的回复中,有些敏感的不谐内容。评论中我就挖啊挖,删啊删。贴子不想删除,因为评论中也有一些有用的信息。读了好几遍贴子,改了好多次。晚上都没睡好。
6. 关于如何联系我
我只是一个很普通的程序员,联系我也没啥用,我只想匿名交流经验。我的网易“易信”app号 “ biexiabibi ”。
7. 是正经软件吗?
文中早早就说了,有软著,在360、腾讯软件管家上有上传,绝对是合法合规的软件。
8. 看知友,觉得很强?
这也是错觉。
我一直都感觉在小打小闹,见识如井底之蛙,好在有自知之明。因为这些经验都是我自己琢磨出来的,始终认为外面有高人,别人做得风生水起,我得多找别人交流。
关于编程,那纯粹是好学,和时间一年一年积累出来的,是螺丝钉的深度,是扳手的技能,造不了航母。
9. 关于UI?
能“致敬”就致敬,能拿来就拿来,当然我也会画UI草图,也会PS。
10. 关于技术框架和服务器负载流量等?
客户端就不说了,用你顺手的做出来就行。服务器很便宜,服务器端都是云,至于配置,你要是感觉客户端卡的时候,你自己分析问题在哪,然后升级配置。对于小众的软件来讲,基本就是验证用户登录会员等信息的,你买最底配置1核1G内存1M带宽就够了,一个月30元吧。
11. 如何判断这个软件是否有前途?
我可以提供一些判断这个软件是否有前途的小建议:
(1) 去各种搜索指数的地方看看相关关键词搜索量,微信搜索指数 抖音搜索指数 微博搜索指数 百度 360 搜狗搜索指数
(2) 去抖音 快手 小红书 微信搜索 百度360搜狗 知乎 微博 豆瓣 等去搜一下相关内容,各种关键词,反复试探搜索
(3) qq群,看看有没有相关群
(4) 看看同行的产品,加他们的qq群,打探敌情;去应用商店看评论,看看用户的评价。
(5) 发抖音,发朋友圈调研,看看大家的评论
(6) 发抖音,发朋友圈,假装你已经开发好了,需要的私信,看看大家的咨询购买意愿。花点钱,推一推。
(7) 一个软件要做成的环节很多,别人没做成功不代表你不可以做。有的人可能技术不行,有的人做出来的功能不全,或者没做到用户最重要的点上,有的人压根就没推广。我意思是,别人做过的,你也可以做。
(8) 有时候也可以蹭风口,比如现在流行的chatgpt,整一堆账号,搭建个代理,然后使劲在抖音打广告。赚一波就走。
(9) 做完以上,就到了你自己 做决定的时候了(至于怎么做,我也有点模糊),你凭感觉吧,哈哈。
至于怎么做决定,大的讲,就三点:你能做出来吗?你能营销卖出去吗?投入成本和获得的收益值得去做吗?
12. 做成免费软件然后用广告收费靠谱吗?
能收费就收费,否则就上广告,广告和收费你也可以一块上。至于怎么弄,这得综合考虑。因素有:竞争对手有没有,竞争对手的产品如何,竞争对手推广的好不好,目标用户的消费能力如何,目标用户对这个产品使用习惯,以及你的运营成本。
(1) 如果没竞争对手,或者别人都找不到竞争对手的产品,那就就收费,可劲提高收费,因为你相当于垄断。至于定价多少,小学六年级我们就学过餐厅菜定价问题。经观察,价格和顾客数量有一个线性关系,求定价多少,才能使利润最大化。
(2) 如果你有竞争对手,对手很牛,营销也很好,那么对手收费的,那你就比他便宜,或者免费。
总之,你一定要比别人有至少一个点的优势,如价格优势,或者 某个特有功能优势。
13. 脑袋空空的,没啥好创意,找不到感觉?
(1)去 小众应用 网站,360 腾讯软件管家,国外下载站,mac apple android 等应用网站多看看
(2)多用百度 微信 抖音 等搜索指数 看看一些关键词的搜索量
(3)多看广告,尤其抖音 百度 上的人家持续推广的软件相关的广告(重点)
(4)去看看一些任务外包平台,别人的小需求,可能蕴藏着大商机(重点)
(5)多看看别人在运营的软件,多琢磨它的盈利点,以及运营手段
(6)别人做过的,你也可以做,重点是 运营(重点)
多看多琢磨,积累素材,慢慢就有感觉了,能感觉哪些可以做,哪些不可以做。如果你不看不琢磨,脑袋空空,一点素材都没有,大脑如何联想、如何想象,如何迸发灵感,脑袋怎么可能有感觉了!≠
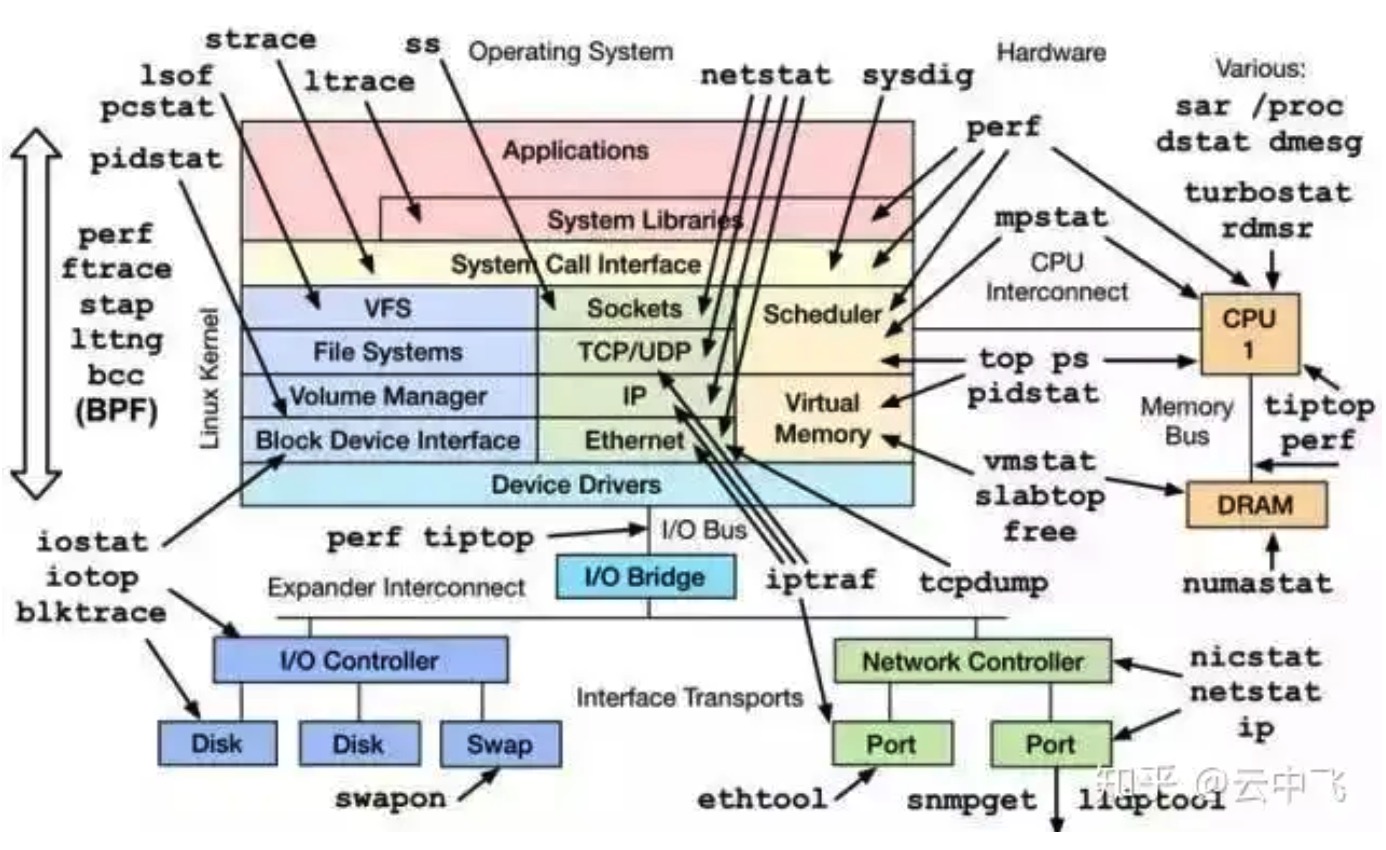
一个基于 Linux 操作系统的服务器运行的同时,也会表征出各种各样参数信息。通常来说运维人员、系统管理员会对这些数据会极为敏感,但是这些参数对于开发者来说也十分重要,尤其当你的程序非正常工作的时候,这些蛛丝马迹往往会帮助快速定位跟踪问题。这里只是一些简单的工具查看系统的相关参数,当然很多工具也是通过分析加工 /proc、/sys 下的数据来工作的,而那些更加细致、专业的性能监测和调优,可能还需要更加专业的工具(perf、systemtap 等)和技术才能完成哦。毕竟来说,系统性能监控本身就是个大学问。
➜ ~ top
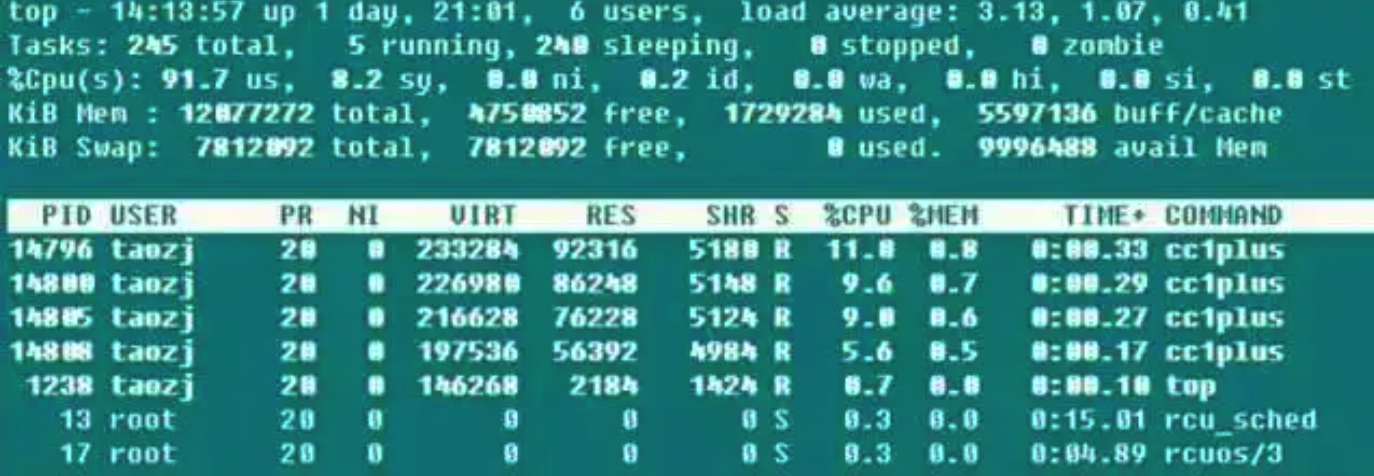
第一行后面的三个值是系统在之前 1、5、15 的平均负载,也可以看出系统负载是上升、平稳、下降的趋势,当这个值超过 CPU 可执行单元的数目,则表示 CPU 的性能已经饱和成为瓶颈了。
第二行统计了系统的任务状态信息。running 很自然不必多说,包括正在 CPU 上运行的和将要被调度运行的;sleeping 通常是等待事件(比如 IO 操作)完成的任务,细分可以包括 interruptible 和 uninterruptible 的类型;stopped 是一些被暂停的任务,通常发送 SIGSTOP 或者对一个前台任务操作 Ctrl-Z 可以将其暂停;zombie 僵尸任务,虽然进程终止资源会被自动回收,但是含有退出任务的 task descriptor 需要父进程访问后才能释放,这种进程显示为 defunct 状态,无论是因为父进程提前退出还是未 wait 调用,出现这种进程都应该格外注意程序是否设计有误。
第三行 CPU 占用率根据类型有以下几种情况:
√ (us) user:CPU 在低 nice 值(高优先级)用户态所占用的时间(nice<=0)。正常情况下只要服务器不是很闲,那么大部分的 CPU 时间应该都在此执行这类程序
√ (sy) system:CPU 处于内核态所占用的时间,操作系统通过系统调用(system call)从用户态陷入内核态,以执行特定的服务;通常情况下该值会比较小,但是当服务器执行的 IO 比较密集的时候,该值会比较大
√ (ni) nice:CPU 在高 nice 值(低优先级)用户态以低优先级运行占用的时间(nice>0)。默认新启动的进程 nice=0,是不会计入这里的,除非手动通过 renice 或者 setpriority() 的方式修改程序的nice值
√ (id) idle:CPU 在空闲状态(执行 kernel idle handler )所占用的时间
√ (wa) iowait:等待 IO 完成做占用的时间
√ (hi) irq:系统处理硬件中断所消耗的时间
√ (si) softirq:系统处理软中断所消耗的时间,记住软中断分为 softirqs、tasklets (其实是前者的特例)、work queues,不知道这里是统计的是哪些的时间,毕竟 work queues 的执行已经不是中断上下文了
√ (st) steal:在虚拟机情况下才有意义,因为虚拟机下 CPU 也是共享物理 CPU 的,所以这段时间表明虚拟机等待 hypervisor 调度 CPU 的时间,也意味着这段时间 hypervisor 将 CPU 调度给别的 CPU 执行,这个时段的 CPU 资源被“stolen”了。这个值在我 KVM 的 VPS 机器上是不为 0 的,但也只有 0.1 这个数量级,是不是可以用来判断 VPS 超售的情况?
CPU 占用率高很多情况下意味着一些东西,这也给服务器 CPU 使用率过高情况下指明了相应地排查思路:
√ 当 user 占用率过高的时候,通常是某些个别的进程占用了大量的 CPU,这时候很容易通过 top 找到该程序;此时如果怀疑程序异常,可以通过 perf 等思路找出热点调用函数来进一步排查;
√ 当 system 占用率过高的时候,如果 IO 操作(包括终端 IO)比较多,可能会造成这部分的 CPU 占用率高,比如在 file server、database server 等类型的服务器上,否则(比如>20%)很可能有些部分的内核、驱动模块有问题;
√ 当 nice 占用率过高的时候,通常是有意行为,当进程的发起者知道某些进程占用较高的 CPU,会设置其 nice 值确保不会淹没其他进程对 CPU 的使用请求;
√ 当 iowait 占用率过高的时候,通常意味着某些程序的 IO 操作效率很低,或者 IO 对应设备的性能很低以至于读写操作需要很长的时间来完成;
√ 当 irq/softirq 占用率过高的时候,很可能某些外设出现问题,导致产生大量的irq请求,这时候通过检查 /proc/interrupts 文件来深究问题所在;
√ 当 steal 占用率过高的时候,黑心厂商虚拟机超售了吧!
第四行和第五行是物理内存和虚拟内存(交换分区)的信息:
total = free + used + buff/cache,现在buffers和cached Mem信息总和到一起了,但是buffers和cached Mem 的关系很多地方都没说清楚。其实通过对比数据,这两个值就是 /proc/meminfo 中的 Buffers 和 Cached 字段:Buffers 是针对 raw disk 的块缓存,主要是以 raw block 的方式缓存文件系统的元数据(比如超级块信息等),这个值一般比较小(20M左右);而 Cached 是针对于某些具体的文件进行读缓存,以增加文件的访问效率而使用的,可以说是用于文件系统中文件缓存使用。
而 avail Mem 是一个新的参数值,用于指示在不进行交换的情况下,可以给新开启的程序多少内存空间,大致和 free + buff/cached 相当,而这也印证了上面的说法,free + buffers + cached Mem才是真正可用的物理内存。并且,使用交换分区不见得是坏事情,所以交换分区使用率不是什么严重的参数,但是频繁的 swap in/out 就不是好事情了,这种情况需要注意,通常表示物理内存紧缺的情况。
最后是每个程序的资源占用列表,其中 CPU 的使用率是所有 CPU core 占用率的总和。通常执行 top 的时候,本身该程序会大量的读取 /proc 操作,所以基本该 top 程序本身也会是名列前茅的。
top 虽然非常强大,但是通常用于控制台实时监测系统信息,不适合长时间(几天、几个月)监测系统的负载信息,同时对于短命的进程也会遗漏无法给出统计信息。
vmstat 是除 top 之外另一个常用的系统检测工具,下面截图是我用-j4编译boost的系统负载。

r 表示可运行进程数目,数据大致相符;而b表示的是 uninterruptible 睡眠的进程数目;swpd 表示使用到的虚拟内存数量,跟 top-Swap-used 的数值是一个含义,而如手册所说,通常情况下 buffers 数目要比 cached Mem 小的多,buffers 一般20M这么个数量级;io 域的 bi、bo 表明每秒钟向磁盘接收和发送的块数目(blocks/s);system 域的 in 表明每秒钟的系统中断数(包括时钟中断),cs表明因为进程切换导致上下文切换的数目。
说到这里,想到以前很多人纠结编译 linux kernel 的时候 -j 参数究竟是 CPU Core 还是 CPU Core+1?通过上面修改 -j 参数值编译 boost 和 linux kernel 的同时开启 vmstat 监控,发现两种情况下 context switch 基本没有变化,且也只有显著增加 -j 值后 context switch 才会有显著的增加,看来不必过于纠结这个参数了,虽然具体编译时间长度我还没有测试。资料说如果不是在系统启动或者 benchmark 的状态,参数 context switch>100000 程序肯定有问题。
如果想对某个进程进行全面具体的追踪,没有什么比 pidstat 更合适的了——栈空间、缺页情况、主被动切换等信息尽收眼底。这个命令最有用的参数是-t,可以将进程中各个线程的详细信息罗列出来。
-r:显示缺页错误和内存使用状况,缺页错误是程序需要访问映射在虚拟内存空间中但是还尚未被加载到物理内存中的一个分页,缺页错误两个主要类型是
√ minflt/s 指的 minor faults,当需要访问的物理页面因为某些原因(比如共享页面、缓存机制等)已经存在于物理内存中了,只是在当前进程的页表中没有引用,MMU 只需要设置对应的 entry 就可以了,这个代价是相当小的
√ majflt/s 指的 major faults,MMU 需要在当前可用物理内存中申请一块空闲的物理页面(如果没有可用的空闲页面,则需要将别的物理页面切换到交换空间去以释放得到空闲物理页面),然后从外部加载数据到该物理页面中,并设置好对应的 entry,这个代价是相当高的,和前者有几个数据级的差异
-s:栈使用状况,包括 StkSize 为线程保留的栈空间,以及 StkRef 实际使用的栈空间。使用ulimit -s发现CentOS 6.x上面默认栈空间是10240K,而 CentOS 7.x、Ubuntu系列默认栈空间大小为8196K

-u:CPU使用率情况,参数同前面类似
-w:线程上下文切换的数目,还细分为cswch/s因为等待资源等因素导致的主动切换,以及nvcswch/s线程CPU时间导致的被动切换的统计
如果每次都先ps得到程序的pid后再操作pidstat会显得很麻烦,所以这个杀手锏的-C可以指定某个字符串,然后Command中如果包含这个字符串,那么该程序的信息就会被打印统计出来,-l可以显示完整的程序名和参数
➜ ~ pidstat -w -t -C “ailaw” -l
这么看来,如果查看单个尤其是多线程的任务时候,pidstat比常用的ps更好使!
当需要单独监测单个 CPU 情况的时候,除了 htop 还可以使用 mpstat,查看在 SMP 处理器上各个 Core 的工作量是否负载均衡,是否有某些热点线程占用 Core。
➜ ~ mpstat -P ALL 1
如果想直接监测某个进程占用的资源,既可以使用top -u taozj的方式过滤掉其他用户无关进程,也可以采用下面的方式进行选择,ps命令可以自定义需要打印的条目信息:
while :; do ps -eo user,pid,ni,pri,pcpu,psr,comm | grep ‘ailawd’; sleep 1; done
如想理清继承关系,下面一个常用的参数可以用于显示进程树结构,显示效果比pstree详细美观的多
➜ ~ ps axjf
iotop 可以直观的显示各个进程、线程的磁盘读取实时速率;lsof 不仅可以显示普通文件的打开信息(使用者),还可以操作 /dev/sda1 这类设备文件的打开信息,那么比如当分区无法 umount 的时候,就可以通过 lsof 找出磁盘该分区的使用状态了,而且添加 +fg 参数还可以额外显示文件打开 flag 标记。
2.1 iostat
➜ ~ iostat -xz 1
其实无论使用 iostat -xz 1 还是使用 sar -d 1,对于磁盘重要的参数是:
√ avgqu-s:发送给设备 I/O 请求的等待队列平均长度,对于单个磁盘如果值>1表明设备饱和,对于多个磁盘阵列的逻辑磁盘情况除外
√ await(r_await、w_await):平均每次设备 I/O 请求操作的等待时间(ms),包含请求排列在队列中和被服务的时间之和;
√ svctm:发送给设备 I/O 请求的平均服务时间(ms),如果 svctm 与 await 很接近,表示几乎没有 I/O 等待,磁盘性能很好,否则磁盘队列等待时间较长,磁盘响应较差;
√ %util:设备的使用率,表明每秒中用于 I/O 工作时间的占比,单个磁盘当 %util>60% 的时候性能就会下降(体现在 await 也会增加),当接近100%时候就设备饱和了,但对于有多个磁盘阵列的逻辑磁盘情况除外;
还有,虽然监测到的磁盘性能比较差,但是不一定会对应用程序的响应造成影响,内核通常使用 I/O asynchronously 技术,使用读写缓存技术来改善性能,不过这又跟上面的物理内存的限制相制约了。
上面的这些参数,对网络文件系统也是受用的。
网络性能对于服务器的重要性不言而喻,工具 iptraf 可以直观的现实网卡的收发速度信息,比较的简洁方便通过 sar -n DEV 1 也可以得到类似的吞吐量信息,而网卡都标配了最大速率信息,比如百兆网卡千兆网卡,很容易查看设备的利用率。
通常,网卡的传输速率并不是网络开发中最为关切的,而是针对特定的 UDP、TCP 连接的丢包率、重传率,以及网络延时等信息。
➜ ~ netstat -s
显示自从系统启动以来,各个协议的总体数据信息。虽然参数信息比较丰富有用,但是累计值,除非两次运行做差才能得出当前系统的网络状态信息,亦或者使用 watch 眼睛直观其数值变化趋势。所以netstat通常用来检测端口和连接信息的:
netstat –all(a) –numeric(n) –tcp(t) –udp(u) –timers(o) –listening(l) –program(p)
–timers可以取消域名反向查询,加快显示速度;比较常用的有
➜ ~ netstat -antp #列出所有TCP的连接
➜ ~ netstat -nltp #列出本地所有TCP侦听套接字,不要加-a参数
sar 这个工具太强大了,什么 CPU、磁盘、页面交换啥都管,这里使用 -n 主要用来分析网络活动,虽然网络中它还给细分了 NFS、IP、ICMP、SOCK 等各种层次各种协议的数据信息,我们只关心 TCP 和 UDP。下面的命令除了显示常规情况下段、数据报的收发情况,还包括
TCP
➜ ~ sudo sar -n TCP,ETCP 1
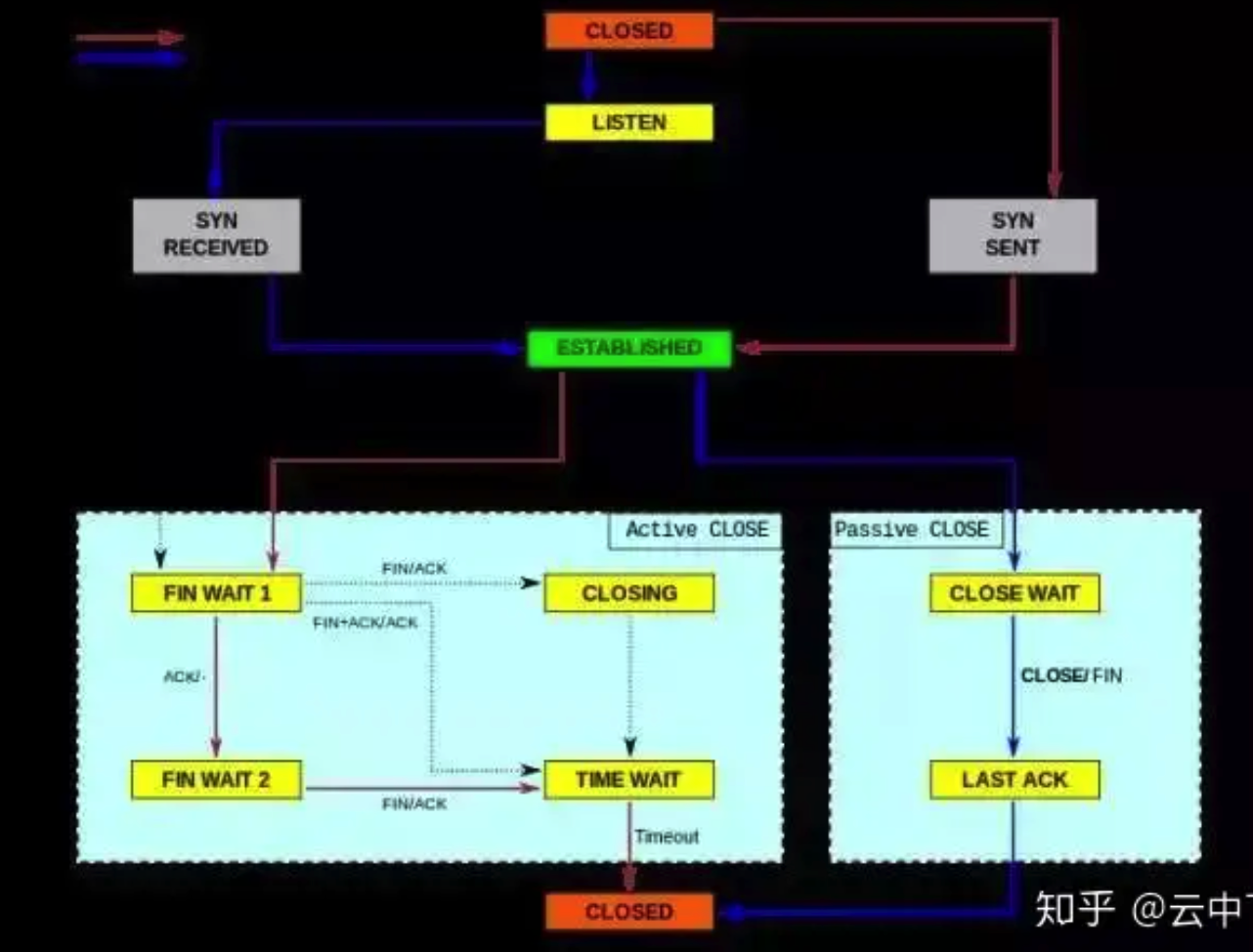
√ active/s:本地发起的 TCP 连接,比如通过 connect(),TCP 的状态从CLOSED -> SYN-SENT
√ passive/s:由远程发起的 TCP 连接,比如通过 accept(),TCP 的状态从LISTEN -> SYN-RCVD
√ retrans/s(tcpRetransSegs):每秒钟 TCP 重传数目,通常在网络质量差,或者服务器过载后丢包的情况下,根据 TCP 的确认重传机制会发生重传操作
√ isegerr/s(tcpInErrs):每秒钟接收到出错的数据包(比如 checksum 失败)
UDP
➜ ~ sudo sar -n UDP 1
√ noport/s(udpNoPorts):每秒钟接收到的但是却没有应用程序在指定目的端口的数据报个数
√ idgmerr/s(udpInErrors):除了上面原因之外的本机接收到但却无法派发的数据报个数
当然,这些数据一定程度上可以说明网络可靠性,但也只有同具体的业务需求场景结合起来才具有意义。
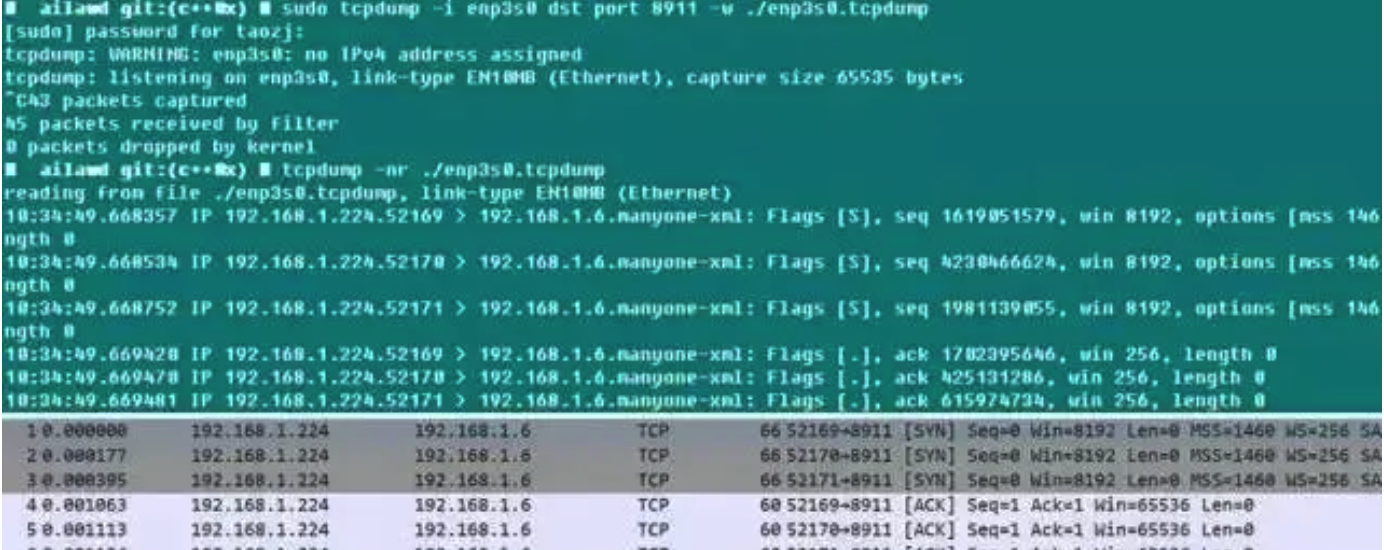
tcpdump 不得不说是个好东西。大家都知道本地调试的时候喜欢使用 wireshark,但是线上服务端出现问题怎么弄呢?
附录的参考文献给出了思路:复原环境,使用 tcpdump 进行抓包,当问题复现(比如日志显示或者某个状态显现)的时候,就可以结束抓包了,而且 tcpdump 本身带有 -C/-W 参数,可以限制抓取包存储文件的大小,当达到这个这个限制的时候保存的包数据自动 rotate,所以抓包数量总体还是可控的。此后将数据包拿下线来,用 wireshark 想怎么看就怎么看,岂不乐哉!tcpdump 虽然没有 GUI 界面,但是抓包的功能丝毫不弱,可以指定网卡、主机、端口、协议等各项过滤参数,抓下来的包完整又带有时间戳,所以线上程序的数据包分析也可以这么简单。
下面就是一个小的测试,可见 Chrome 启动时候自动向 Webserver 发起建立了三条连接,由于这里限制了 dst port 参数,所以服务端的应答包被过滤掉了,拿下来用 wireshark 打开,SYNC、ACK 建立连接的过程还是很明显的!在使用 tcpdump 的时候,需要尽可能的配置抓取的过滤条件,一方面便于接下来的分析,二则 tcpdump 开启后对网卡和系统的性能会有影响,进而会影响到在线业务的性能。
欢迎大家一起学习交流
下文提供 ZFile 镜像构建过程,供大家参考。
1 | FROM ibm-semeru-runtimes:open-8-jre |
FROM ibm-semeru-runtimes:open-8-jre 表示使用的基础镜像,这里选中的这个是 ibm 的 openj9 jdk8 版本的 jre,这个版本的 jdk 具有内存占用小,启动速度快等优势,且针对 docker环境做过特殊优化。WORKDIR /root 表示工作目录在 /root,下方所有命令将在这个目录下执行RUN ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime 和 RUN echo 'Asia/Shanghai' >/etc/timezone 表示设置时区为上海时间,这两个设置的区别参考:https://unix.stackexchange.com/questions/384971/whats-the-difference-between-localtime-and-timezone-filesRUN curl -o app.jar https://c.jun6.net/ZFILE/zfile-release.jar 表示下载 zfile 最新版 jar 包,并命名为 app.jar,因为上方工作目录为 /root,所以实际下载到了 /root/app.jarEXPOSE 8080 表示容器可能会使用这个端口,这个只是声明或备注式的,不会实际影响端口情况。ENTRYPOINT java $JAVA_OPTS -Xshareclasses -Xquickstart -jar /root/app.jar 表示启动 /root/app.jar,其中 -Xshareclasses -Xquickstart 是 ibm 的 openj9 jvm 的参数,用来优化内存占用。由于需要同时支持 arm64 架构和 amd64 架构,所以使用的 docker 的 多平台构建,即同时 build 多个架构的镜像。
Docker 默认的 builder 实例不支持同时指定多个 --platform,我们必须首先创建一个新的 builder 实例。1 | docker buildx create --name zfile-builder --driver docker-container |
builder 实例1 | docker buildx use zfile-builder |
builder 支持构建的架构类型1 | docker buildx ls |
1 | docker run --privileged --rm tonistiigi/binfmt --install all |
Dockerfile 所在目录执行构建命令并 push 到 docker hub (需提前 docker login 账号)1 | docker buildx build --platform linux/arm64,linux/amd64 -t zhaojun1998/zfile:latest --push . |
然后在 docker hub 就可以看到推送的镜像了。
[
后续还会更新如何使用 CI 工具自动化构建镜像的方式。
{kind=link}
{kind=link}